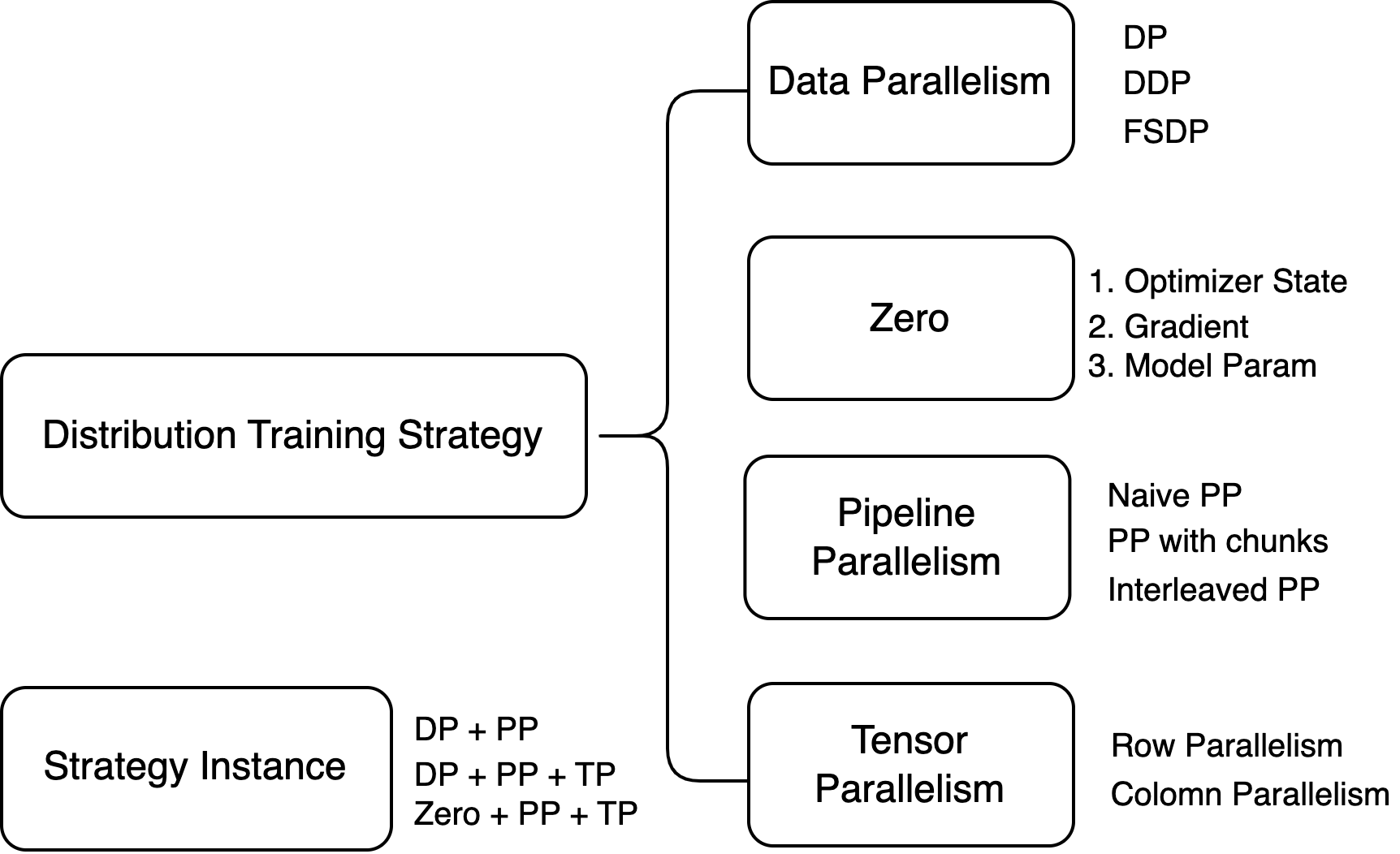
Distributed Training Strategy Introduction
Summary
这篇博客介绍了分布式并行训练策略,包括 Data Parallelism (DP), Zero Redundancy Optimizer (Zero), Pipeline Parallelism (PP) 和 Tensor Parallelism (TP)。
Data Parallelism
最简单的并行策略,每个 GPU 上都持有一份完整模型,并行地使用不同的训练数据输入模型:前向计算时每个 GPU 对分配的数据独立执行并计算 loss,再独立地进行反向传播计算梯度,随后通过通信 reduce(avg) 梯度,再 broadcast 到所有GPU上,最后使用平均梯度更新模型权重。
由于 DP 每个 GPU 上都持有完整模型参数、优化器状态,所以对显存并不友好
此外,DP 在每个 GPU 前向反向计算完后有一次通信聚合梯度
Pytorch 原生支持了这一功能,使用DataParallel(DP)或DistributedDataParallel(DDP)即可快速上手。我们更建议使用 DDP 而不是 DP,这是因为:
Pytorch DDP:
- 初始化后,每个 GPU 都有一份完整的模型。
- 数据划分成多个 micro batch,每个 GPU 基于自己的一部分数据进行前向计算,得到 loss,反向传播计算梯度
- 所有 GPU 通信,使用 all-reduce 让每个GPU得到加和后平均的梯度。
- 每个 GPU 基于平均梯度更新自己的模型
Pytorch DP:
- GPU0 加载一个 batch 的数据到内存中,然后划分并发送给其他 GPU
- GPU0 复制并发送整个模型 给其他 GPU,注意每个batch都需要执行一次这样的操作
- 其他 GPU 进行前向计算,得到的结果发送给 GPU0 计算 loss
- loss 计算完成后,GPU0 将其广播给其他GPU,进行反向传播
- 其他 GPU 再把反向传播得到的梯度发送给 GPU0 进行加和平均。
- GPU0 更新自己的模型,在下一个 batch 再发送整个模型给其他 GPU
我们可以很清晰地看出:
- 一个 batch Pytorch DDP 只需 all-reduce 通信一次梯度,而DP需要进行五次数据交换(分发数据、模型复制、前向结果、loss广播、梯度聚合)。
- DP 引入了主节点,主节点负担过大导致整体利用率无法提升
