Deep Dive to Pytorch AutoGrad(2)
反向求导,y.backward()
python层Tensor.backward封装
python层调用tensor.backward()不会直接调用到c++层,而是在python层做了一些处理
# torch/_tensor.py
class Tensor(torch._C._TensorBase):
def backward(
self, gradient=None, retain_graph=None, create_graph=False, inputs=None
):
r"""
Args:
gradient (Tensor or None): grad_output,没传可以当成1,如本文例子中
如果传入`torch.tensor([2.0])`,则x.grad结果会变为12
retain_graph (bool, optional): 是否保留计算图,一般情况下都不需要设置
create_graph (bool, optional): 是否为导数创建计算图,以用于计算高阶导数,我们下文用一个例子来展开说明此参数
inputs (sequence of Tensor): 只计算指定inputs的梯度,其他tensor(即使是叶子节点)的梯度会被忽略
"""
# ...
torch.autograd.backward(
self, gradient, retain_graph, create_graph, inputs=inputs
)
# torch/autograd/__init__.py
def backward(
tensors: _TensorOrTensors,
grad_tensors: Optional[_TensorOrTensors] = None,
retain_graph: Optional[bool] = None,
create_graph: bool = False,
grad_variables: Optional[_TensorOrTensors] = None,
inputs: Optional[_TensorOrTensors] = None,
) -> None:
# ...
if retain_graph is None:
retain_graph = create_graph
Variable._execution_engine.run_backward(
tensors, grad_tensors_, retain_graph, create_graph, inputs,
allow_unreachable=True, accumulate_grad=True)create_graph参数用于指明是否为导数创建计算图以计算高阶导数,例如:
import torch
x = torch.tensor([3.0], requires_grad=True)
y = x * x
y.backward(create_graph=True)
print(x.grad) # tensor([6.])
grad1 = x.grad.clone() # 在新的计算图上计算二阶导
# x.grad.zero_() 清空x的梯度
grad1.backward()
# y = x^2,二阶导结果为2
print(x.grad) # 根据是否清空x的梯度,得到tensor([2.])或tensor([8.])解析python参数,调用Engine::execute
然后运行到python_engine.cpp,解析python参数,拆成cpp所需数据结构
// torch/csrc/autograd/python_engine.cpp
PyObject* THPEngine_run_backward(
PyObject* self,
PyObject* args,
PyObject* kwargs) {
// 解析python参数...
bool backward_api_called = accumulate_grad;
// ...
edge_list roots;
roots.reserve(num_tensors);
variable_list grads;
grads.reserve(num_tensors);
// 将参数存储在`edge_list roots`和`variable_list grads`中
for (const auto i : c10::irange(num_tensors)) {
PyObject* _tensor = PyTuple_GET_ITEM(tensors, i);
// ...
const auto& variable = THPVariable_Unpack(_tensor);
auto gradient_edge = torch::autograd::impl::gradient_edge(variable);
// ...
roots.push_back(std::move(gradient_edge));
PyObject* grad = PyTuple_GET_ITEM(grad_tensors, i);
if (THPVariable_Check(grad)) {
const Variable& grad_var = THPVariable_Unpack(grad);
// ...
grads.push_back(grad_var);
}
// 如果backward时有指定inputs(只计算这些inputs的梯度),收集output edges
std::vector<Edge> output_edges;
if (inputs != nullptr) {
// ...
}
variable_list outputs;
{
pybind11::gil_scoped_release no_gil;
// torch::autograd::Engine
auto& engine = python::PythonEngine::get_python_engine();
outputs = engine.execute(
roots,
grads,
keep_graph,
create_graph,
accumulate_grad,
output_edges);
}
// 如果backward时指定了inputs且accumulate_grad为false,生成返回值返回
if (!backward_api_called && inputs != nullptr) {
// ...
return py_outputs.release();
} else {
Py_RETURN_NONE;
}
// ...
