Deep Dive into PyTorch Device Copy Operations
Summary
这篇文章主要介绍了 PyTorch 设备 copy的细节,包含D2H/H2D和D2D(在同一设备与不同设备上)等内容。
这篇文章使用
O3-mini-high翻译,如有困惑请参考英文原文
0. 引言
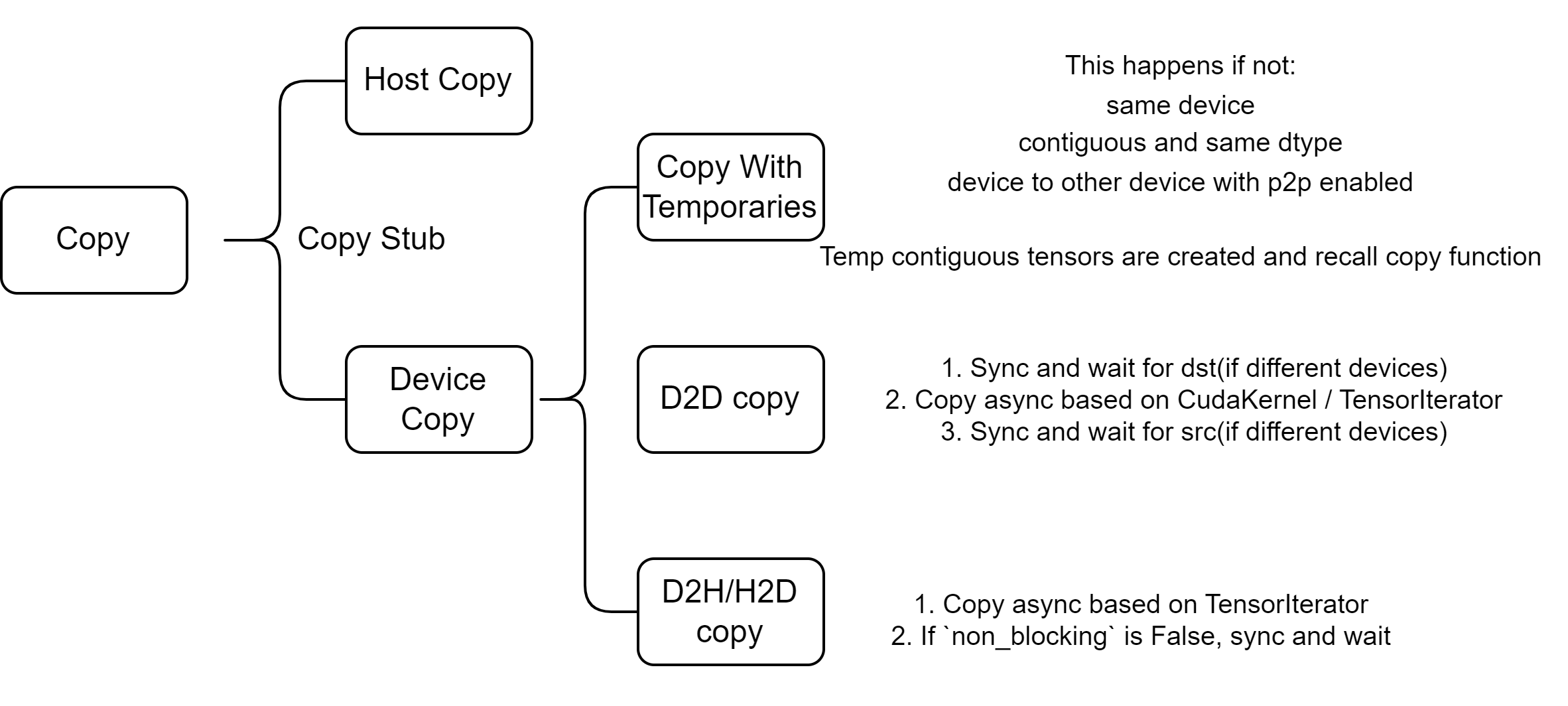
在 PyTorch 中,复制操作主要分为两大类:
- 主机内复制:主机到主机(CPU 到 CPU)
- 设备内复制:包括 D2H、H2D、D2D 等
在 deep_dive_into_contiguous 中,我们已经介绍了 H2H 的机制。
本文将重点关注设备复制操作。
1. 复制入口(Copy Stub)
所有复制操作的入口均位于 Copy.cpp 文件中:
// aten/src/ATen/native/Copy.cpp
static Tensor & copy_impl(Tensor & self, const Tensor & src, bool non_blocking) {
// ...