- DP 使用
threads通信( GIL 限制)而 DDP 使用torch.distributed通信。
此外,Pytorch 也开发了 Fully Sharded Data Parallelism (FSDP),在 DDP 的基础上引入模型参数的分片,不过由于使用成本较高,业界现在更多使用下文介绍的 Zero
Zero Redundancy Optimizer:Zero
Zero将Optimizer State(优化器状态),梯度和模型参数划分到各个数据并行进程中,消除了大量内存冗余占用,并通过一种动态的通信机制在各设备间共享必要的状态。
Note: 如果你对Zero有兴趣,可以和zero_paper_summary一起阅读
Zero的三个阶段
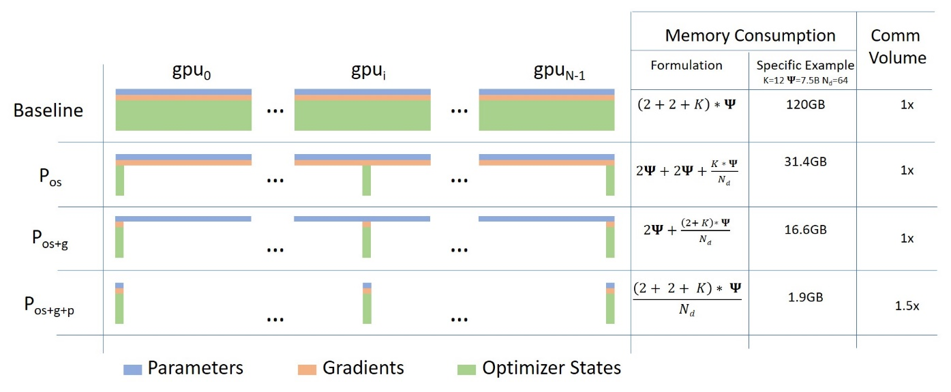
在图中,Ψ 表示模型参数数,K 表示优化器特定的常量,Nd 指 GPU 数量,优化对应三个阶段。
Stage1:优化器状态分割,在图示情况下减少四倍内存占用,与 DDP(data parallelism)相同的通信量(一次all-reduce)。优化器状态是什么?例如:Adam 有 FP32的 params、momentum和variance
Stage2:增加梯度分割(FP16 运行时的 gradient),在图示情况下减少八倍内存占用,与 DDP 相同通信量(但由于较为复杂,实际通信开销会更大)。
Stage3:增加模型参数分割(运行时FP 16),随 GPU 增加线性倍数减少内存占用(如64个 GPU 就减少64倍),大约增加50%通信量。
训练流程实例
我们开启 Zero 三个 stage,假设有四块卡进行训练(一次前向反向和参数更新)为例,说明训练流程.
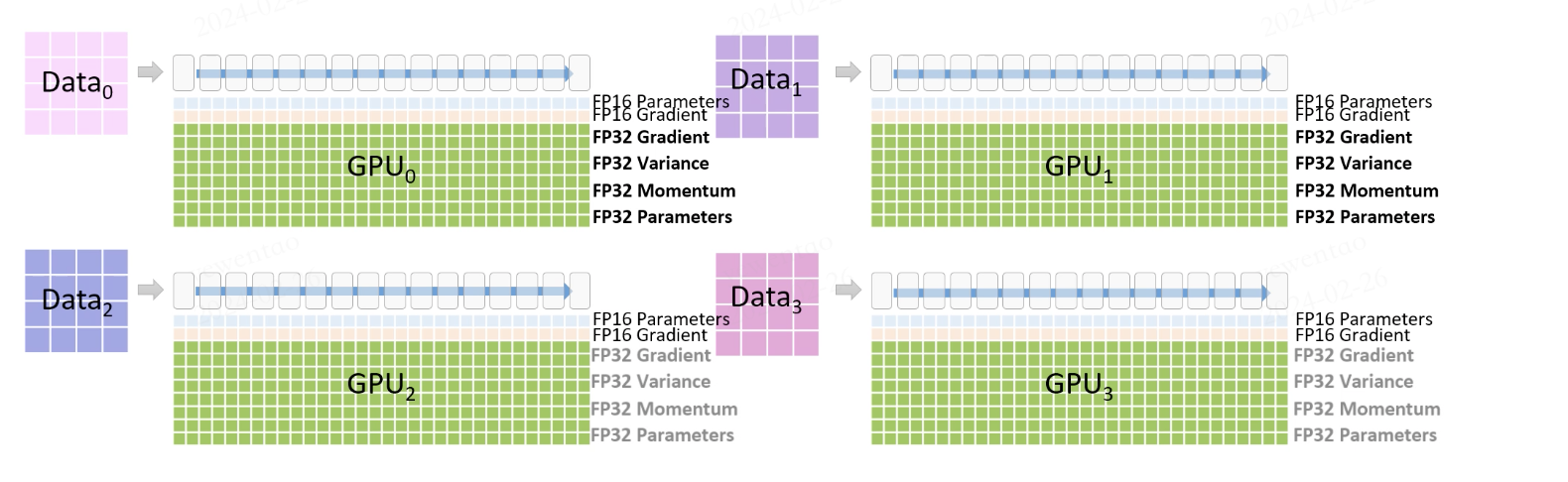
首先进行前向,数据会划分为4份准备输入各个 GPU,GPU 上有 FP16 的参数和梯度(用于实际计算)和存储的 FP32 优化器状态(这部分会在 FP16 梯度计算完成后使用)。
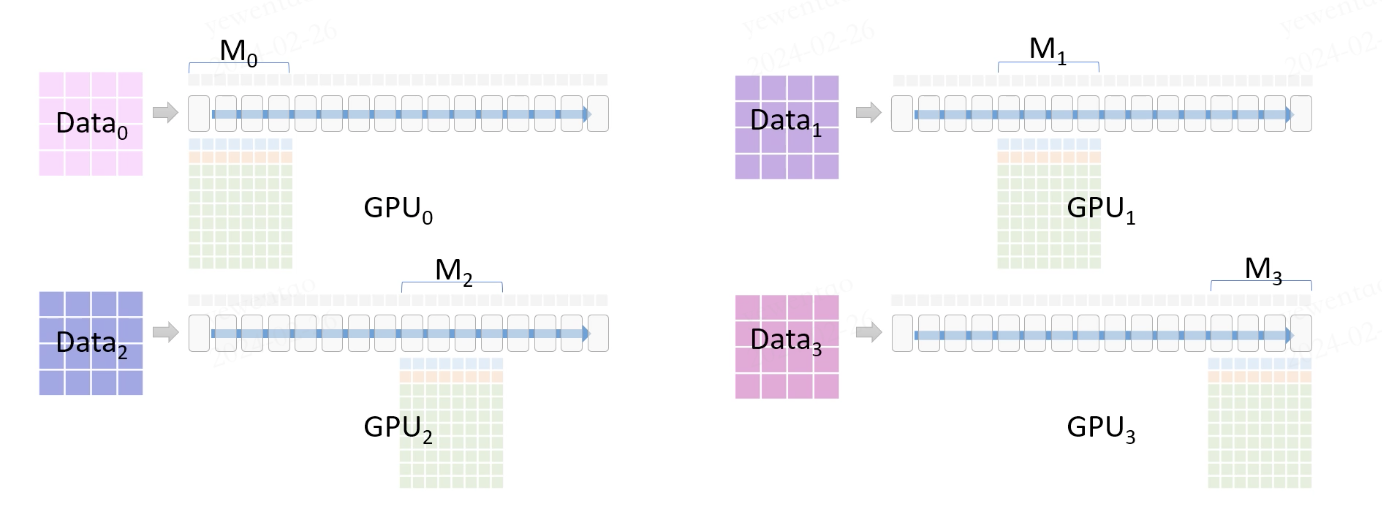
准备开始进行前向运算,每个 GPU 持有一部份模型参数。
那对于 GPU 没有的参数,如何进行前向运算呢?答案是通信
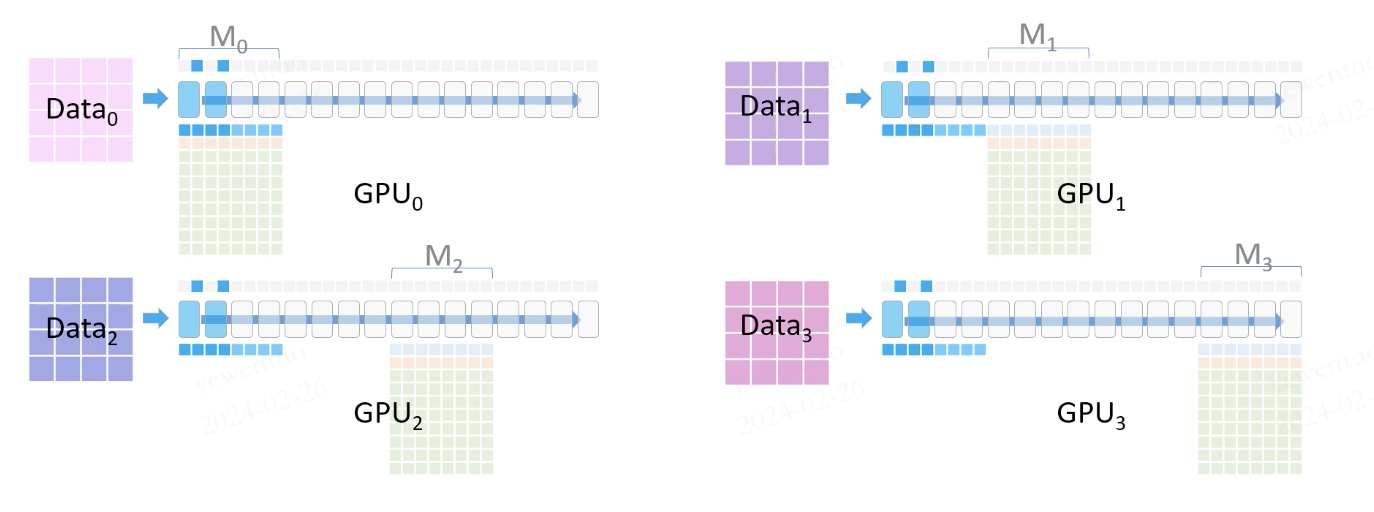