}
}注意auto gradient_edge = torch::autograd::impl::gradient_edge(variable);,此处variable的grad_fn为MulBackward0,output_nr为0(可以和上文对照set_history起来看),随后将这条新边加入到edge_list roots中
Edge gradient_edge(const Variable& self) {
if (const auto& gradient = self.grad_fn()) {
return Edge(gradient, self.output_nr());
} else {
return Edge(grad_accumulator(self), 0);
}
}准备好参数后,调用Engine::execute()正式执行反向逻辑
准备graph_task、计算依赖数
// torch/csrc/autograd/engine.cpp
auto Engine::execute(
const edge_list& root_edges,
const variable_list& inputs,
bool keep_graph,
bool create_graph,
bool accumulate_grad,
const edge_list& outputs) -> variable_list {
// ...
// 在cpu上初始化一个thread local queue,或者复用现有的queue
init_local_ready_queue();
// not_reentrant_backward_call标记当前反向传播是否是重入调用
// 重入调用指的是在某个反向传播中,由于某些操作(如hooks或自定义的autograd function)
// 导致新的反向传播任务在当前任务结束前就开始了。
bool not_reentrant_backward_call = worker_device == NO_DEVICE;
// 用vector存储root node
c10::SmallVector<Node*, 4> temp_roots{root_edges.size()};
for (const auto i : c10::irange(root_edges.size())) {
temp_roots[i] = root_edges[i].function.get();
}
// GraphTask 包含反向传播所需的metadata
auto graph_task = std::make_shared<GraphTask>(
/* keep_graph */ keep_graph,
/* create_graph */ create_graph,
/* depth */ not_reentrant_backward_call ? 0 : total_depth + 1,
/* cpu_ready_queue */ local_ready_queue,
/* graph_roots */ std::move(temp_roots));
// 如果root节点只有一个,不需要额外创建root node
// 在本文语境中,这里root节点为`torch::autograd::generated::MulBackward0`
bool skip_dummy_node = root_edges.size() == 1;
auto graph_root = skip_dummy_node
? root_edges.at(0).function
: std::make_shared<GraphRoot>(root_edges, inputs);
// 遍历计算并取出outputs(这里outputs是python层backward中传进来的inputs参数)
// 中最小的topo_nr,如果outputs为空则为0。
auto min_topo_nr = compute_min_topological_nr(outputs);
compute_dependencies(graph_root.get(), *graph_task, min_topo_nr);
if (!outputs.empty()) {
graph_task->init_to_execute(
*graph_root, outputs, accumulate_grad, min_topo_nr);
}
if (skip_dummy_node) {
InputBuffer input_buffer(root_edges.at(0).function->num_inputs());
// 这里input是backward传进来的gradient参数,没传默认是tensor([1.])
auto input = inputs.at(0);
// pytorch中,stream是一个独立的任务队列,任务按照被添加的顺序执行
const auto input_stream = InputMetadata(input).stream();
// 尝试获得根节点的cuda stream(如果有的话),没有则仍是cpu stream
const auto opt_next_stream =
root_edges.at(0).function->stream(c10::DeviceType::CUDA);
input_buffer.add(
root_edges.at(0).input_nr,
std::move(input),
input_stream,
opt_next_stream);
execute_with_graph_task(
graph_task, std::move(graph_root), std::move(input_buffer));
} else {
execute_with_graph_task(
graph_task, std::move(graph_root), InputBuffer(variable_list()));
}
// 阻塞直到graph_task整体结果完成
auto& fut = graph_task->future_result_;
fut->wait();
graph_task->warning_handler_.replay_warnings();
return fut->value().toTensorVector();
}其中比较重要的是compute_dependencies,用于计算每个需要梯度的节点的依赖数,构建task.nodes_in_graph_数据结构,便于执行backward。
这里依赖数和下文中evaluate_function对照起来一起看可更好地理解:对于需要执行的next而言,构建时有一个node指向它,则增加它的依赖;当指向它的node执行完成后,依赖数便减1。如果依赖数减为0,则表示这个next准备好执行了。
// torch/csrc/autograd/engine.cpp
auto Engine::compute_dependencies(
Node* root,
GraphTask& task,
uint64_t min_topo_nr) -> void {
// ...
std::vector<Node*> queue{root};
auto& dependencies = task.dependencies_;
while (!queue.empty()) {
auto fn = queue.back();
queue.pop_back();
if (fn->topological_nr() < min_topo_nr) {
// 例如我们传了一个topo_nr为2的output,并计算出min_topo_nr=2
// 说明我们需要计算的output距离叶子节点有2的距离
// 根据本文之前对topo_nr的描述(即到任意叶子结点的最小距离)
// 我们可以跳过topo_nr小于2的节点不再考虑计算梯度
continue;
}
// ...
