Pytorch Compiler Introduction
Summary
本文介绍了 Pytorch 的编译功能,我们从代码示例开始展示使用编译对代码执行的加速效果,随后补充介绍了pytorch FX 相关基础知识,最后整体介绍了 TorchDynamo相关内容,包括Graph、对 Python 字节码的调整、Guard、Cache等。
写在前面:本文档基于 Pytorch 2.1 版本书写,TorchDynamo 是一个持续迭代中的模块,后期版本可能出现与文章示例API不同的情况,但核心思想是一样的。
Overview
torch.compile是在Pytorch2.x中引入的功能,用于更准确地捕获计算图,并加速程序运行。它由Python编写,也标志着Pytorch开发逐渐从C++转向Python。
torch.compile主要依赖以下技术
- TorchDynamo (torch._dynamo):内部API,使用CPython的Frame Evaluation API来安全地捕获PyTorch计算图。
- TorchInductor:默认的
torch.compile深度学习编译器,为多种后端生成高效运行的代码。如对于NVIDIA和AMD GPU,主要基于OpenAI Triton构建。 - AOT Autograd(Ahead-Of-Time Autograd):在编译时期捕获用户级代码以及反向传播。一般来说深度学习框架在运行时执行前向和反向运算,而AOT Autograd允许编译期捕获反向传播,进而使用
TorchInductor加速前向计算和反向传播。
一些常见的后端有:
- 同时支持训练和推理:
inductor:默认的TorchInductor后端cudagraphs:带AOT Autograd的 Cuda 计算图后端ipex:intel-extension-for-Pytorch,CPU 后端onnxrt:基于 ONNX Runtime的训练后端,CPU / GPU
- 支持推理:
tensorrt:onnx-tensorrt,使用 ONNX Runtime来运行 TensorRT 以加速推理tvm:使用 Apache TVM 以加速推理
Getting Started
import torch
import time
def fn(x):
a = torch.cos(x)
b = torch.sin(a)
return b
new_fn = torch.compile(fn, backend="inductor")
input_tensor = torch.randn([1024, 1024, 1024]).to(device="cuda:0")
start_time = time.time()
_ = fn(input_tensor)
torch.cuda.synchronize() # syncronize
original_duration = (time.time() - start_time)
start_time = time.time()
_ = new_fn(input_tensor)
torch.cuda.synchronize()
compiled_duration = (time.time() - start_time)
start_time = time.time()
_ = new_fn(input_tensor)
torch.cuda.synchronize()
compiled_duration2 = (time.time() - start_time)
print(f"Original duration : {original_duration:.6f} seconds")
print(f"Compiled duration : {compiled_duration:.6f} seconds")
print(f"Compiled duration 2: {compiled_duration2:.6f} seconds")
# Original duration : 0.025237 seconds
# Compiled duration : 4.118577 seconds
# Compiled duration 2: 0.010665 seconds在上面的代码中,我们对比了原始函数与编译函数的运行时间,可以看到,在首次开销(初次调用需要的额外初始化或编译的时间)后,我们的函数有了两倍多的加速,这在实际训练场景需要重复执行多次的情况下非常有利。
加速的原因主要有两个,首先,我们通过compile实现了 融合(fusion)。
融合是什么呢? TorchInductor 默认支持Triton kernel,我们通过设置环境变量TORCH_COMPILE_DEBUG=1来观察生成的Triton代码(不同硬件代码可能不同)。
@pointwise(size_hints=[1073741824], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': [], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 1073741824
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = tl.cos(tmp0) # 注意临时变量存储在寄存器中,存取很高效
tmp2 = tl.sin(tmp1)
tl.store(out_ptr0 + (x0 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask)在原始函数中,对于 cos 和 sin 这些 pointwise 的操作,需要先读一次x,计算并写入a,再读一次a,计算并写入b。现在通过融合(fusion),我们只进行了一次读取tl.load到 tmp0,和一次写入tl.store。我们知道在较新的 GPU 中,瓶颈在于内存带宽(GPU 存取数据速度)而非计算(浮点运算速度),因此融合提供了很好的性能优化。
