Summary: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
目录
本博客使用
o3翻译,如有冲突请优先参考英文原文
0. Materials
1. 论文的内容是什么?
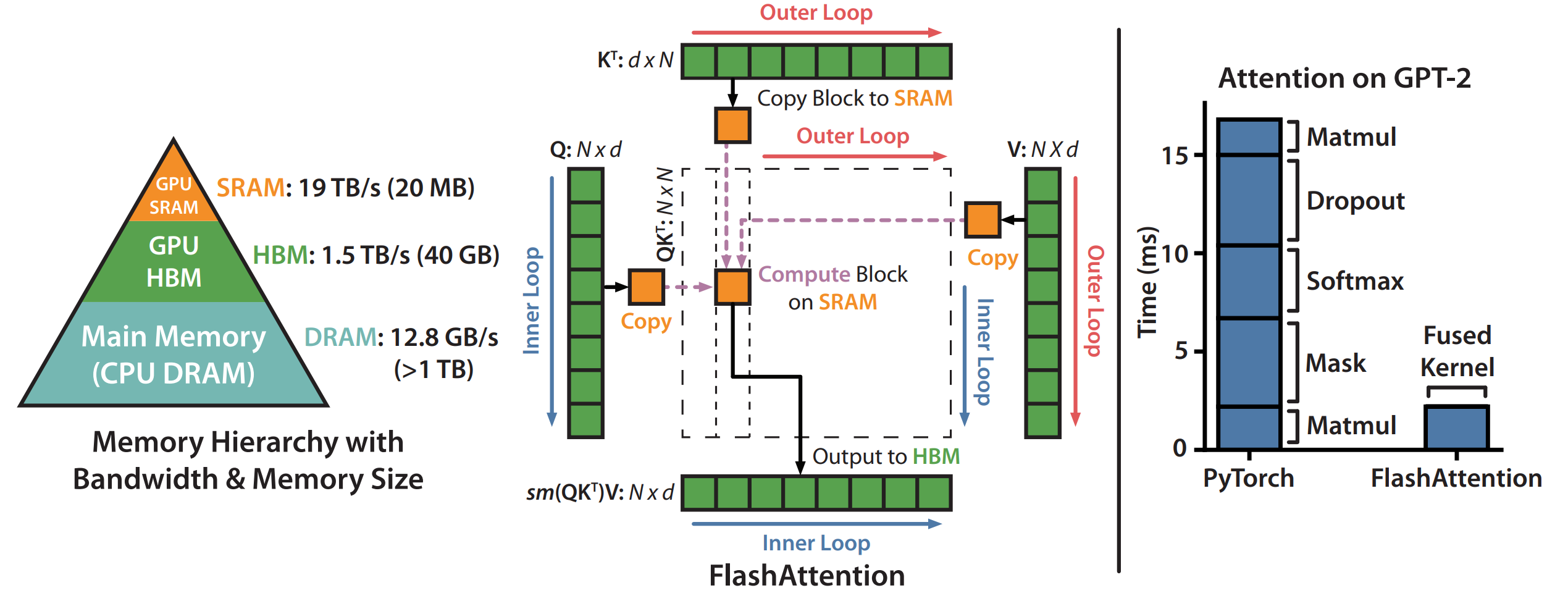
- FlashAttention 提出了一种 IO-aware 的精确自注意力算法:把
Q、K、V张量切分成可缓存的子块,使得任何中间N×N结果矩阵都永不离开 GPU 片上 SRAM(共享内存),从而极大减少对 HBM(高带宽显存) 的读写。 - 记忆占用随序列长度线性增长,且在保持完全精确结果的同时,实现了显著的端到端加速(内核加速最高 7.6 ×,整体训练加速 3 ×)。
- 同一思路可扩展到 Block-Sparse FlashAttention,在超长序列(最多 64 K token)场景下再带来 ≈ 2–4 × 额外速度提升。
2. 相比以往工作的新贡献
- 不再只关注 FLOPs,而是把HBM 流量作为第一优化对象,弥补了此前许多近似注意力“省算力不省时间”的空缺。
- 证明了 IO 复杂度
O(N² · d² / M),并给出在单卡固定 SRAM 容量M下的信息论最优性。 - 将
matmul+mask+softmax+dropout+matmul一次性融合进单内核,消除了大量 kernel-launch 与显存往返开销。 - 反向传播仅保存
O(N)级统计信息,用少量额外 FLOPs 换来巨大的显存节省。 - 提出的块稀疏版本在所有测试长度上同时超越现有稀疏/近似注意力的速度与内存表现。
3. 实验如何支撑论点?