if (self.is_same(src)) {
return self;
}
// 如果 self 和 src 是同一数据的不同视图,则提前退出
const bool is_same_data = (
self.is_alias_of(src) &&
self.storage_offset() == src.storage_offset() &&
self.strides().equals(src.strides()) &&
self.sizes().equals(src.sizes()) &&
self.scalar_type() == src.scalar_type() &&
self.is_conj() == src.is_conj() &&
self.is_neg() == src.is_neg()
);
if (is_same_data) {
return self;
}
auto iter = TensorIteratorConfig()
.add_output(self)
.add_input(src)
.resize_outputs(false)
.check_all_same_dtype(false)
.check_all_same_device(false)
.build();
if (iter.numel() == 0) {
return self;
}
DeviceType device_type = iter.device_type(0);
if (iter.device_type(1) == kCUDA) {
device_type = kCUDA;
} else if (iter.device_type(1) == kHIP) {
device_type = kHIP;
} else if (iter.device_type(1) == kMPS) {
device_type = kMPS;
}
// ...
copy_stub(device_type, iter, non_blocking);
return self;
}构造好 TensorIterator 后,会调用 copy_stub 函数:
// aten/src/ATen/native/DispatchStub.h
template <typename rT, typename T, typename... Args>
struct DispatchStub<rT (*)(Args...), T> {
public:
template <typename... ArgTypes>
rT operator()(DeviceType device_type, ArgTypes&&... args) {
FnPtr call_ptr = get_call_ptr(device_type);
return (*call_ptr)(std::forward<ArgTypes>(args)...);
}
}注意,这里的内核函数(call_ptr)是通过 DispatchStub 进行注册的。这个注册过程在 Copy.cpp 和 Copy.h 中都有声明。
// aten/src/ATen/native/Copy.cpp
DEFINE_DISPATCH(copy_stub); // struct copy_stub copy_stub;
// torch/include/ATen/native/Copy.h
DECLARE_DISPATCH(copy_fn, copy_stub);
/* `DECLARE_DISPATCH` 展开后:
struct copy_stub : DispatchStub<copy_fn, copy_stub> {
copy_stub() = default;
copy_stub(const copy_stub&) = delete;
copy_stub& operator=(const copy_stub&) = delete;
};
extern __attribute__((__visibility__("default"))) struct copy_stub copy_stub
*/此外,内核函数还会为特定设备注册:
// CPU 内核注册
// aten/src/ATen/native/cpu/CopyKernel.cpp
REGISTER_DISPATCH(copy_stub, ©_kernel);
// CUDA 内核注册
// aten/src/ATen/native/cuda/Copy.cu
REGISTER_DISPATCH(copy_stub, ©_kernel_cuda);
// 展开后:static RegisterCUDADispatch<struct copy_stub> copy_stub__register(copy_stub, ©_kernel_cuda);
// torch/include/ATen/native/DispatchStub.h
template <typename DispatchStub>
struct RegisterCUDADispatch {
RegisterCUDADispatch(DispatchStub &stub, typename DispatchStub::FnPtr value) {
stub.set_cuda_dispatch_ptr(value);
}
};2. 带设备的复制
在调度(dispatch)后,会执行 copy_kernel_cuda 函数:
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
AT_ASSERT(iter.ntensors() == 2);
Device dst_device = iter.device(0);
Device src_device = iter.device(1);
// 开启设备间的 P2P(点对点)访问
bool p2p_enabled = maybe_enable_p2p_access(dst_device, src_device);
if (copy_requires_temporaries(iter, p2p_enabled)) {
// ...
return;
}
// GPU 上(或 GPU 间)的复制
if (dst_device.is_cuda() && src_device.is_cuda()) {
copy_device_to_device(iter, non_blocking, p2p_enabled);
return;
}
// CPU 与 GPU 之间的复制
// ...