第二,inductor 还提供了对 Cuda graphs 的支持,Cuda graphs 会捕获操作序列(例如内核调用、内存复制等)并保存为图,基于该图可以多次执行相同的操作序列,从而大幅减少启动操作的开销。NVIDIA 还可能对图做一些优化减少同步或改进内存访问模式等进一步增加效率。
FX
FX即PyTorch Flexible eXtensions,在开始具体介绍Dynamo前,我们需要了解一下FX的概念。
FX 是 Pytorch 的一个子库,用于帮助开发者转换nn.Module模型实例为 IR(Intermediate Representation)。IR是更结构化和可分析的图,开发者可以基于 IR 做可视化分析、模型转换和优化(如删除不必要的操作、合并层等),优化后可以通过代码生成转换为 Pytorch 代码或其他格式,便于部署到不同平台和后端。
FX 主要包括三个组件:符号跟踪器(symbolic tracer)、IR、代码生成(Python code generation),我们通过一个例子来展开说明这三个组件
import torch
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
module = MyModule()
from torch.fx import symbolic_trace
# 调用符号追踪,捕获模型语义
symbolic_traced : torch.fx.GraphModule = symbolic_trace(module)
# 图生成——打印IR
print(symbolic_traced.graph)
# Python代码生成
print(symbolic_traced.code)symbolic tracer 会输入一些 fake value(也叫做 Proxies)给模型,对这些proxies的操作会被记录下来
IR 是在符号跟踪期间记录操作的容器,它包含输入、调用点(函数/方法/nn.Module实例)、返回值。如上面的代码会生成以下 IR:
"""
graph():
%x : [num_users=1] = placeholder[target=x]
%param : [num_users=1] = get_attr[target=param]
%add : [num_users=1] = call_function[target=operator.add](args = (%x, %param), kwargs = {})
%linear : [num_users=1] = call_module[target=linear](args = (%add,), kwargs = {})
%clamp : [num_users=1] = call_method[target=clamp](args = (%linear,), kwargs = {min: 0.0, max: 1.0})
return clamp
"""Python代码生成可以帮助我们基于 IR 创建与语义匹配的有效 Python 代码,如上文例子会生成以下的 Python 代码:
def forward(self, x):
param = self.param
add = x + param; x = param = None
linear = self.linear(add); add = None
clamp = linear.clamp(min = 0.0, max = 1.0); linear = None
return clamp这三个组件可以组合使用,也可以单独使用(如单独使用符号跟踪以便于分析模型),是方便开发者的好工具。
Deep Dive to TorchDynamo
TorchDynamo 是一个 Python 层级的 JIT(just-in-time) 编译器,它使用 CPython 的Frame Evaluation API(PEP523)重写 Python bytecode 并提取 Pytorch 操作序列并形成一个FX Graph,然后再使用一个指定的 backend 编译。通过 bytecode 分析创建 FX Graph,将 Python 执行与编译后端结合起来,我们保证了可用性又有好的性能。
下面这张图解释了 torch.compile 的工作原理
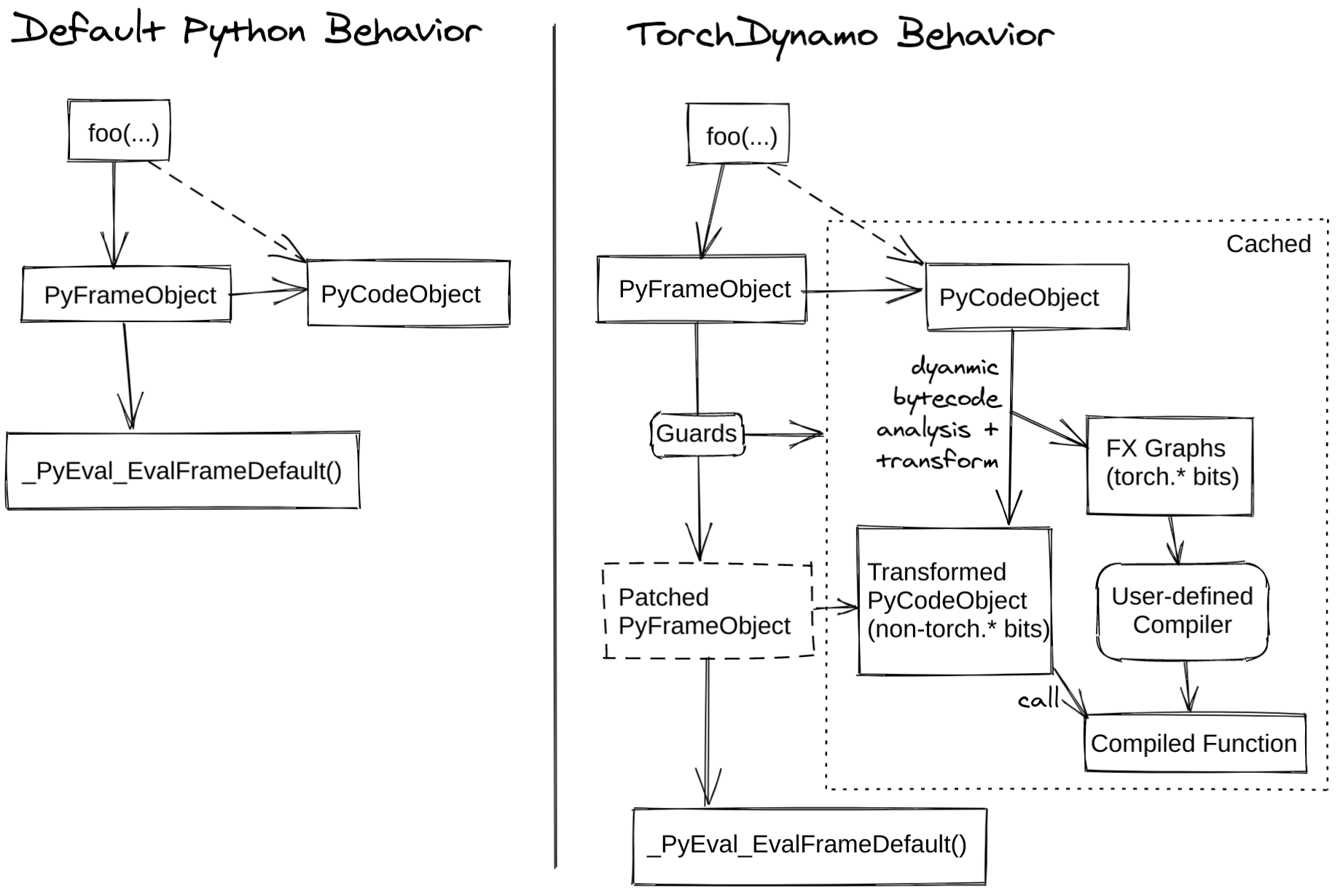
实例引入
from typing import List
import torch
from torch import _dynamo as torchdynamo
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print("my_compiler() called with FX graph:")
gm.graph.print_tabular()
return gm.forward # 返回一个 Python callable 对象
# 装饰器启用 Dynamo 优化
@torchdynamo.optimize(my_compiler)
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))执行上述代码,会得到以下输出:
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ------- ----------------------------- --------------------- --------
placeholder a a () {}
placeholder b b () {}
call_function abs_1 <built-in method abs> (a,) {}