// task.nodes_in_graph_是一个`unordered_set`
// 这里是依照顺序添加下一个要运行的function到set中,并添加依赖数
for (const auto& edge : fn->next_edges()) {
if (auto next_ptr = edge.function.get()) {
dependencies[next_ptr] += 1;
const bool was_inserted = task.nodes_in_graph_.insert(next_ptr).second;
if (was_inserted)
queue.push_back(next_ptr);
}
}
}
// ...
}执行graph_task:execute_with_graph_task与thread_main循环
准备好依赖和所需stream后,执行execute_with_graph_task
// torch/csrc/autograd/engine.cpp
c10::intrusive_ptr<at::ivalue::Future> Engine::execute_with_graph_task(
const std::shared_ptr<GraphTask>& graph_task,
std::shared_ptr<Node> graph_root,
InputBuffer&& input_buffer) {
// 使用`c10::call_once`调用`Engine::start_device_threads`,初始化线程池,启动多线程
// 每个子线程都会初始化一个空的graph task,然后执行`thread_main`函数
initialize_device_threads_pool();
std::unique_lock<std::mutex> lock(graph_task->mutex_);
// 对于cpu而言,每个graph task单独一个queue,而cuda所有的task都共享ready queue
auto queue = ready_queue(graph_task->cpu_ready_queue_, input_buffer.device());
if (worker_device == NO_DEVICE) {
// 此时是一个cpu thread,非重入调用
set_device(CPU_DEVICE);
graph_task->owner_ = worker_device;
// 现在所有非线程安全的字段都被正确地初始化,可以放入队列中(std::priority_queue)了
// push的过程中还会调用condition_variable not_empty_唤醒其他线程来执行任务
queue->push(
NodeTask(graph_task, std::move(graph_root), std::move(input_buffer)));
lock.unlock();
thread_main(graph_task);
TORCH_INTERNAL_ASSERT(graph_task->future_result_->completed());
// 将worker_device重置为初始状态
// 不需要重置`local_ready_queue`因为它可以在每次call backward的时候重复使用
worker_device = NO_DEVICE;
} else {
// device已经被设置,如CPU、CUDA等,则意味着这是一个重入调用
graph_task->owner_ = worker_device;
queue->push(
NodeTask(graph_task, std::move(graph_root), std::move(input_buffer)));
if (current_depth >= max_recursion_depth_) {
// 抵达最大深度,启动一个新线程
add_thread_pool_task(graph_task);
} else {
// 所有线程的重入调用次数
++total_depth;
// 当前线程的重入调用次数
++current_depth;
lock.unlock();
thread_main(graph_task);
--current_depth;
--total_depth;
TORCH_INTERNAL_ASSERT(graph_task->future_result_->completed());
}
}
return graph_task->future_result_;
}在execute_with_graph_task函数中,pytorch初始化了很多子线程执行thread_main函数,而主线程也执行thread_main函数,直到所有队列里的任务被完成,随后子线程放一个dummy task到queue中,主线程接受后退出,execute_with_graph_task函数执行完成。
thread_main函数本身是一个block循环,会不断执行任务直到graph_task被标记完成
// torch/csrc/autograd/engine.cpp
auto Engine::thread_main(const std::shared_ptr<GraphTask>& graph_task) -> void {
TORCH_INTERNAL_ASSERT(local_ready_queue != nullptr);
while (graph_task == nullptr || !graph_task->future_result_->completed()) {
std::shared_ptr<GraphTask> local_graph_task;
{
// 这里划分一个scope是因为NodeTask在该block后可以被完全销毁并释放所有空间
NodeTask task = local_ready_queue->pop();
if (task.isShutdownTask_) {
C10_LOG_API_USAGE_ONCE("torch.autograd.thread_shutdown");
break;
}
// `task.base_`为`std::weak_ptr<GraphTask>`,lock()方法尝试创建一个`std::shared_ptr<GraphTask>`
// 如果graphtask对象已经销毁,name返回空nullptr跳过该task
if (!(local_graph_task = task.base_.lock())) {
continue;
}
set_device(worker_device);
// has_error_是一个`std::atomic_bool`值,当任何一个线程执行出错时,设置该变量
// 并让所有其他线程退出
if (task.fn_ && !local_graph_task->has_error_.load()) {
// RAII guard,保存tls和warning状态,在这段block代码执行完后恢复之前的状态
at::ThreadLocalStateGuard tls_guard(local_graph_task->thread_locals_);
c10::WarningUtils::WarningHandlerGuard warnings_guard(
&local_graph_task->warning_handler_);
try {
// guard机理同上,保存current_graph_task状态
GraphTaskGuard guard(local_graph_task);
NodeGuard ndguard(task.fn_);
{
// ...
