Summary: Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
目录
本博客使用
o3翻译,如有冲突请优先参考英文原文
0. Materials
1. What is the paper about?
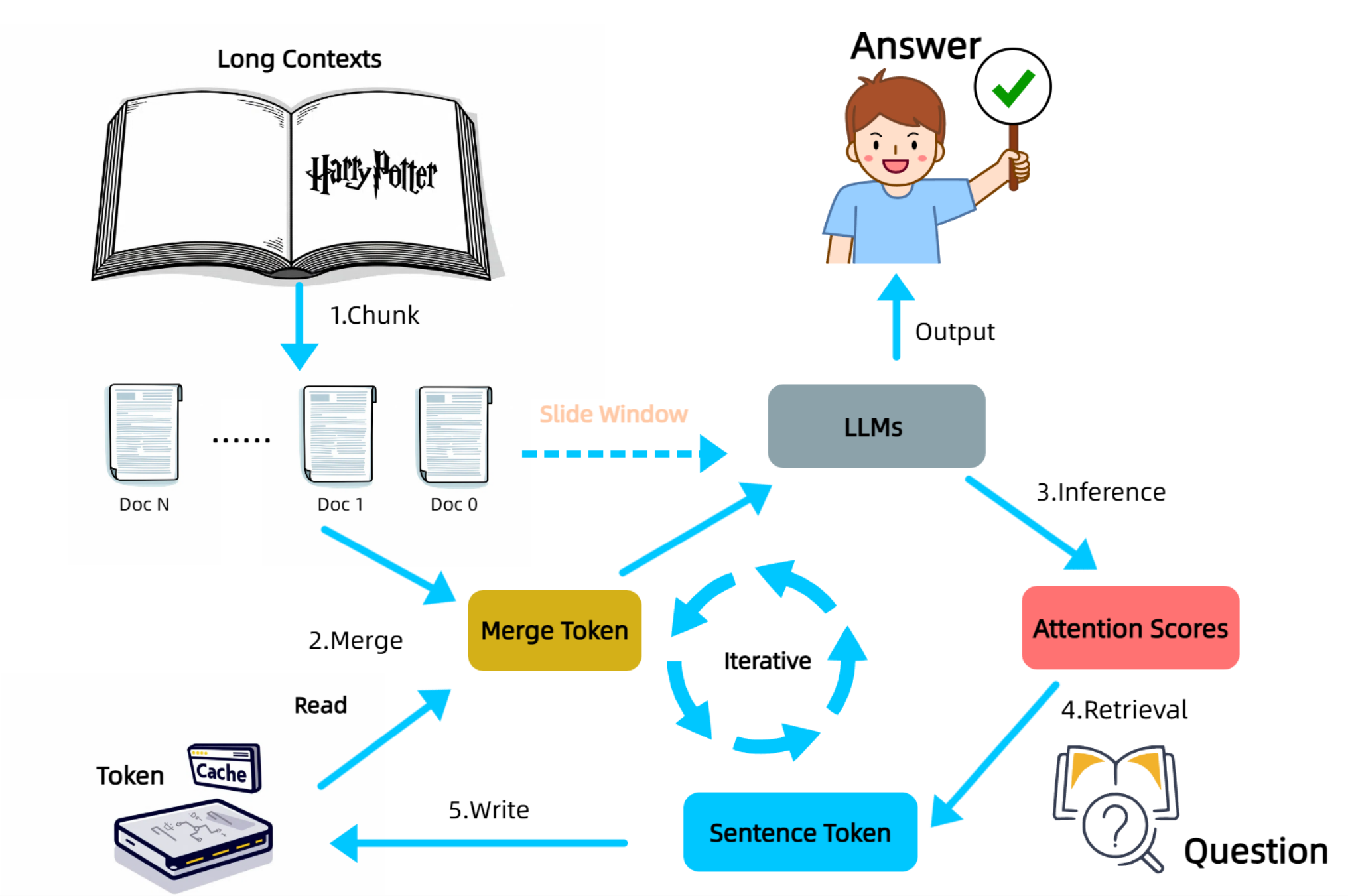
- 提出了 InfiniRetri,一个无需训练的框架,通过将模型自身的 attention 分数 视为检索信号,使任何 Transformer LLM 具备“无限”上下文长度。
- 工作流程:将长文本拆分为块 → 输入:块 + 之前缓存的句子 → 读取 最后一层 注意力 → 对短语(一维卷积而非单个 token)打分 → 缓存包含 Top-K token 的句子 → 滑动到下一个块。
- 使用 0.5 B 规模的 LLM 在 1 M-token 输入的 NIH 任务中达到 100 % 准确率,并在 LongBench QA 任务 上取得显著提升,同时将推理 token 数量减少约 90–95 %。