如图所示,GPU0 广播了 M0 的前向参数(FP16 Params)给其他 GPU,然后每个 GPU 这部分参数,以自己的数据进行前向运算。前向运算结束后,其他GPU上这部分共享的参数会被删除。
注意前向运算得到的激活值只会保存一部分,以尽可能节约显存占用。被丢弃的激活值会在反向传播时通过重计算 ,即checkpoint 得到。
随后是 GPU1 广播 M1 的前向参数,以此类推,直到完成整个前向过程,计算出 loss(每个 GPU 基于自己数据集的loss)。
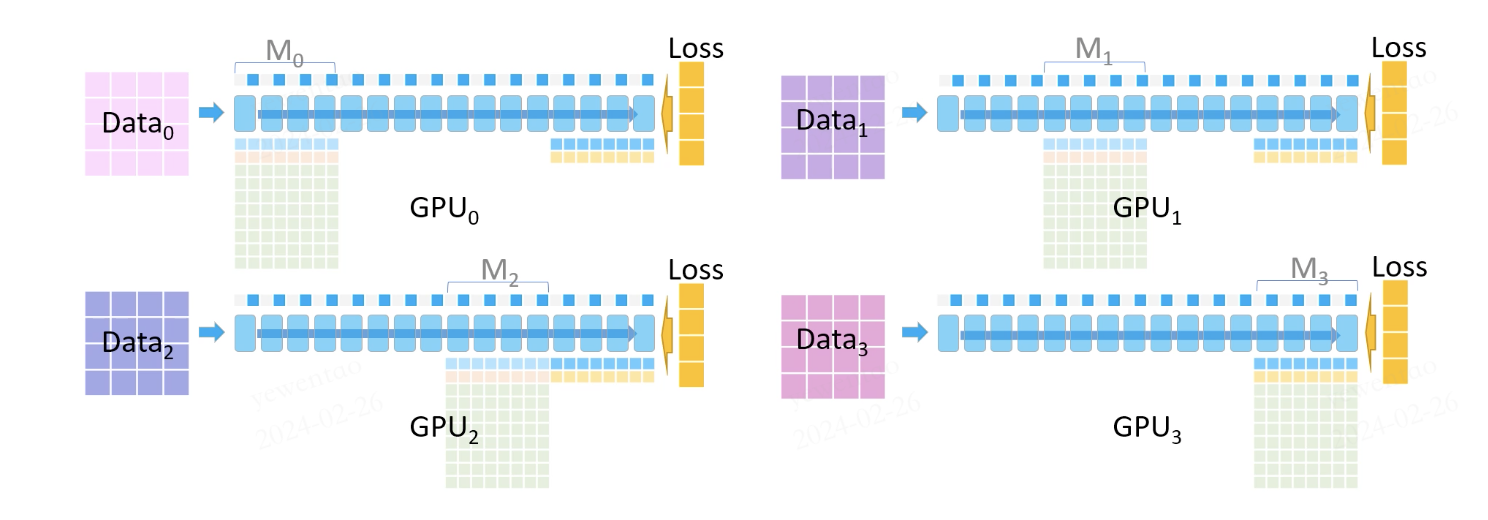
随后反向传播开始:
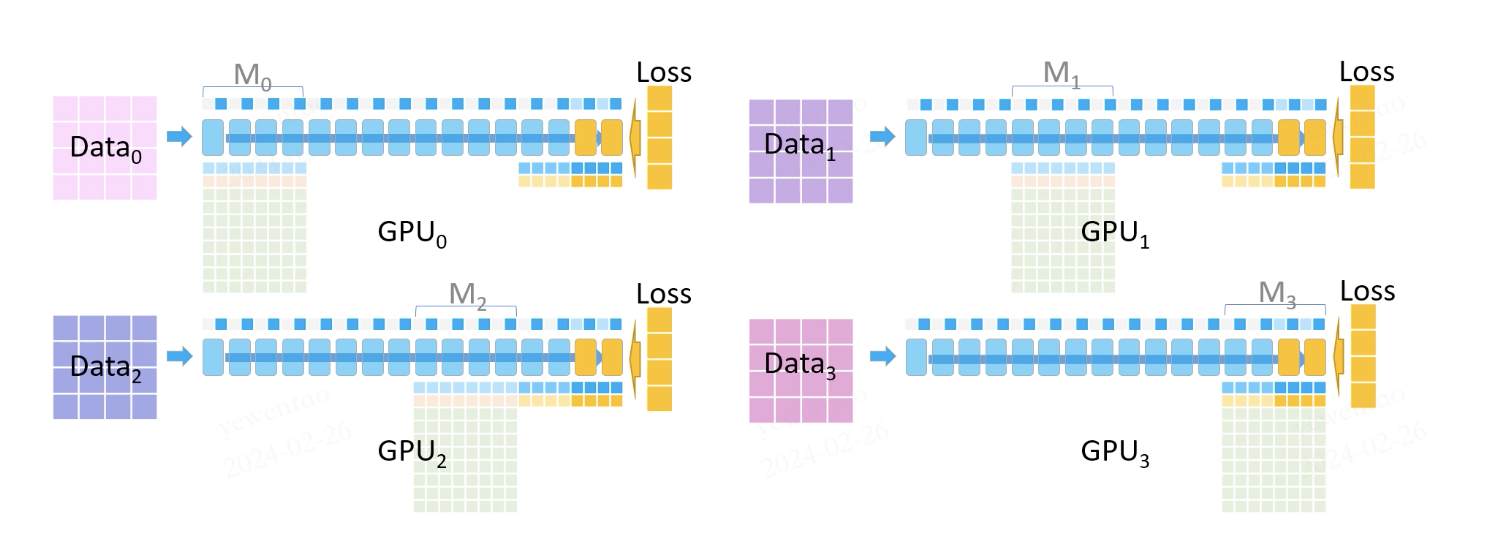
此时 M3 的模型参数都还在,缺失的激活值会通过之前保留的部分激活值重计算得到(如我们有十层,保留0、2、4、6、8,通过模型参数和保留的激活值 计算得到1、3、5、7、9的前向输出)
每个 GPU 根据 loss、激活值和模型参数 进行反向传播计算出自己的梯度后,其他 GPU 将梯度通信给 GPU3 ,GPU3 进行梯度累加并平均,这样 GPU3 上的梯度就是综合考虑所有数据的完整的梯度。
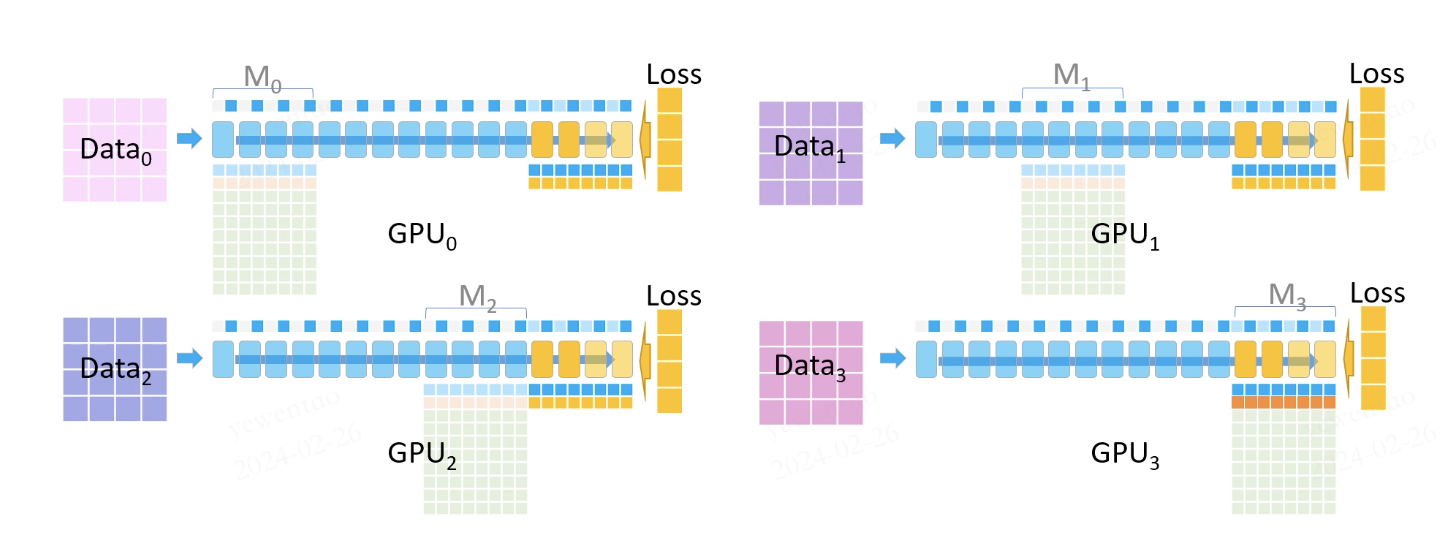
梯度累加计算完成后,其他 GPU 删除 M3 的参数、梯度以尽可能节约显存,同时所有 GPU 都删除了所有保存的前向激活值。反向传播继续进行:
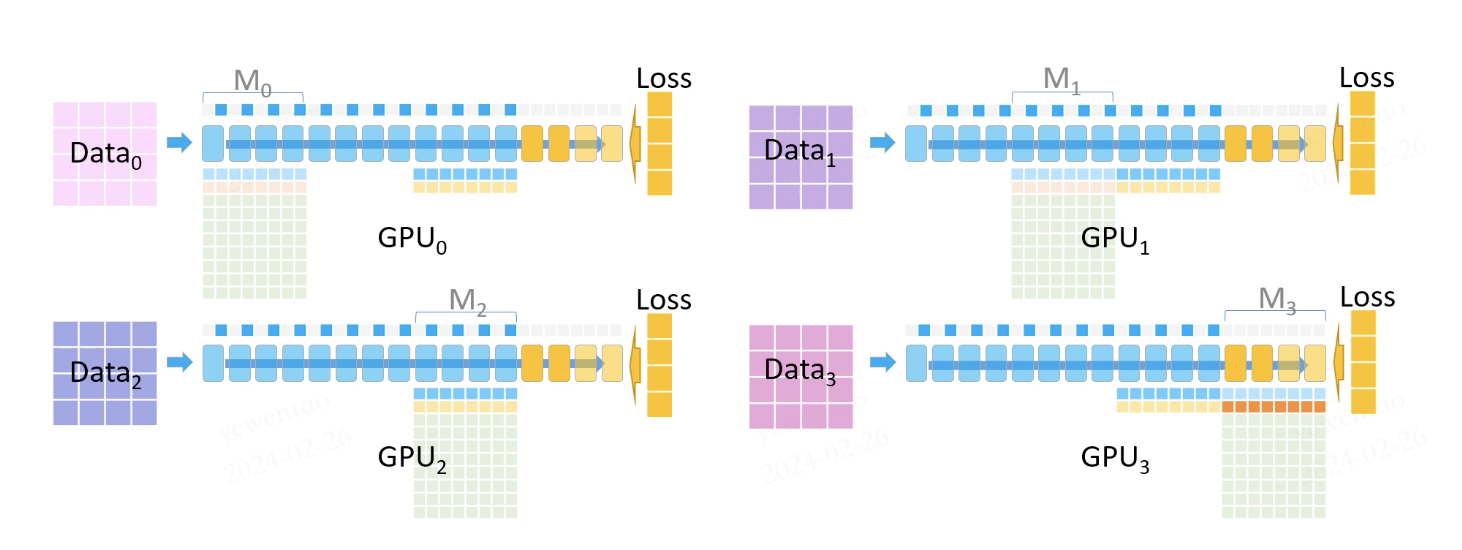
我们现在需要计算 M2 的梯度,此时 GPU2 会 broadcast 这部分参数给其他 GPU,随后同样通过参数 + 保存的部分激活值重计算 + loss 得到 M2 的梯度。
以此类推,直到所有梯度都计算完成
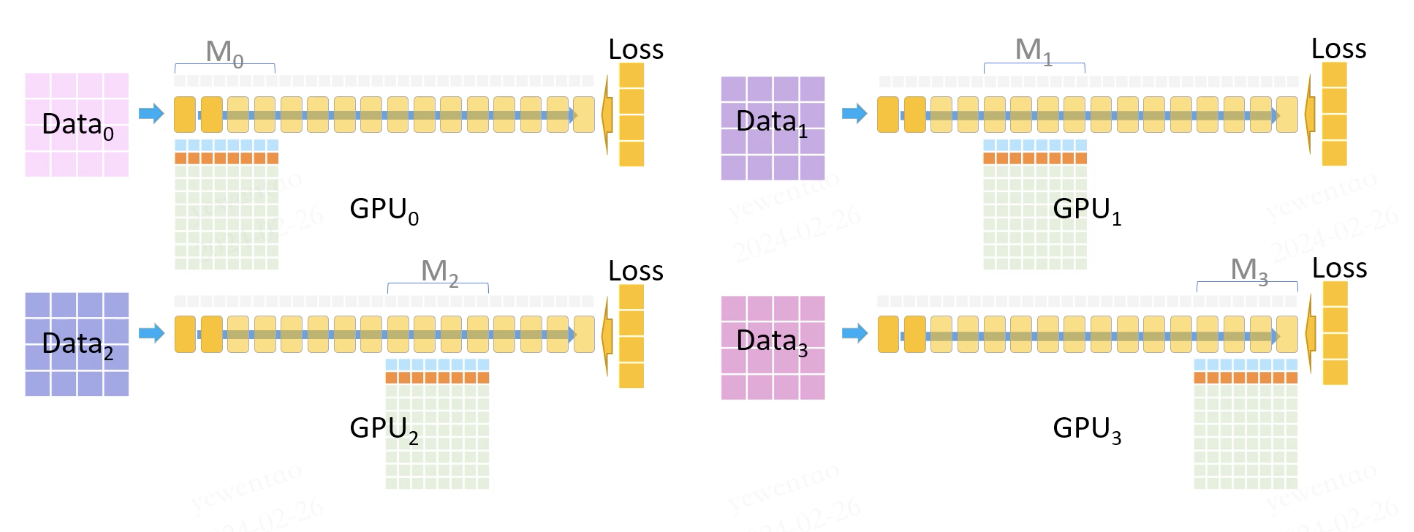
此时,所有GPU都有自己的梯度(来自自所有数据集)。
随后优化器利用这些梯度(FP16)更新自己的模型参数(FP32)(运算会使用FP32梯度、FP32 momentum、FP32 variance和 FP32 Params)
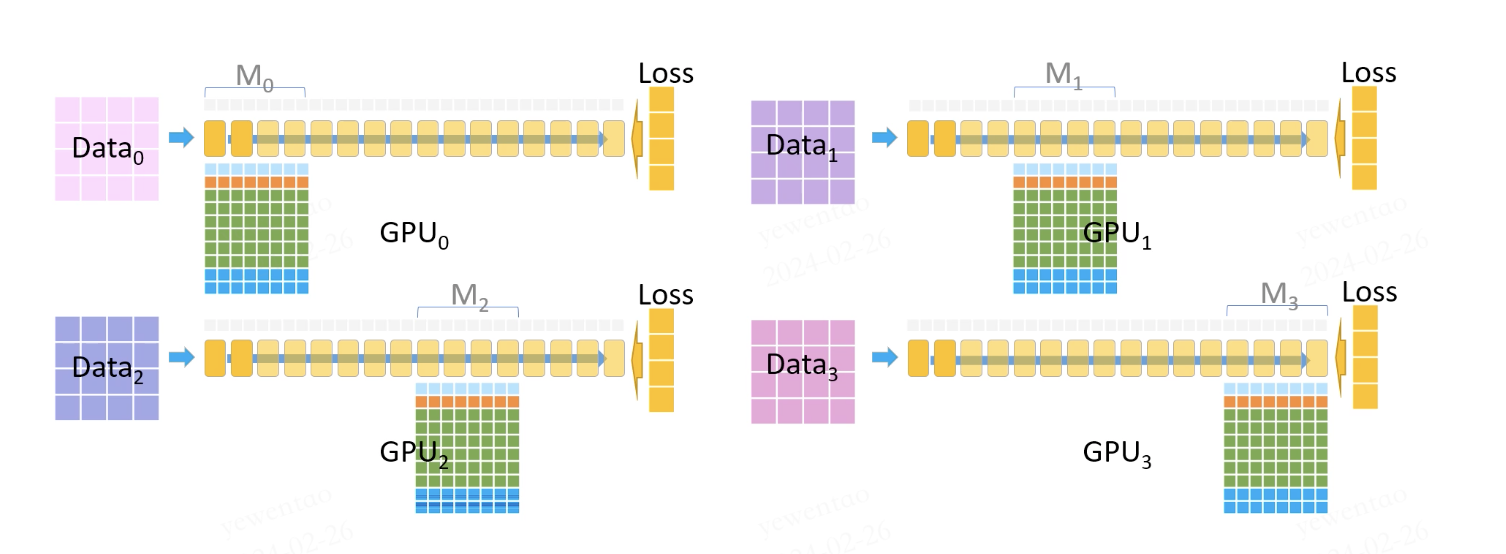
最后,这些 FP32 的模型参数会被 cast 到 FP16,用于下一个iter的模型训练(混合精度训练)。
DeepSpeed使用例子:
model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,
model=model,
model_parameters=params)