evaluate_function(
local_graph_task,
task.fn_.get(),
task.inputs_,
local_graph_task->cpu_ready_queue_);
}
} catch (std::exception& e) {
thread_on_exception(local_graph_task, task.fn_, e);
}
}
}
// 后半部分参见下文...
}
}call_function和各种hook
上文调用了evaluate_function,再调用到call_function,call_function会调用实际进行backward运算的算子,并进行各种hook的调用
各种hook包括:
call_tensor_pre_hookscall_pre_hookscall_post_hooks
// torch/csrc/autograd/engine.cpp
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// 尝试获取cuda流,如果设备是cpu就是空的,guard在析构时能恢复原来的流。
const auto opt_parent_stream = (*func).stream(c10::DeviceType::CUDA);
c10::OptionalStreamGuard parent_stream_guard{opt_parent_stream};
// 如果exec_info_非空,会执行一些额外操作如pre-hook,根据need变量判断是否执行backward等
// 还有一些废弃的capture hook(捕获变量使用,但由于现在引入了tensor hook,这就没必要了)
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
// ...
}
// 实际调用backward函数的地方,包括对tensor pre/post hook的调用
auto outputs = call_function(graph_task, func, inputs);
// ...后半部分,参见下文
}
static variable_list call_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputBuffer) {
CheckpointValidGuard cpvguard(graph_task);
auto& fn = *func; // 本文语境中,fn为Mulbackward0
// 调用tensor本身的prehook
auto inputs =
call_tensor_pre_hooks(fn, InputBuffer::variables(std::move(inputBuffer)));
// 调用fn的prehook
inputs = call_pre_hooks(fn, std::move(inputs));
if (!graph_task->keep_graph_) {
// 如果没有keep_graph_设置的话,将释放中间variable
fn.will_release_variables();
}
const auto has_post_hooks = !fn.post_hooks().empty();
variable_list outputs;
if (has_post_hooks) {
// 这里是一个浅拷贝,使引用计数+1
auto inputs_copy = inputs;
outputs = fn(std::move(inputs_copy));
} else {
outputs = fn(std::move(inputs));
}
// ...
// 最后调用post_hooks返回
if (has_post_hooks) {
return call_post_hooks(fn, std::move(outputs), inputs);
}
return outputs;
}backward实际执行:MulBackward0::apply
fn()调度到实际执行backward的地方,如MulBackward0::apply,在这里进行实际梯度的运算。
// torch/csrc/autograd/generated/Functions.cpp
variable_list MulBackward0::apply(variable_list&& grads) {
std::lock_guard<std::mutex> lock(mutex_);
IndexRangeGenerator gen;
auto self_ix = gen.range(1); // {0, 1}
auto other_ix = gen.range(1); // {1, 2}
variable_list grad_inputs(gen.size()); // output: 2
const auto& grad = grads[0];
auto other = other_.unpack(); // MulBackward0 Node声明的变量other_, self_
// unpack()根据saved variable拿到或生成variable,此外检查版本等操作也在此处进行
auto self = self_.unpack();
bool any_grad_defined = any_variable_defined(grads);
if (task_should_compute_output({ other_ix })) {
// 用self算出other的grad
auto grad_result = any_grad_defined ? (mul_tensor_backward(grad, self, other_scalar_type)) : Tensor();
// 相当于grad_inputs[1] = grad_result
copy_range(grad_inputs, other_ix, grad_result);
}
if (task_should_compute_output({ self_ix })) {
// 用other算出self的grad
auto grad_result = any_grad_defined ? (mul_tensor_backward(grad, other, self_scalar_type)) : Tensor();
// 相当于grad_inputs[0] = grad_result
copy_range(grad_inputs, self_ix, grad_result);
}
return grad_inputs;
}
// torch/csrc/autograd/FunctionsManual.cpp
template <typename T>
Tensor mul_tensor_backward(Tensor grad, T other, ScalarType self_st) {
auto out = grad * other.conj(); // conj是复数接口,如果没有复数直接return this
return handle_r_to_c(self_st, std::move(out));
}evaluate_function与依赖数检查、优先队列readyQueue
执行完fn后,grad结果已经运算完成,我们回到evaluate_function检查依赖数和并将next推入ready queue中
// torch/csrc/autograd/engine.cpp
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// 实际调用backward函数的地方,包括对tensor pre/post hook的调用
auto outputs = call_function(graph_task, func, inputs);
// ...前半部分,参见上文
auto& fn = *func;
if (!graph_task->keep_graph_) {
// 如果不需要retain,释放无关变量(对于mul来说,即other_、self_中间变量的值)
fn.release_variables();
}
int num_outputs = outputs.size();
if (num_outputs == 0) {
// ...
