Summary: EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
目录
本博客使用
o3翻译,如有冲突请优先参考英文原文
0. Materials
1. 论文讲了什么?
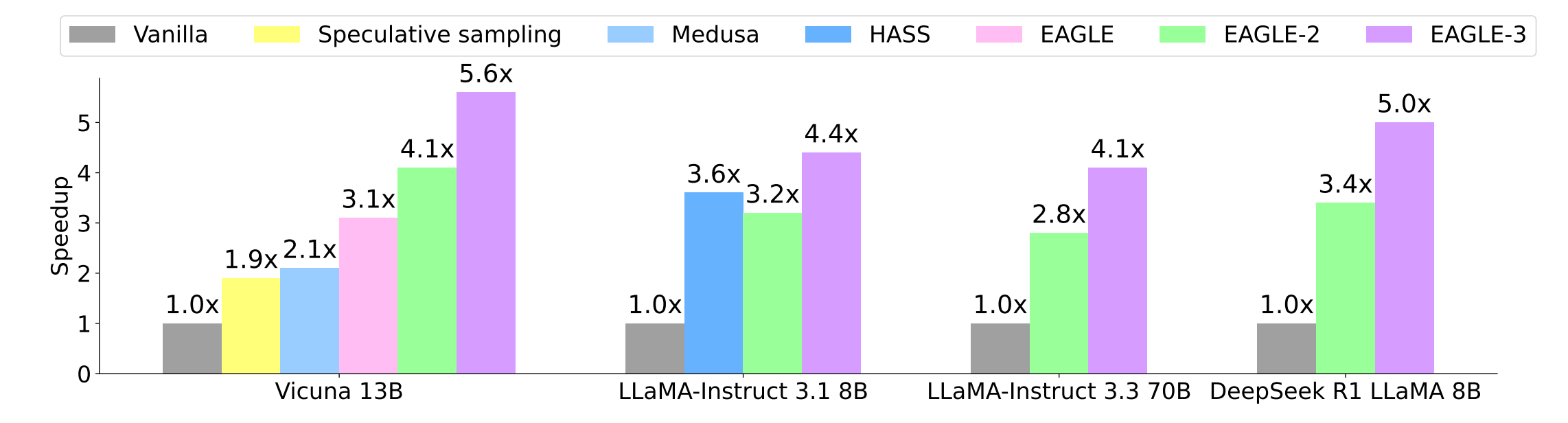
- 提出了 EAGLE‑3,一种将 推测解码(speculative decoding) 扩展到 LLM 解码的推理加速方法。
- 将 直接预测 token 取代特征向量回归,并引入 训练时测试(TTT) 循环,使草稿模型在自身带噪输出上训练。
- 融合 低层、中层和高层隐藏状态,而不仅依赖顶层特征。
2. 与以往工作的区别?
- 去除了 EAGLE/EAGLE‑2 中的 特征回归损失,草稿模型不再受高维 MSE 约束。
- 训练阶段草稿模型 反复以自身预测作为输入,对齐训练‑测试分布,避免误差累积。
3. 实验验证了什么?
- 与原生解码、spec‑sampling、PLD、Hydra、Medusa、HASS、EAGLE、EAGLE‑2 比较的 加速比与接受长度:EAGLE‑3 以 3–6.5 × 的速度提升领跑。
- 在 SGLang、H100 上批量 64 时吞吐提升 38 %;EAGLE‑2 在批量 24 后反而回退。
- 在 vLLM、RTX 3090 上批量 24 仍保持 ≥ 1.4 × 吞吐,而 EAGLE‑2 更早出现负增长。
- 接受率与加速比 随训练数据规模(1 ×→8 × ShareGPT)几乎线性增长,证明存在 Scaling Law。
4. 局限性?
- 受 GPU 预算限制,未在 400 B 级 前沿模型上验证。
- 训练仍需访问 目标模型隐藏状态,难以直接适配闭源 API(“是的, close AI!”)。
- 额外的全连接层 + 解码层增加草稿模型计算量。
- 评测主要关注延迟/吞吐,未重新验证生成质量。
5. 可以如何进一步工作?
- 扩展到 100 B + LLM(如 Mixtral、GPT‑J‑MoE)。
- 与 量化 & MoE 路由 结合,在控制显存的同时叠加速度收益。
- 将 TTT 扩展至 多 token 预测(类 Medusa) 或 对比式草稿选择,可能进一步提升接受长度。
- 集成进 分布式推理(TP / PP)。
附录
- Medusa:在主干 LLM 上挂多个解码头并行预测未来多个 token。
- Hydra:Medusa 的扩展,多头间顺序依赖,进一步提升接受率且无需额外前向。
- HASS(HArmonized Speculative Sampling):蒸馏“谐调”目标与上下文到草稿模型,缓解训练‑测试不匹配。
- 对比式草稿选择:通过对比目标选择多候选草稿中最佳者。