# torch.distributed.init_process_group(...) -> deepspeed.init_distributed()默认 NCCL backend
之后就像平常训练一样
for step, batch in enumerate(data_loader):
#forward() method
loss = model_engine(batch)
#runs backpropagation
model_engine.backward(loss)
#weight update
model_engine.step()自动做了并行。如果多节点,默认用Open MPI:A High Performance Message Passing Library
Zero 通信量分析
常规DP,每一步的梯度聚合 (all-reduce) 有 2Ψ 通信量,reduce-scatter使用Ψ和 all gather使用Ψ(更严谨一点的通信量是2Ψ (N-1)/N,这里我们简化处理)
stage1:我们切分了优化器状态,但梯度和模型参数没有切分,通信量与传统DP保持不变(我们不会通信FP32的optimizer state如momentum、variance等)。
但通信方式有所变化,我们先完整计算自己这部分data的梯度,然后reduce scatter让梯度分片到所有device上,拿自己的一部分梯度和自己的一部分optimizer state对自己负责的一部分参数进行更新。随后all gather让参数对所有device统一。
stage2:我们切分了梯度,每个GPU只保留自己部分所需要的梯度。
在实现上,Zero不再使用all-reduce进行通信,而是在所有GPU计算好某个GPU所需要的某层的梯度后,将这部分梯度打包进行一次reduce操作,每次reduce通信量是Ψ/N,这部分要进行N次。注意这个梯度reduce的操作可以和计算交叠(计算不依赖这部分梯度,因为每个GPU始终用于计算的是自己data的梯度,不需要把这个reduce后的梯度投入计算),因此效率也很高。
从全局视角上看,这类似于进行一次所有梯度的reduce-scatter通信,这部分通信量是Ψ。
然后每个GPU自己的参数更新后,再进行一次全局的all-gather操作来收集所有的参数(注意这里的参数不是指stage3切分的运行时参数,而是指更新后的模型参数),这部分的通信量也是Ψ,综合还是2Ψ。
stage3:现在每个GPU只存自己分区的对应参数,这部分通信量包含三部分