return;
}
// AnomalyMode调试模式检查nan
if (AnomalyMode::is_enabled() && AnomalyMode::should_check_nan()) {
// ...
}
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto i : c10::irange(num_outputs)) {
auto& output = outputs[i];
const auto& next = fn.next_edge(i);
if (!next.is_valid())
continue;
bool is_ready = false;
auto& dependencies = graph_task->dependencies_;
auto it = dependencies.find(next.function.get());
if (it == dependencies.end()) {
// 检查next是否已经在graph_task中被构建好dependencies了,如果没有则报错
auto name = next.function->name();
throw std::runtime_error(std::string("dependency not found for ") + name);
} else if (--it->second == 0) {
// 如果在dependencies中,它的依赖数会减1,减1后依赖数为0则从dependencies中删除
// 标记is_ready为true,表示准备好执行
dependencies.erase(it);
is_ready = true;
}
auto& not_ready = graph_task->not_ready_;
auto not_ready_it = not_ready.find(next.function.get());
if (not_ready_it == not_ready.end()) {
// 如果next不在not_ready(std::unordered_map)中,创建InputBuffer并根据is_ready
// 来加入ready_queue或者not_ready map中
// ...
InputBuffer input_buffer(next.function->num_inputs());
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(
next.input_nr, std::move(output), opt_parent_stream, opt_next_stream);
if (is_ready) {
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
} else {
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
} else {
// 如果在not_ready中,一定有input_buffer(走过一次上面的分支)
auto& input_buffer = not_ready_it->second;
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(
next.input_nr, std::move(output), opt_parent_stream, opt_next_stream);
if (is_ready) {
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
not_ready.erase(not_ready_it);
}
}
}
}我们也介绍一下任务队列ReadyQueue这个数据结构:
// torch/csrc/autograd/engine.h
struct ReadyQueue {
private:
// 当t2应该比t1先执行时,return true
// 关闭的任务首先考虑执行,其次是空节点任务
struct CompareNodeTaskTime {
bool operator()(NodeTask const& t1, NodeTask const& t2) {
if (t2.isShutdownTask_) {
return true;
} else if (!t1.fn_ || t1.isShutdownTask_) {
return false;
} else if (!t2.fn_) {
return true;
} else if (t1.getReentrantDepth() == t2.getReentrantDepth()) {
return t1.fn_->sequence_nr() < t2.fn_->sequence_nr();
} else {
return t1.getReentrantDepth() < t2.getReentrantDepth();
}
}
};
// 唤醒等待ready queue的线程
std::condition_variable not_empty_;
// 用于读写heap_的锁
mutable std::mutex mutex_;
// priority_queue:本质是一个堆
std::priority_queue<NodeTask, std::vector<NodeTask>, CompareNodeTaskTime> heap_;
public:
void push(NodeTask item, bool incrementOutstandingTasks = true);
void pushShutdownTask();
NodeTask pop();
bool empty() const;
size_t size() const;
};在ready queue中使用std::priority_queue优先队列(本质是堆)来作为数据存储的容器,通过CompareNodeTaskTime来比较任务优先级。
在比较时,优先处理已关闭的任务、空任务(处理效率高迅速腾出空间),然后选择深度较浅及sequence_number较大的任务。
backward实际执行:AccumulateGrad::apply
在mul_backward执行完后,我们将AccumulateGrad加入了执行队列(这是因为AccumulateGrad是mul_backward的next_edge,不理解的同学可以参考上文前向构建过程),并经过类似的调度过程,最后执行到了AccumulateGrad::apply实现梯度累加
// torch/csrc/autograd/functions/accumulate_grad.cpp
auto AccumulateGrad::apply(variable_list&& grads) -> variable_list {
// ...