call_function add <built-in function add> (abs_1, 1) {}
call_function truediv <built-in function truediv> (a, add) {}
call_method sum_1 sum (b,) {}
call_function lt <built-in function lt> (sum_1, 0) {}
output output output ((truediv, lt),) {}
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ------ ----------------------- ----------- --------
placeholder b b () {}
placeholder x x () {}
call_function mul <built-in function mul> (b, -1) {}
call_function mul_1 <built-in function mul> (x, mul) {}
output output output ((mul_1,),) {}
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ------ ----------------------- --------- --------
placeholder b b () {}
placeholder x x () {}
call_function mul <built-in function mul> (x, b) {}
output output output ((mul,),) {}这个输出告诉我们my_compiler被调用了三次,生成了三张图:
toy_example到分支前的所有内容:计算x并检查b.sum()是否小于0if的 True 分支:包含b = b * -1和return x * bif的 False 分支:直接是返回值return x * b
Dynamo做了什么?
如果我们想更深入理解在上面的过程中,Dynamo 具体做了什么,可以加入以下代码打印更多日志:
import torch._dynamo.config
import logging
torch._dynamo.config.log_level = logging.INFO
torch._dynamo.config.output_code = True第一个图的输出如下:
torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing toy_example
torch._dynamo.output_graph: [INFO] Step 2: calling compiler function my_compiler
torch._dynamo.output_graph: [INFO] Step 2: done compiler function my_compiler
torch._dynamo.output_graph: [INFO] TRACED GRAPH
# ... graph printed before
torch._dynamo.convert_Frame: [INFO] ORIGINAL BYTECODE toy_example test_graph.py line 17
19 0 LOAD_FAST 0 (a)
2 LOAD_GLOBAL 0 (torch)
4 LOAD_METHOD 1 (abs)
6 LOAD_FAST 0 (a)
8 CALL_METHOD 1
10 LOAD_CONST 1 (1)
12 BINARY_ADD
14 BINARY_TRUE_DIVIDE
16 STORE_FAST 2 (x)
20 18 LOAD_FAST 1 (b)
20 LOAD_METHOD 2 (sum)
22 CALL_METHOD 0
24 LOAD_CONST 2 (0)
26 COMPARE_OP 0 (<)
28 POP_JUMP_IF_FALSE 38
21 30 LOAD_FAST 1 (b)
32 LOAD_CONST 3 (-1)
34 BINARY_MULTIPLY
36 STORE_FAST 1 (b)
22 >> 38 LOAD_FAST 2 (x)
40 LOAD_FAST 1 (b)
42 BINARY_MULTIPLY
44 RETURN_VALUE
torch._dynamo.convert_Frame: [INFO] MODIFIED BYTECODE toy_example test_graph.py line 17
17 0 LOAD_GLOBAL 3 (__compiled_fn_0)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 CALL_FUNCTION 2
8 UNPACK_SEQUENCE 2
10 STORE_FAST 2 (x)
12 POP_JUMP_IF_FALSE 24
14 LOAD_GLOBAL 4 (__resume_at_30_1)
16 LOAD_FAST 1 (b)
18 LOAD_FAST 2 (x)
20 CALL_FUNCTION 2
22 RETURN_VALUE
>> 24 LOAD_GLOBAL 5 (__resume_at_38_2)
26 LOAD_FAST 1 (b)
28 LOAD_FAST 2 (x)
30 CALL_FUNCTION 2
32 RETURN_VALUE
torch._dynamo.convert_Frame: [INFO] GUARDS:
- local 'a' TENSOR_MATCH # ...