- 前向传播时,要计算某些层,对应分区需要广播这部分的参数,通信量为
Ψ/N,一共进行N次,总通信量为Ψ。(备注:论文提到,类似于schedule一次all-gather通信,但实现上是broadcast如上面图例所示) - 反向传播同理,要类似地进行
Ψ的参数通信 - 每层的梯度算出来后,同样进行N次reduce操作,相当于只要一次全局reduce-scatter通信avg梯度,实现
Ψ
综合以上三点,三个stage 合计3Ψ 1.5倍通信量
注意,和stage2相比,我们在这里不需要再进行一次all-gather统合参数,因为参数已经被分区了,每个GPU只需要管理好自己分到的的参数即可。
Zero-R: Further Optimizations for Residual Memory
上文我们重点介绍了Zero-DP的内容,此外还有Zero-R(residual memory)来进一步优化显存占用,主要包含:activation 分区存储、管理临时buffer和显存碎片优化
- Partitioned Activation Checkpointing:激活分区存储
即将前向计算的结果分区到不同的GPU上存储,需要用到时(如计算该层梯度)才all gather到本地。这可以进一步节约显存
如果显存确实不够,也可以选择Zero-offload将activation存储到CPU,对于计算强度很大的模型(如GPT-2),offload不会显著拖慢训练(因为计算和通信交叠)
- CB:固定大小的缓冲 (Constant Size Buffers)
LLM中通常把参数和梯度拼成一大块来提高通信(all-reduce)的效率,因此这块buffer的大小会线性增大,显存占用巨大。
ZeRO-R 采用“固定大小”的缓冲区策略 (constant-size buffer),模型小则缓冲区能全部容纳,模型大则分批处理,避免了缓冲区占用过多。
- MD:内存碎片消除 (Memory Defragmentation)
长生命周期tensor(activation、gradient)等与短生命周期tensor交替出现(临时激活、算子运算中间缓冲),导致显存碎片化
Zero-R 优先将activation和gradient分配到预留好的连续大块buffer中,不仅减少碎片,还加速了内存分配/释放
从论文实验结果来看,分区activation的通信量大概只有TP的10%,而且能显著增大batch size,这不仅能加速训练,而且减少了整体DP的梯度通信量(iteration数少了),因此引入Zero-R对训练十分有益。