at::Tensor new_grad = std::move(grads[0]);
// 这里variable即我们的tensor参数self/other,前向构建时保存了下来
at::Tensor& grad = variable.mutable_grad();
accumulateGrad(
variable,
grad,
new_grad,
1 + !post_hooks().empty() /* num_expected_refs */,
[&grad](at::Tensor&& grad_update) { grad = std::move(grad_update); });
return variable_list();
}
struct TORCH_API AccumulateGrad : public Node {
template <typename T>
static void accumulateGrad(
const Variable& variable,
at::Tensor& variable_grad,
const at::Tensor& new_grad,
size_t num_expected_refs,
const T& update_grad) {
if (!variable_grad.defined()) {
// ...
update_grad(new_grad.detach());
} else if (!GradMode::is_enabled()) {
// ...
} else {
at::Tensor result;
// ...
result = variable_grad + new_grad;
update_grad(std::move(result));
}
}
}最后accumulateGrad的逻辑是,如果tensor variable_grad没有定义,则直接move赋值。如果有定义了,则进行累加。
任务执行完成,标记与清理工作
处理好后,我们回到thread_main循环并再次重复,直到处理好所有任务thread_main循环结束。
thread_main收尾处会调用一些标记与清理工作,如
auto Engine::thread_main(const std::shared_ptr<GraphTask>& graph_task) -> void {
// 前半部分参见上文...
--local_graph_task->outstanding_tasks_;
if (local_graph_task->completed()) {
// local_graph_task->outstanding_tasks_为0或有error退出
// 标记任务完成,lock解锁等操作
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_;
// 放一个dummy task到队列中确保所有者线程是唤醒状态
if (worker_device != base_owner) {
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
}
}
}然后回到Engine::execute,再一路返回到最开始的python_engine.cpp。tensor.backward()调用全流程完成。
取grad值:print(x.grad)
此处调用x.grad直接获取tensor的grad属性,对于tensor的属性,pytorch经由getter获取
template <typename T>
struct GetterBase {
static PyObject* getter(THPVariable* self, void* /*unused*/) {
// ...
return THPVariable_Wrap(T::fn(THPVariable_Unpack(self)));
}
};此处T为PropertyGrad,THPVariable_Unpack解析python object,THPVariable_Wrap将c++的tensor类封装为python的tensor类
随后调用fn方法,并调用到grad()方法:
// torch/csrc/autograd/python_variable.cpp
struct PropertyGrad : GetterBase<PropertyGrad> {
static constexpr const char* name = "grad";
static Tensor fn(const Tensor& t) {
return t.grad();
}
};
// aten/src/ATen/templates/TensorBody.h
class TORCH_API Tensor: public TensorBase {
const Tensor& grad() const {
const Tensor& maybe_grad = impl_->grad();
// ...
