Summary: Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
本博客使用
GPT-5翻译,如有冲突请优先参考英文原文
Materials
1. 这篇论文的主要内容是什么?
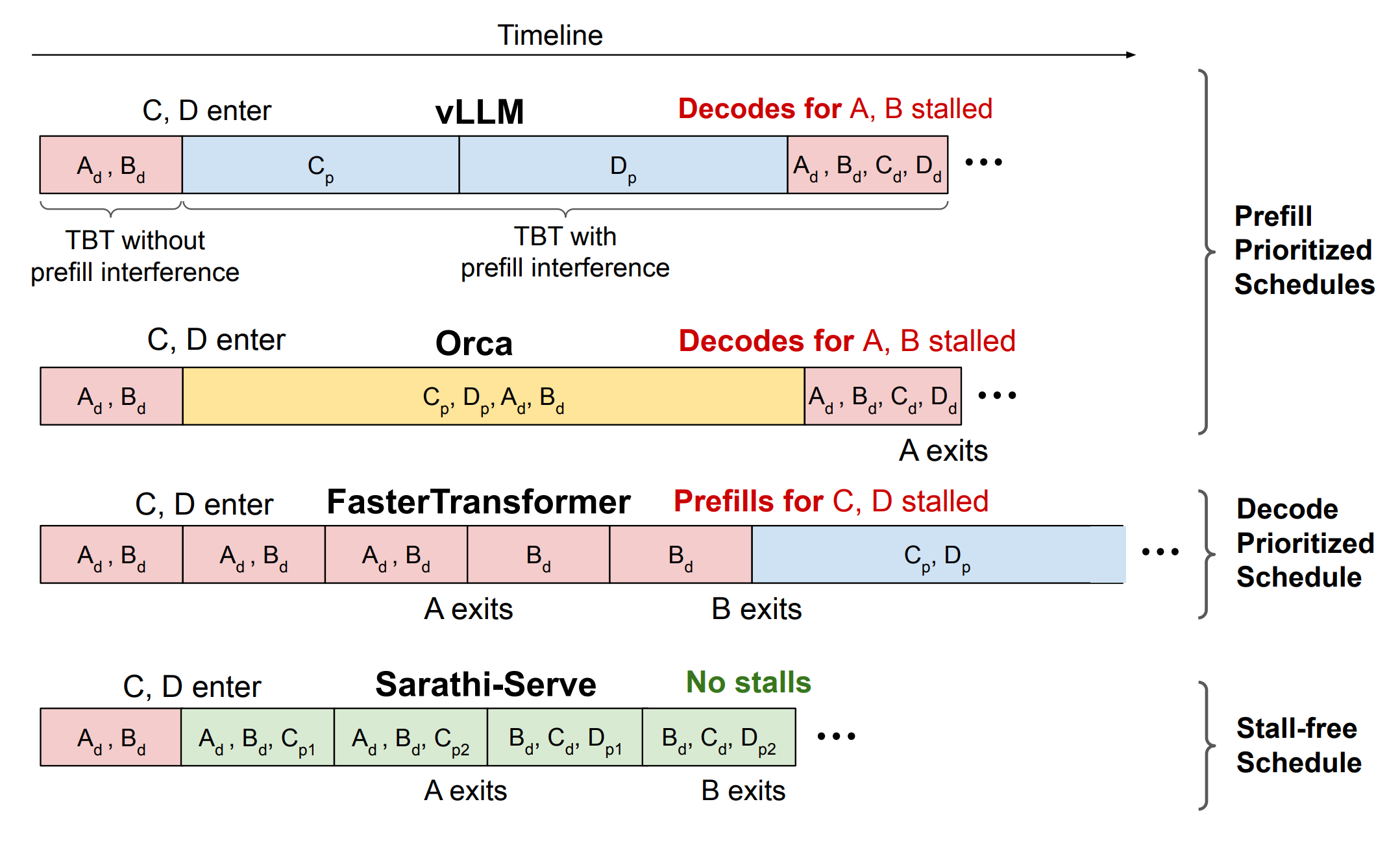
提出Sarathi-Serve,一种在线 LLM 推理调度器,可同时提升吞吐量与尾延迟。
引入分块预填充(chunked-prefills)与无停顿批处理(stall-free batching)。
产生计算负载均匀的混合批(解码 + 小预填充块),避免生成停顿,并在流水线并行(PP)部署中减少流水线气泡。
2. 相较于既有工作,这篇论文的新意是什么?
提出无停顿批处理:先接纳解码,再接纳已部分完成的预填充,最后接纳新的预填充,从而从不暂停解码。
在 vLLM 之上构建的系统化、SLO 感知调度器,使用 FlashAttention v2/FlashInfer 内核;支持 TP/PP/混合并行与丰富的遥测能力。
3. 为支撑论文观点做了哪些实验?
在 P99 TBT 目标(严格 vs 宽松)下测最大可持续 QPS,覆盖 Mistral-7B(1×A100)、Yi-34B(TP-2,2×A100)、LLaMA2-70B(TP-4 + PP-2,8×A40)、Falcon-180B(TP-4 + PP-2,8×A100/2 节点)。
对比 vLLM(最大 batch 32/64/128)与 Sarathi-Serve(token 预算 512/2048);显示在严格 SLO 下 vLLM 受停顿限制。
比较 TP-8 与 TP-4 + PP-2(分别在有/无 Sarathi-Serve 情况),相较跨节点 TP,中位 TBT 降低超过 2×,且容量显著提升。
仅做混合批可降低 TTFT(首个 token 时间),但损害 TBT;仅做分块预填充可改善 TBT,但损害 TTFT;两者结合则可同时降低二者。
4. 这篇论文的不足/限制是什么?
选择 token 预算需要按部署剖析与谨慎的 tile 尺寸对齐;未探讨动态控制。
过小的块会增加 TTFT 并带来额外 HBM 读取。
调度器聚焦于由 SLO 驱动的批处理;公平性、抢占或按租户 QoS并非核心关注点。
结果主要基于 A100/A40 + 100 GbE/NVLink;对其他互连、超长上下文、MoE 或 推测解码的行为未做广泛研究。
5. 在此基础上可行的下一步工作?
基于实时 TBT、批混合与 PP 气泡遥测,采用在线强化学习/反馈控制,在每次迭代自适应调节 token 预算与块大小。
在副本内采用无停顿批处理,在副本间解耦预填/解码(配合轻量级 KV 传输/压缩),进一步压低 TTFT 并提升容量。
与推测解码、KV 压缩/量化及预填缓存集成,降低分块开销与 HBM 流量。
附录
TBT(Time-Between-Tokens):解码阶段两个相邻输出 token 之间的耗时,通常跟踪 P99 以捕获尾延迟。
Token 预算(τ):每次迭代处理的 token 总上限(解码 + 预填块),以满足 TBT SLO。
迭代级批处理(Iteration-level batching):允许请求在每次模型迭代时加入或离开批次。
请求级批处理(Request-level batching):在接纳新请求前,先将一组固定请求运行至完成。
按租户 QoS(Per-tenant QoS):确保每个租户获得指定性能(延迟/吞吐)或资源份额的策略。
遥测(Telemetry):用于监控性能与指导调优的指标与追踪。