Pipeline Parallelism
PP 的核心思想是把一个模型的不同层划分到不同 GPU 上,每个 GPU 只需要负责一部分模型
例如,一个六层的模型划分到两个GPU上:
============= =============
| 0 | 1 | 2 | 3 | 4 | 5
============= =============
gpu0 gpu1当一批数据输入时,先进入 gpu0 经由 layer0到2 计算,随后.to()到 gpu1 上经由 layer3到5 计算
通常 labels 会被送到模型最后一层所在的 GPU 上直接计算 loss,然后反向传播、更新模型参数。
这种设计有什么问题呢?当一批数据在 GPU1 计算的时候,GPU0 处于空闲状态!因此,我们引入了流水线并行,尽可能减少 GPU 空闲的时间。
一种实现如 GPipe:
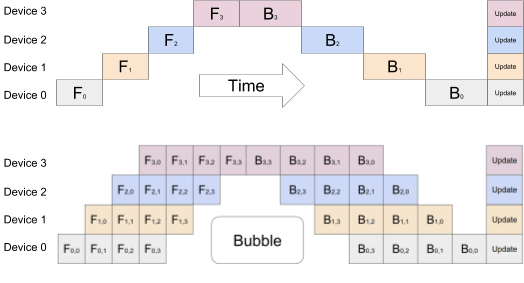
其核心思想是将输入数据划分为多个 micro-batch,让 GPU 可以并行处理不同的 micro-batch 以尽可能提高利用率,减少 GPU 空闲时间(气泡,bubble)。在上面的图中,4个 GPU 以 chunk=4(即在一个 pipeline stage同时中处理 4 批次的数据)训练,以 GPU0 为例,从 F0到F3 进行四个 forward 计算然后转交给下一个 GPU ,随后执行 B3到B0 四个 backward 计算。
如果在训练中同时开启了 DP 和 PP,我们有global_batch_size = micro_batch_size * dp_size * chunk:如 global_batch_size=512、DP=4、chunk=4,则最终得到 micro_batch_size=32,即每个 micro-bacth 有32条数据。
另外一种 PP 并行策略的实现如 Interleaved Pipeline:

如图,通过设计流水并行策略,我们可以减少 bubble 并提高 GPU 利用率。
值得指出的是,PP 只需要在相邻模型层传递计算好的批次数据结果,且我们可以通过重叠计算和通信来进一步减少开销,因此 PP 所需通信量是最小的,在实际训练中一般会把 PP 层跨节点使用,把节点内高带宽通信让给 TP
注意:PP尽量不用于 inference,除非显存完全不够。(inference没有足够数据会很多bubble)