}整个过程大致可以分为三部分:
- 使用临时变量进行复制
- 在 GPU 上进行复制,或者在启用 P2P 的情况下在多个 GPU 间复制
- CPU 与 GPU 之间的复制(不需要使用临时变量)
2.1 使用临时变量的复制
只有在以下情况不需要使用临时变量:
- 同一设备内的复制:不需要临时变量。
- 内存连续且数据类型相同的复制:不需要临时变量。
- 启用 P2P 的设备间复制:不需要临时变量。
在其他情况下,函数 copy_requires_temporaries 会返回 True,此时会利用临时连续张量来辅助复制操作。
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
if (copy_requires_temporaries(iter, p2p_enabled)) {
auto& dst = iter.tensor(0);
Tensor dst_contig;
Tensor src_contig;
if (iter.device_type(0) == kCUDA || non_blocking) {
// 分支:在 CUDA 或者设置了 non_blocking 的情况下
// 如果 dst 已经是连续的,则直接使用,否则创建一个连续张量
dst_contig = dst.is_contiguous() ? dst : at::empty_like(dst, LEGACY_CONTIGUOUS_MEMORY_FORMAT);
// src 需要与 dst 具有相同数据类型和形状,且为连续内存
src_contig = iter.tensor(1).to(iter.dtype(0)).expand_as(dst).contiguous();
} else {
// 分支:非 CUDA 且 non_blocking 为 false
bool same_type = iter.dtype(0) == iter.dtype(1);
// 如果 dst 连续且与 src 数据类型相同,则使用 dst,否则创建一个连续张量
dst_contig = (dst.is_contiguous() && same_type) ? dst : at::empty_like(dst, iter.dtype(1), LEGACY_CONTIGUOUS_MEMORY_FORMAT);
// 保证 src 与 dst 形状一致且连续
src_contig = iter.tensor(1).expand_as(dst).contiguous();
}
// ...
// 在连续内存的张量上进行同类型复制
dst_contig.copy_(src_contig, non_blocking);
// 如果必要,将数据复制回 dst
if (!dst_contig.is_same(dst)) {
TORCH_INTERNAL_ASSERT(dst_contig.device() == dst.device());
dst.copy_(dst_contig, non_blocking);
}
return;
}
}
static bool copy_requires_temporaries(TensorIterator& iter, bool p2p_enabled) {
// ...
if (dst_device == src_device) {
// 同一设备内,无需临时变量
return false;
}
bool same_dtype = iter.dtype(0) == iter.dtype(1);
if (same_dtype && iter.is_contiguous()) {
// 数据类型相同且内存连续,可直接使用 `cudaMemcpyAsync`
return false;
} else if (dst_device.is_cuda() && src_device.is_cuda()) {
// 两个 GPU 之间的复制,如果支持 P2P,则无需临时变量
return !p2p_enabled;
} else {
// 其他情况均需要使用临时变量
return true;
}
}上述代码中,我们会先创建 dst_contig 和 src_contig 两个临时张量,然后利用 copy_ 方法进行复制。待所有输入张量都转换为连续内存后,再进入后续分支完成复制操作。
最后,如有必要,还会将数据从临时张量复制回目标张量。
2.2 GPU 内的复制
当两个张量都位于 GPU 上时,就会执行 D2D 复制:
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
if (dst_device.is_cuda() && src_device.is_cuda()) {
copy_device_to_device(iter, non_blocking, p2p_enabled);
return;
}
// ...