A100 单核基准:较 PyTorch 标准注意力 7.6 × 加速,HBM 流量减少 9 ×(图 2)。
端到端训练
- BERT-large:MLPerf 目标在 17.4 min 内完成,比 Nvidia 记录再快 15 %。
- GPT-2 small/medium(OpenWebText):比 HuggingFace 3.5 ×,比 Megatron-LM 1.7–1.8 × 更快,困惑度相同。
- Long-Range Arena(1 K–4 K token):整体 2.4 × 加速;块稀疏版可达 2.8 ×,准确率不降。
长上下文建模
- GPT-2 4 K 上下文:训练速度 +30 %,困惑度再降 0.7。
- 长文分类(MIMIC-III、ECtHR):在 16 K token 时 F1 最高提升 8.5。
- Path-X / Path-256 迷宫任务:首次 Transformer 超越随机 —— Dense FA 61.4 %,Block-Sparse 63.1 %。
图 3 提供全面的运行时间 & 显存曲线,对比 PyTorch、Megatron、Linformer、OpenAI Sparse 等基线。
4. 局限与不足
- 每种变体都需手写 CUDA 内核,对未来 GPU 架构的可移植性有限。
- 只在单 GPU 中最优,尚未显式建模多卡训练中的跨卡通讯流量。
- 优化 focus 在 Attention 层,诸如 MLP、LayerNorm、优化器状态等其他内存瓶颈仍待处理。
- 计算复杂度依旧是
O(N²),IO 虽减但算量未降。 - 块大小基于经验,需要针对不同 SRAM 容量或新硬件重新调参。
5. 可行的后续工作
- 构建 高层 IO-aware 编译器:自动把 PyTorch 级 Attention 描述降到优化 CUDA,类似 Halide 之于图像。
- 将 IO 感知设计推广到 MLP、LayerNorm、优化器等层面,推动整模型显存流量向线性逼近。
- 多 GPU / 异构系统:联动优化 SRAM、HBM 及 NVLink / PCIe 通讯,兼顾分布式训练。
- 自适应分块:运行时根据实际 SRAM 占用自动选择最优 tile 大小。
- 深入挖掘 H100 Tensor Core 并结合稀疏或低秩技巧,实现进一步收益。
附录(名词解释)
MLPerf —— MLCommons 每半年发布一次的机器学习训练 / 推理基准。
OpenWebText —— Reddit 高分链接复刻 OpenAI WebText 语料,用于 GPT-2 训练。
MIMIC-III —— 4 万余名 ICU 患者的去标识临床数据库,临床 NLP 常用。
ECtHR 数据集 —— 欧洲人权法院判决文本,做法律推理与多标签分类。
Long-Range Arena (LRA) —— Google Research 提出的长序列效率基准(1 K–64 K token)。
- Path-X —— 把 128×128 二值图像逐像素展开(≈ 16 K token),预测两点是否连通。
- Path-256 —— 256×256 更长版本(≈ 64 K token),难度更高。
Linformer —— 通过把 K/V 投影到低秩空间,将注意力复杂度从
O(N²)降到O(N)。Performer —— 利用随机特征逼近 softmax 注意力,同样取得线性复杂度。
Reformer —— 结合 LSH Attention (
O(N log N)) 和可逆残差网络,降低显存需求。SMYRF —— 基于非对称聚类的稀疏注意力,可无须重新训练插入已有模型。
Apex FMHA —— NVIDIA Apex 内核,融合 matmul+softmax 提速标准注意力。