- local 'b' TENSOR_MATCH # ...
- global 'torch' FUNCTION_MATCH # ...可以看出,Dynamo 首先 tracing 我们的函数 toy_example 然后进行编译,生成图并输出。此外,输出中也有字节码的变化和Guard的声明
我们首先看字节码:
在原始 Python 字节码中,如 LOAD_FAST 操作用于从本地变量加载值,LOAD_METHOD 和 CALL_METHOD 用于调用方法,BINARY_ADD和BINARY_MULTIPLY用于执行加法和乘法运算等
而 Dynamo 修改了 Python 字节码,对编译过的__compiled_fn_0函数调用替换了原始字节码中计算x的值和检查b.sum() < 0的操作,随后根据返回值真假调用生成的__resume_at_30_1或__resume_at_38_2,即分别对应原始字节码中的两个分支。
__resume_at_xx 函数来自于以下模板,用于在图中断处继续执行代码
__resume_at_<offset>:
... restore stack state if needed ...
JUMP_ABSOLUTE <offset> into toy_example
... original bytecode of toy_example ...通过生成__resume_at_xx,我们强制将要执行的函数在新的 Python Frame(帧)中执行,并递归式地启动 Dynamo 来再次执行捕获过程。
如何理解这个递归?当首次执行toy_example时,Dynamo就启动了一次捕获,并生成优化后的字节码,包括__compiled_fn_0和两个resume函数,当我们进入某个resume函数时,Dynamo会启动类似的过程,来处理resume函数内部可能的其他分支,以此类推,就能处理完所有代码。
Guard
上面的输出中还有包括Guard:
torch._dynamo.convert_Frame: [INFO] GUARDS:
- local 'a' TENSOR_MATCH # ...
- local 'b' TENSOR_MATCH # ...
- global 'torch' FUNCTION_MATCH # ...在这里,如果任意一个 Guard 失败(意味着优化的代码不是安全或正确的,也有可能因为不同的运行时条件失败),图将被重新捕获并重新编译。
在此处TENSOR_MATCH会检查tensor对象的属性如dtype、shape、device、requires_grad、dispatch_key、ndim、sizes、strides等。而FUNCTION_MATCH会检查函数对象的id(obj),有可能检查id(type(obj))等来保证函数调用正确。
Caching
在上面的例子中,Dynamo 能加速的一个重要因素就是 Caching,Caching 不是一个直接的加速因素,但它能阻止重编译。
Dynamo 修改 Python 字节码后,它会进行缓存。当每次接收一个新的 Frame 进行评估时,Dynamo会检查在 Frame 中引用的 objects 是否改变,如果没有,就会直接使用缓存的用户字节码。
流程可以被总结如下:
- Dynamo 接收一个 Python Frame,Frame 里包含代码当前状态与上下文信息
- Dynamo 将 Python 指令优化,生成优化的字节码
- 对于在 (2) 中捕获的对象,Dynamo会创建跟踪对象,包含:跟踪图的对象(
torch.fx.Tracer的一种 internal 实现)和Guard - Dynamo 生成
check_fn函数,这个函数用于检查这些 Guard 对象 - 程序运行遇到关联的代码片段时,调用
check_fn检查在 Cache 中的字节码,如果check_fn返回True,那么直接使用,否则会通过重新编译或裂图(Graph Break)来重新生成优化代码。