2. What is new compared to prior work?
- 早期的 KV 压缩工作(SnapKV、H₂O、PyramidKV、DynamicKV、CAKE 等)虽然观察到注意力模式,但仍存储 KV 向量;InfiniRetri 用 句子级 token ID 完全取代了 KV 存储。
- 缓存完整句子(语义单元),而非单个 token 或向量,在保持轻量的同时保留上下文。
- 相较于需要单独嵌入模型的 RAG 或保留 “attention sinks” KV 的 StreamingLLM,InfiniRetri 不需要额外模块,并丢弃所有 KV 张量。
- 首个在标准长上下文基准上同时超越 Full-KV 准确率并使用更少内存的方法。
3. What experiments were run to support the arguments in this paper?
- NIH:将准确检索长度从 32 K 扩展到 1 M token,并击败 StreamingLLM、SnapKV、PyramidKV 等方法。
- LongBench V1(9 项任务):与 Full-KV、StreamingLLM、H₂O、SnapKV、PyramidKV、DynamicKV、CAKE 对比;在三种开源模型上,InfiniRetri 是唯一全面超越 Full-KV 的方法,在 HotpotQA 上提升高达 +288 %。
- LongBench V2:Qwen 2.5-7B + InfiniRetri 的整体得分与 72 B 模型持平,尤其在 Long 样本上表现突出。
- 显示平均保留 token 降至约 4.5 %(例如 NrtvQA 从 18 k 降至 834),同时准确率上升。
- 消融实验:将句子 ID 缓存换回 past-KV 缓存,QA F1 下降 10–15 点,证明 token-ID 缓存是关键。
4. What are the shortcomings/limitations of this paper?
- 在 LongBench 的摘要数据集(GovReport、MultiNews)上提升有限,因为摘要需要整体上下文而非稀疏线索。
- 表现依赖超参数(块大小、短语宽度 k、Top-K);参数不佳会影响召回。
- 依赖 句子边界;噪声文本或代码可能破坏“句子 = 最小语义单元”的假设。
- 目前仅支持 纯文本;多模态长上下文任务(图像、视频)尚未探索。
- 成功主要为经验性,缺乏关于召回率与块超参数关系的正式理论保证。
5. What is a reasonable next step to build upon this paper?
- 集成轻量级在线抽象摘要器,对未被选中的块进行压缩,以支持需要全局信息的任务。
- 自动 根据任务或输入分布调节块大小和 Top-K,以平衡召回率与延迟。
- 将 “注意力检索 + 句子缓存” 思路迁移到视觉-语言模型(例如长视频或带图 PDF)。
Appendix
- StreamingLLM:一个免训练的“滑窗”解码器,仅保留首尾 KV(“attention sinks”),使模型可生成任意长度文本
- SnapKV:依据注意力分值丢弃低分 KV,以降低解码时显存占用
- H2O (Heavy-Hitter Oracle):在每层 KV 缓存中保留最受关注的 “重击者” token 以及小型最近缓冲区
- PyramidKV:以金字塔策略为低层分配更多 KV 预算,高层较少
- DynamicKV / ZigZagKV:根据层的不确定性或任务需求,动态调整 KV 保留量
- CAKE (Computation and Network Aware KV Cache loader):通过并行加载或重算 KV 来掩盖 GPU/CPU I/O 延迟
- InfiniPot:两阶段 KV 驱逐 + Top-K 稀疏注意力,在固定内存内处理无限上下文
- DuoAttention:将注意力头拆分为 “检索头”(保留全 KV)与 “流式头”(窗口化),从而减半内存
- SelfExtend:在推理时插入分组和邻域注意力块,无需微调即可外推上下文
- TransformerFAM:构建反馈环,使隐藏状态成为长期工作记忆
- LongLoRA:使用参数高效的 LoRA 微调,以经济方式扩展上下文长度
- Needle-in-a-Haystack (NIH):在巨型文档中隐藏一句 “针” 并要求模型精确检索的压力测试
- LongBench V1 / V2:输入长度 1 K–30 K+ 的双语多任务长文本基准(QA、摘要等)。
- HotpotQA:含 11.3 万条多跳维基问答,需要组合两段证据作答
- YaRN:在继续预训练中调整 RoPE 基频以将上下文扩展到 128 K–1 M 的方法
- Mistral-7B:采用 grouped-query attention 的 7 B 模型,默认窗口 32 K