Tensor Parallel(Model Parallel)
Tensor Parallelism 有时也称为 Model Parallel,属于计算层面的优化,核心思想是每个 GPU 只处理 tensor 的一部分(与PP 处理模型不同层不同,这里 TP 将模型的一层拆分),只在需要时聚合在一起。
例如:Y = GELU(XA),这里 Y 是输出,X 是输入,A 是模型权重,GELU 是非线性激活
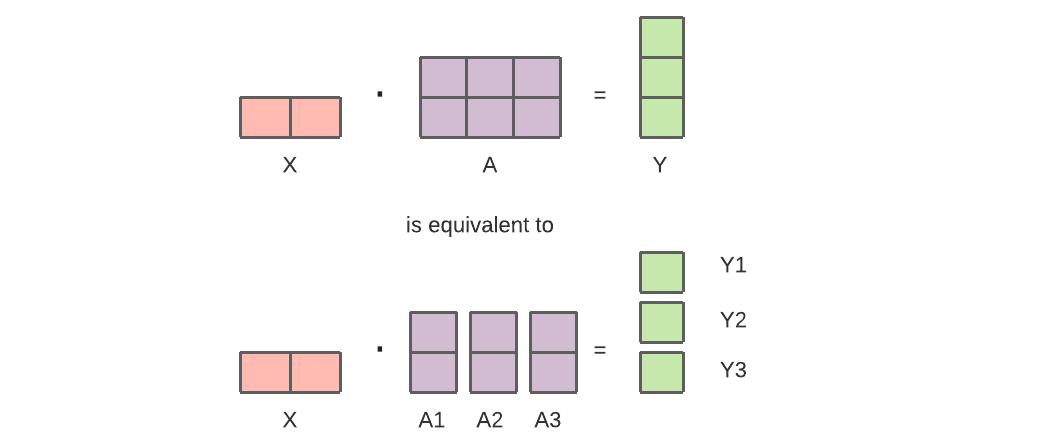
我们可以把 A1、A2、A3 放到不同的 GPU 上计算以节约显存。
TP 有两种切分方式,一种是行并行(row Parallelism),一种是列并行(column Parallelism):
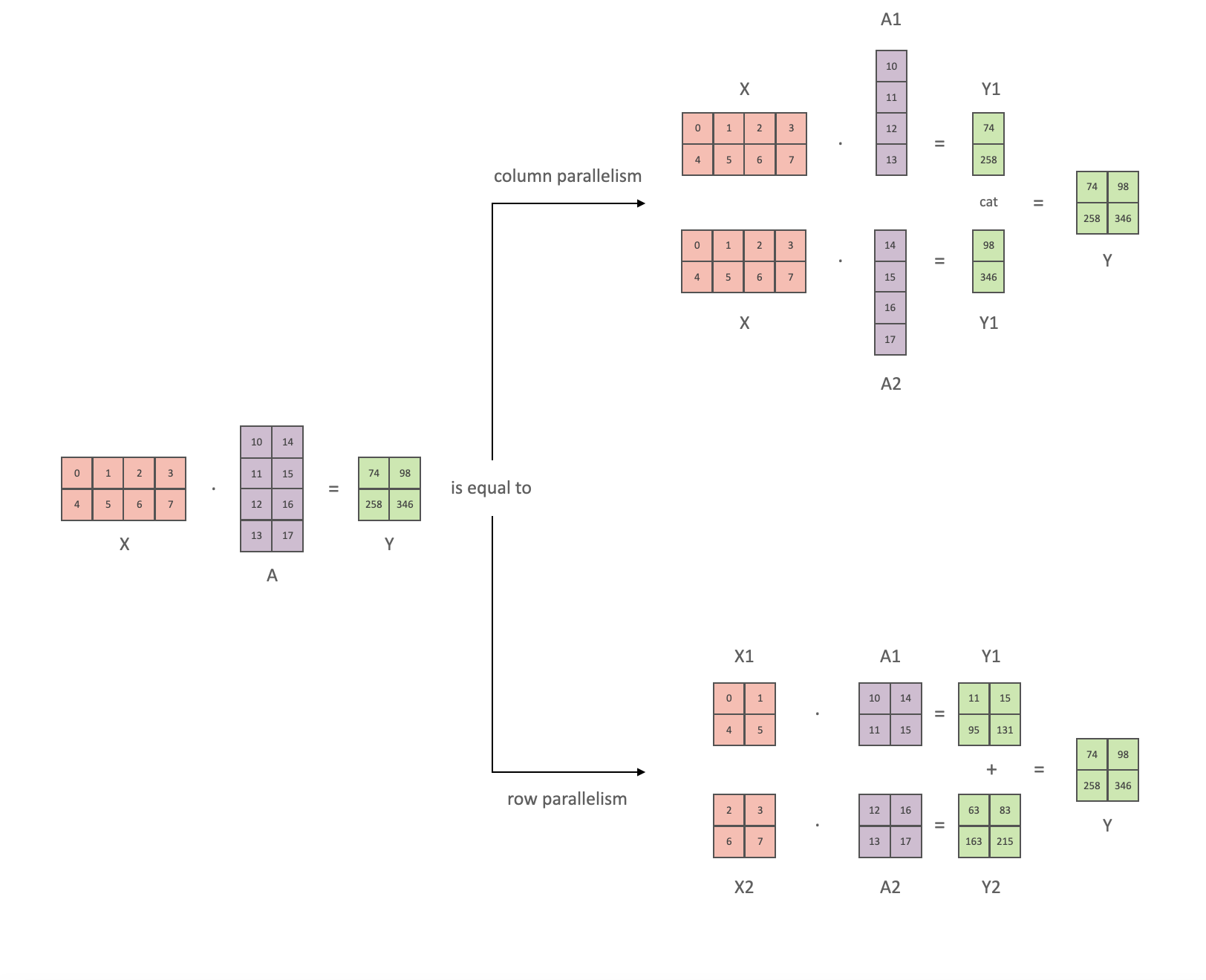
column Parallelism 不处理输入数据(2*4),按 column 划分模型参数(4*1),最后结果(2*1)cat起来得到结果(2*2)
row Parallelism 将输入数据按 column 划分(2*2),将模型参数按 row 划分(2*2),点积后再相加得到结果(2*2)。
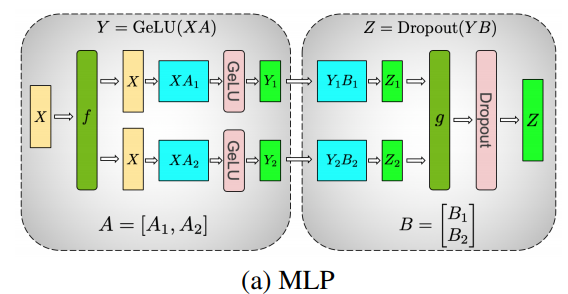
我们可以在模型设计上直接利用 TP,如 多层感知机 MLP(Multi-Layer Perceptron):
再比如 MHA(Multi Head Attention),由于设计上 MHA 就是并行执行的,引入 TP 更加简单:
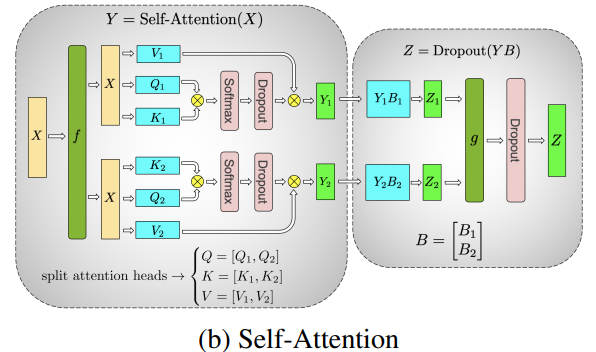
注意:由于切分计算后往往要 gather 通信,TP 总通信量较大,不建议跨节点使用 TP(tp_size < GPUs per node)。此外,TP 切分后,每个 GPU 需要存储的前向激活值也对应切分,可以较好地降低显存占用。
实例介绍
DP + PP
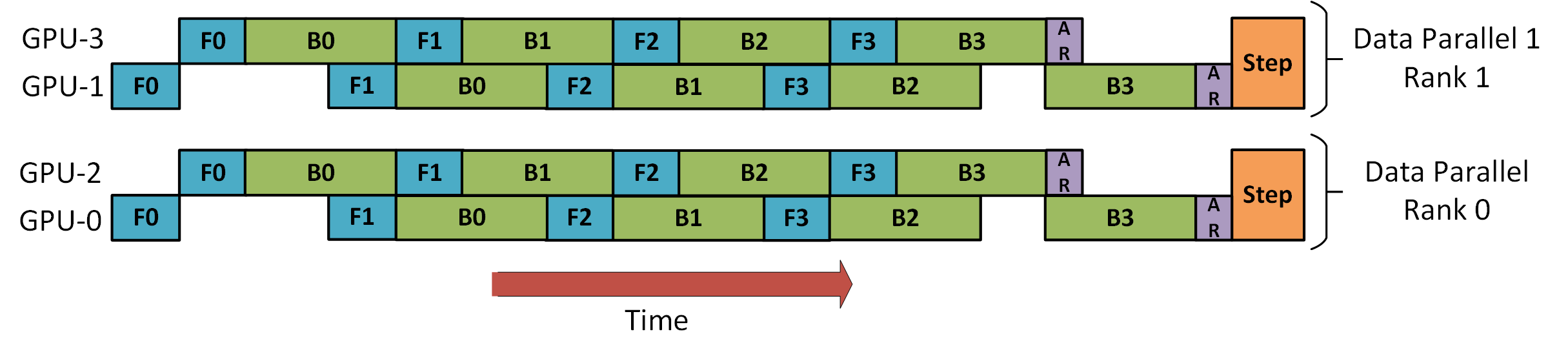
如图所示,我们有 4 个 GPU,2 DP + 2 PP。GPU[0, 2]和GPU[1, 3] 构成 PP 通信组,GPU[0, 1]构成 DP 通信组。
对 DP 而言,只能看见 GPU0 和 GPU1 两个实例,“看不见” GPU2 和 GPU3。在训练时,DP 会将数据划分给两个看得见的GPU,然后 GPU0 和 GPU1 利用 PP “偷偷”把任务转交一部分给 GPU2 和 GPU3。