}copy_device_to_device 函数的实现如下:
// aten/src/ATen/native/cuda/Copy.cu
void copy_device_to_device(TensorIterator& iter,
bool non_blocking,
bool p2p_enabled) {
int64_t numel = iter.numel();
// 如果满足 memcpy_eligibility 条件,则可以直接调用 memcpy
bool same_type = iter.dtype(0) == iter.dtype(1);
bool same_conj = iter.tensor(0).is_conj() == iter.tensor(1).is_conj();
bool same_neg = iter.tensor(0).is_neg() == iter.tensor(1).is_neg();
bool memcpy_eligible = same_type && same_conj && same_neg && iter.is_contiguous();
Device dst_device = iter.device(0);
Device src_device = iter.device(1);
// 设备守护(Device Guard)用于设置和恢复当前设备上下文
CUDAGuard device_guard(src_device);
CUDAStream copy_stream = getCurrentCUDAStream(src_device.index());
if (src_device != dst_device) {
// 同步...
}
if (memcpy_eligible) {
// 数据类型相同、内存连续且 conjugation 和 negation 状态一致
void *dst = iter.data_ptr(0);
void *src = iter.data_ptr(1);
size_t size = numel * iter.element_size(0);
if (src != dst || src_device != dst_device) {
// 由于 CUDA 驱动的一些特殊情况,如果两块 cudaMallocAsynced 内存所在设备不支持 P2P,
// 则需要使用 "cudaMemcpyPeerAsync"
bool needs_pool_specific_peer_access = CUDACachingAllocator::get()->needsPoolSpecificPeerAccess();
bool needs_MemcpyPeer = (src_device != dst_device &&
needs_pool_specific_peer_access &&
!p2p_enabled);
if (needs_MemcpyPeer) {
AT_CUDA_CHECK(cudaMemcpyPeerAsync(
dst, dst_device.index(),
src, src_device.index(),
size, copy_stream));
} else {
AT_CUDA_CHECK(cudaMemcpyAsync(
dst, src, size,
cudaMemcpyDeviceToDevice,
copy_stream));
}
}
} else {
if (same_neg) {
if (!same_conj) {
conj_kernel_cuda(iter);
} else {
direct_copy_kernel_cuda(iter);
}
} else {
if (!same_conj) {
neg_conj_kernel_cuda(iter);
} else {
neg_kernel_cuda(iter);
}
}
}
if (src_device != dst_device) {
// 同步
}
AT_CUDA_CHECK(cudaGetLastError());
}整个 D2D 复制流程可以分为三个阶段:
- 在目标张量所在流中进行阻塞等待(同步 1)。
- 异步执行复制操作。
- 在源张量所在流中进行阻塞等待(同步 2)。
对于异步复制的逻辑也较为直接:如果满足 memcpy_eligible 条件,则直接调用 cudaMemcpyPeerAsync 或 cudaMemcpyAsync。否则,会根据具体的 conjugation 和 negation 状态,选择调用 direct_copy_kernel_cuda 或其他内核函数。
例如,对于 direct_copy_kernel_cuda,在源代码中是这样实现的(针对 conjugation 和 negation 状态一致的情况):
// aten/src/ATen/native/cuda/Copy.cu
void direct_copy_kernel_cuda(TensorIteratorBase &iter) {
ScalarType dtype = iter.dtype(0);
if (isQIntType(dtype)) {
AT_DISPATCH_QINT_TYPES(dtype, "copy_", [&] {
gpu_kernel(iter, [] GPU_LAMBDA(scalar_t x) { return x; });
});
} else {
AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND4(
kHalf, kBool, kBFloat16, kComplexHalf, dtype, "copy_", [&] {
gpu_kernel(iter, [] GPU_LAMBDA(scalar_t x) { return x; });
});
}
}这里通过 gpu_kernel 调用 CUDA 内核,对数据进行简单的复制(lambda 函数 return x;)。
关于同步操作,代码中在源流和目标流分别设置了两个阻塞点:
// aten/src/ATen/native/cuda/Copy.cu
void copy_device_to_device(TensorIterator& iter,
bool non_blocking,
bool p2p_enabled) {
// ...