return maybe_grad;
}
}随后调用到impl_的grad()方法并调用到autograd_meta_的grad()方法直接获取grad变量
// c10/core/TensorImpl.cpp
const at::Tensor& TensorImpl::grad() const {
// 没有`autograd_meta_`则return空tensor
if (!autograd_meta_)
return impl::GetAutogradMetaFactory()->undefined_tensor();
return autograd_meta_->grad();
}
// torch/csrc/autograd/variable.h
struct TORCH_API AutogradMeta : public c10::AutogradMetaInterface {
const Variable& grad() const override {
return grad_;
}
}总结与review
进行一次autograd全流程,主要步骤有三步
- 创建
requires_grad=True的tensor - 前向计算,构建计算图
- 反向求导(拓扑排序),累加梯度
对于本文用例(mul)来说,计算图全流程可以用下面这张图表示
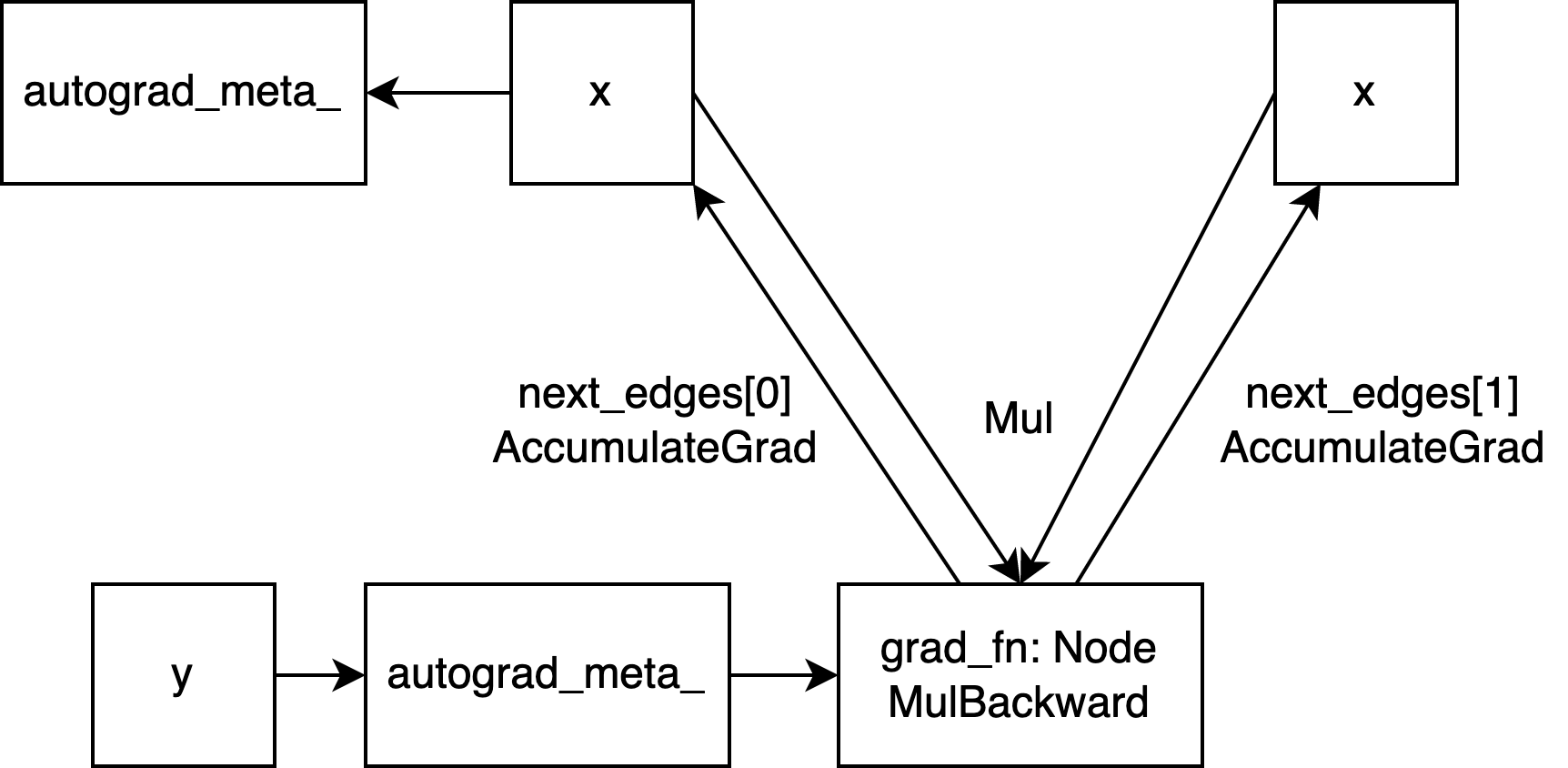
在前向计算中,我们介绍了如何创建grad_fn、edge,构建计算图,并提到了dispatch和structure kernel相关概念。
在反向求导时,我们介绍了engine运行的细节:启动多线程,构建graph_task,thread_main循环,依赖数检查(然后放入read queue),任务队列(ready queue,其中任务线程池调度执行)等,并深入探究了accumulateGrad如何进行累加。
希望本文能帮助你理解pytorch autograd底层运行机制!