Zero(DP) + PP + TP
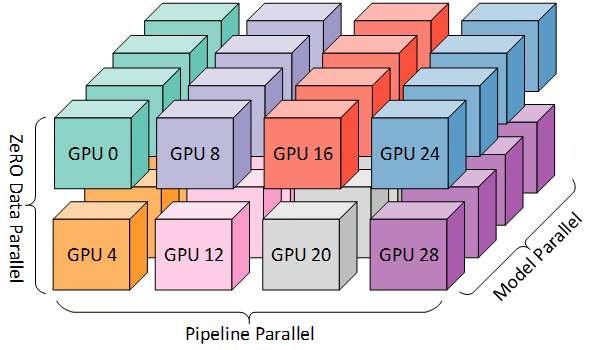
如图所示,我们有 八个节点、32 个 GPU,每个节点四个GPU。我们将 TP 通信组放在同一个节点上,然后 PP = 4,DP = 2,三维并行训练。
Zero可以理解为一种高度扩展的DP,可以与PP和TP共同使用,但一般只适用于 Zero Stage1
这是因为如果引入 Zero Stage2 梯度分割的话,每个 micro batch 执行都需要引入一次通信聚合梯度,而使用 PP 天然就会使用更多的micro batch,因此这部分通信开销会相对更大。此外,引入 PP 后模型分层,梯度本身大小也变为了原来的1 / PP_size,节约显存效果也没那么明显。因此我们一般不会让 Zero Stage2 与 PP 共同使用。
Referrence
- Microsoft Research Blog: “Zero DeepSpeed: New System Optimizations Enable Training Models with Over 100 Billion Parameters”
- Hugging Face Transformers Documentation: “Parallelism Techniques”
- Google AI Blog: “Introducing GPipe: An Open Source Library for Efficiently Training Large-scale Neural Network Models”
- AWS SageMaker Documentation: “Model Parallel Core Features”
- Arxiv Preprint: “An Analysis of Model Parallelism in Training Large-scale Neural Networks”
- DeepSpeed Tutorial: “Pipeline Parallelism Tutorial”
- Microsoft Research Blog: “DeepSpeed: Extreme-Scale Model Training for Everyone”
- Hugging Face Documentation: “Training Large Models: A Deep Dive on GPU Performance”