// 使用设备守护设置/恢复当前设备上下文
CUDAGuard device_guard(src_device);
CUDAStream copy_stream = getCurrentCUDAStream(src_device.index());
if (src_device != dst_device) {
CUDAEvent dst_ready;
device_guard.set_device(dst_device);
// 在目标设备的流上记录事件
dst_ready.record(getCurrentCUDAStream(dst_device.index()));
device_guard.set_device(src_device);
// 阻塞当前源流,直到目标流中 dst_ready 事件完成
dst_ready.block(copy_stream);
}
// ... 异步执行复制
if (src_device != dst_device) {
CUDAEvent src_ready;
// 在源流中记录事件
src_ready.record(copy_stream);
// 切换到目标设备的流,阻塞直到源流中的操作全部完成
device_guard.set_device(dst_device);
src_ready.block(getCurrentCUDAStream(dst_device.index()));
}
AT_CUDA_CHECK(cudaGetLastError());
}第一个同步操作(在源流中等待目标流中的 dst_ready 事件)确保目标流中前置的所有操作均已完成,为复制操作做好准备;第二个同步操作则保证复制完成后目标流中的所有操作都已结束。
通过这两个同步步骤,可以确保复制过程的安全性和数据一致性。
2.3 CPU 与 GPU 之间的复制(无需临时变量)
本部分讨论对于连续内存的张量,在 CPU 与 GPU 之间的复制操作。
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
// CPU 与 GPU 之间的复制
cuda::OptionalCUDAGuard device_guard;
cudaMemcpyKind kind;
if (dst_device.is_cuda() && src_device.is_cpu()) {
device_guard.set_device(dst_device);
kind = cudaMemcpyHostToDevice;
} else if (dst_device.is_cpu() && src_device.is_cuda()) {
device_guard.set_device(src_device);
kind = cudaMemcpyDeviceToHost;
} else {
TORCH_INTERNAL_ASSERT(false, "unsupported devices in GPU copy_()");
}
void* dst = iter.data_ptr(0);
void* src = iter.data_ptr(1);
int64_t nbytes = iter.numel() * iter.element_size(0);
CUDAStream stream = getCurrentCUDAStream();
if (non_blocking) {
AT_CUDA_CHECK(cudaMemcpyAsync(dst, src, nbytes, kind, stream));
const auto& dst_tensor = iter.tensor(0);
const auto& src_tensor = iter.tensor(1);
const auto& host_tensor = (dst_device == kCPU ? dst_tensor : src_tensor);
auto* ptr = (dst_device == kCPU ? dst : src);
auto* ctx = host_tensor.storage().data_ptr().get_context();
// 在当前 CUDA 流中基于 host tensor 的 context 和数据指针记录事件
CachingHostAllocator_recordEvent(ptr, ctx, stream);
} else {
at::cuda::memcpy_and_sync(dst, src, nbytes, kind, stream);
}
// ... neg 与 conj 操作
}这里,通过 TensorIterator 获取源和目标张量的数据指针,根据 non_blocking 参数选择直接调用 cudaMemcpyAsync(并记录事件)或调用 memcpy_and_sync 同步复制数据。
// torch/include/c10/cuda/CUDAFunctions.h
C10_CUDA_API void __inline__ memcpy_and_sync(
void* dst,
void* src,
int64_t nbytes,
cudaMemcpyKind kind,
cudaStream_t stream) {
// ... gpu trace
C10_CUDA_CHECK(cudaMemcpyAsync(dst, src, nbytes, kind, stream));
C10_CUDA_CHECK(cudaStreamSynchronize(stream));
}在这种复制方式中,记录的事件与 CUDAHostAllocator 有关,通常一个张量的内存块在该事件标记完成之前不会被重用。有关内存缓存的更多细节,可参考 aten/src/ATen/cuda/CachingHostAllocator.cpp。
图示总结