Summary: SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
目录
本博客使用
GPT-5翻译,如有冲突请优先参考英文原文
Materials
1. 这篇论文在讲什么?
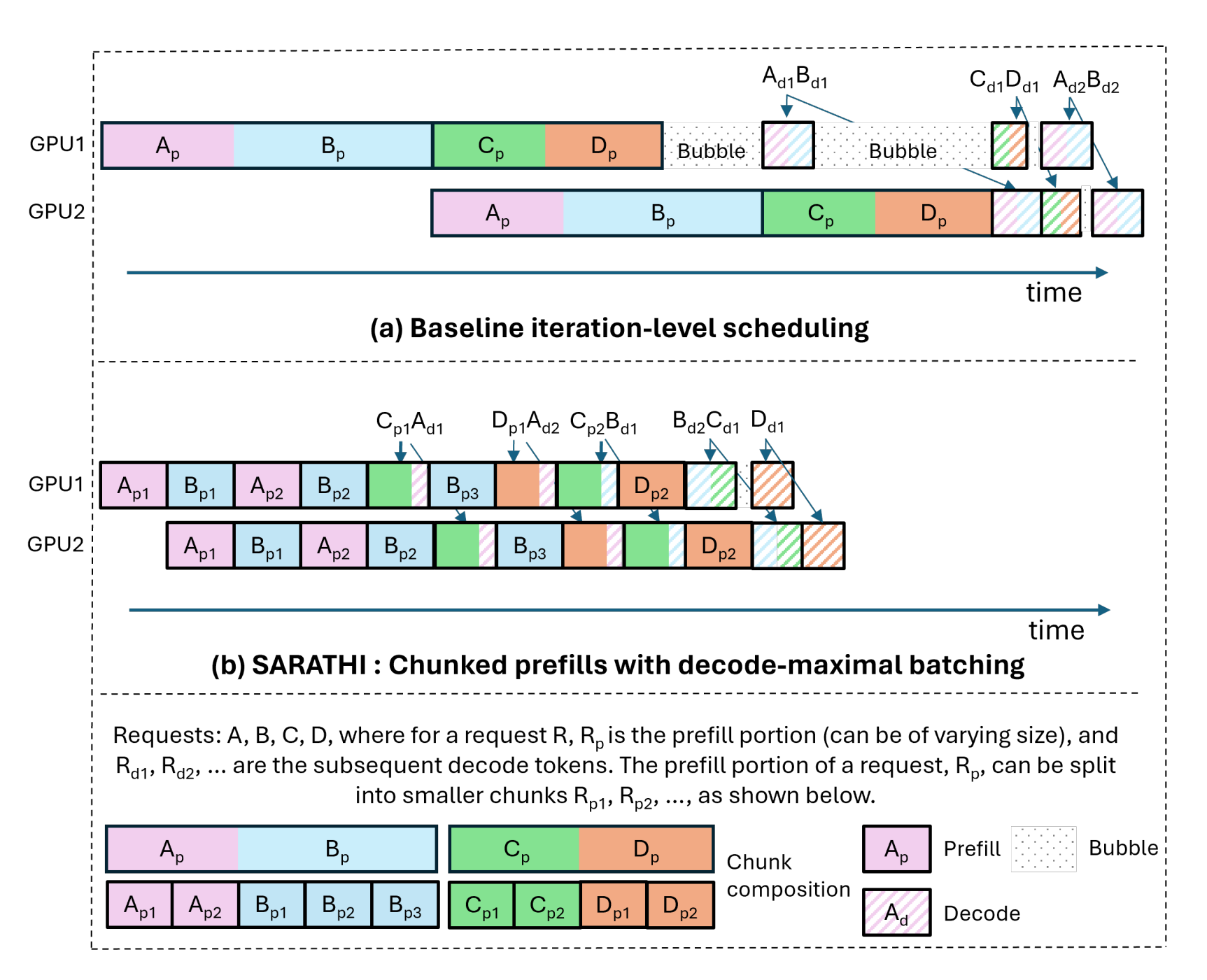
- 提出 SARATHI:一种通过 分块预填充(Chunked-prefills) 与 解码最大化批处理(Decode-maximal batching) 让 LLM 推理更高效的调度/执行方法。
- 其核心是在通常 受内存带宽限制 的解码阶段提升 GPU 利用率,并通过让微批统一且更“算力密集”,消除流水线并行(PP)的气泡。
2. 相比既有工作,这篇论文的新意是什么?
- 通过把预填充和解码的线性层融合为每个批次一次矩阵乘,把解码从内存受限变为计算受限。
- 引入分块预填充:把一次请求的预填充切成等计算量的块,并用因果掩码保证正确性。
- 引入解码最大化批处理:每个批次由一个预填充块 + 尽可能多的解码组成,让解码“搭载”预填充的计算峰值。
- 给出瓦片量化感知的分块选取(将块大小与解码数对齐到 GPU 矩阵乘瓦片尺寸),以避免性能悬崖。
3. 为支撑论点做了哪些实验?
- 逐算子/逐 token 的耗时与算术强度分析(LLaMA-13B / A6000),验证在实际批大小下解码为内存受限。
- 纯解码最高提速可达 约 10×;端到端吞吐提升至多 1.33×(LLaMA-13B/A6000)、1.25×(LLaMA-33B/A100)。
- 对批大小、序列长度(1K–3K)、P:D 比、**块大小(128/256/512)**做扫描;发现峰值大致在
P:D ≈ C/(B−1)且位于瓦片尺寸的整数倍附近。 - 在不同序列长度与 P:D 比上,SARATHI 优于 Orca 的最佳情形(如吞吐提升 1.23–1.27×),并显著超越其最差情形。
- 在 PP 中(GPT-3,64×A100),气泡时间中位数降低 6.29×;吞吐相对 TP+PP 基线提升 1.91×,相对仅 TP 副本提升 1.48×。
- 证明256/512 的块大小可把预填充损失限制在 ≤20%/≤10%;而 64 这类小块若没有足够的解码重叠,反而有害。
4. 这篇论文的不足/局限是什么?
- 主要关注吞吐量;未与尾延迟、排队与公平性联动优化——生产环境仍需这些目标。
- 块大小选择仍依赖离线调参;缺少在 P:D、负载或硬件变化下的自适应在线策略。
- 假设各请求 token 数相近,而真实工作负载的序列长度高度可变。
- 在极长上下文(10^4–10^5)下的有效性不明,因注意力开销二次增长。
- 主要加速解码;当预填充占主导时,整体收益受限。
5. 合理的后续工作?
- 做在线学习/自动调参器,在变化的 P:D 与到达模式下,联合优化吞吐与延迟/QoS的块大小与批组成。
- 做真实集群实验,验证气泡抑制与每 token 成本,并与仅 TP 的基线对比。
- 将抢占/公平调度(如 FastServe 风格)与解码最大化批处理协同。
- 更深入的线性算子融合、瓦片感知的数据布局,以及针对混合预填充+解码批次的 BF16/INT 量化路径优化。
附录
- 迭代级调度:一种批处理策略,请求可在每次迭代加入/离开正在运行的批,而非仅在批次之间(源自 Orca)。
- 吞吐饱和:当批/序列继续增大也无法再提升 token/s,因为 GPU 已被充分利用的点。
- P:D 比:工作负载或批中的**预填充 token(P)与解码 token(D)**之比。
- FastServe:面向更低完成时间的 LLM 抢占式调度系统。