2025 Technical Notes(2)
Pytorch
Caching Allocator
为什么我们需要 Caching Allocator?
关键点在于减少昂贵的 Cuda APIs cudaMalloc and cudaFree的调用
cudaMalloc会阻塞CPU直到分配成功,返回一个显存指针cudaFree会阻塞(sync)直到所有可能使用这片内存的stream 操作全部完成
调用malloc时如果没有足够缓存怎么办?
先尝试free合并显存,没有的话再调cuda_malloc,设备内存还不足可能就报错cudaErrorMemoryAllocation
注意:malloc类似于一种best match,不会返回太大的block,避免过多split
类似地,调用free的时候会不会立刻调cudaFree,而是将块标记为free并加入free list
process_cross_stream_delayed_free函数会处理之前record 的stream event,必须将这个块的所有操作都完成,才标记可以free,防止跨流问题。
在必要的时候empty_cache()等方式会把free list的内存cudaFree返还
NLP
Skip-Gram
skip-gram的核心思想:输入一个目标词(中心词w),然后在指定大小的context窗口内,预测左右各window个词
目标是最大化它生成上下文词的条件概率 P(context | w)
流程:
- 预处理语料:分词、去除无用符号等,还有词典截断(词频过低的视为unknown)
- 生成训练样本:如我 喜欢 吃 苹果,喜欢为中心词,window=2:生成训练对((“喜欢”, “我”), (“喜欢”, “吃”), (“喜欢”, “苹果”))
- 模型结构与预测
初版word2vec中,简单的两层神经网络;输入采用one hot向量(或索引查表的方式)表示中心词然后过hidden layer;再预测输出层的概率分布(预测的上下文词),目标是让正确上下文词和预测的上下文词内积尽可能大
如何做概率分布呢?softmax,但我们知道softmax要去比较所有词的概率算e,那么词表很大的话效率会极低。
所以我们使用了**负采样(negative sampling)**的方法,只抽取十几个无关的负例词,和正例对比即可(即把总集合当初不是全部词表,而是只有这十几个负例+当前正例)。然后我们希望正例得分尽可能高,负例得分尽可能低。
注意:负采样不是真实语料,是随机抽取的单词组成的无意义词组
为什么这种方法有效?因为训练是反复迭代的,每个中心词都会有一批负例,随着迭代次数增多其实还会见到大多数词。
skipgram的参数量?假设词表大小为V,embedding大小为d
那么总参数量为V * d *2 ——注意:每个词作为中心词有一个向量 V *d,作为上下文词的时候也有一套向量v*d。如果输出词表大小记为 ∣C∣,那么总参数量描述为 V *d + C * d也可以
Flash attention
Sequence Parallelism本质是序列做切分并行
flash attention出来之前,O(N^2)激活值内存消耗过大,所以序列并行每个GPU只处理自己的那段序列。但由于self attention依赖位置信息,所以需要all-gather汇总其他设备的部分来算全局注意力分数,反向时也需要reduce-scatter来局部梯度归约。通常会设计让通信与计算交叠来尽快加速
flash attention出来之后,self attention计算变为O(N),但sequence parallel仍然有意义——其他MLP等还是很大显存占用(特别是最后logits词表大小的概率分布,它有N*V的memory,llama3有128K词表,8k的sequence length!如果开了sequence parallel,这个可以按线性减少)
Flash attention实现参考(并没有提速效果,只是表示并行的思想):
import torch
import math
def attention(Q, K, V):
d = Q.shape[1]
scores = torch.matmul(Q, K.transpose(0, 1)) / math.sqrt(d) # [seq_len, seq_len]
weights = torch.softmax(scores, dim=1) # 每个 query 的得分在所有 key 上归一化
return torch.matmul(weights, V) # [seq_len, dv]
def flash_attention(Q, K, V, block_size):
seq_len, d = Q.shape
dv = V.shape[1]
output = torch.zeros(seq_len, dv)
for i in range(0, seq_len, block_size):
Qi = Q[i: i + block_size] # [B, d]
accumulator = torch.zeros(block_size, dv) # 用于累计加权后的结果(分子部分)
normalization = torch.zeros(block_size, 1) # 分母部分
running_max = -float('inf') * torch.ones(block_size, 1)
for j in range(0, seq_len, block_size):
Kj = K[j: j + block_size] # [B_j, d], B_j 与 B 相同
Vj = V[j: j + block_size] # [B_j, dv]
# 计算缩放点积注意力得分
scores = torch.matmul(Qi, Kj.transpose(0, 1)) / math.sqrt(d) # [B, B_j]
# 例如 [[1, 2], [3,4]],这里[1,2]表示第一个query对于所有key的得分,所以为什么下面max dim=1,即要求当前query的最大值
local_max, _ = scores.max(dim=1, keepdim=True) # [B, 1]
new_max = torch.maximum(running_max, local_max) # [B, 1]
# log-exp-sum
# We want `e^(s - running_max)` -> `e^(s - new_max)`
# So e^(s - new_max) = e^(s - running_max) * e^(running_max - new_max)
accumulator *= torch.exp(running_max - new_max)
normalization *= torch.exp(running_max - new_max)
running_max = new_max
exp_scores = torch.exp(scores - new_max) # max-shift
accumulator += torch.matmul(exp_scores, Vj)
normalization += exp_scores.sum(dim=1, keepdim=True)
# output里存的是当前block Q,与所有K和所有V计算的结果
output[i: i + block_size] = accumulator / normalization
return output
seq_len, d, dv, block_size = 4, 3, 3, 2
Q = torch.randn(seq_len, d)
K = torch.randn(seq_len, d)
V = torch.randn(seq_len, dv)
output_flash = flash_attention(Q, K, V, block_size)
assert torch.allclose(attention(Q, K, V), output_flash, atol=1e-4)
print("Flash attention:", output_flash.shape)RL
普通RL:RLHF——人类反馈reward
思维链RL:引导模型生成中间推理步骤来提升表现。
- 数据:问题、思维链和答案的三元组数据集。
- 训练:用数据对LLM(pretrained) 进行微调
- 推理:Let’s think step by step等提示词鼓励模型逐步推理
Deepseek使用GRPO替代了PPO
Proximal Policy Optimization (PPO) :强化学习策略梯度方法
通俗易懂的解释:学生解题,老师打分,学生根据打分调整解题方法。但为了防止调整太多,构造了一个clipping来防止过大的改变
Group Relative Policy Optimization (GRPO)
通俗易懂的解释:多个学生给出多个答案,然后放在一起比较,比平均好的答案被鼓励。这样既不需要额外的老师来评价,减少计算。又能让更新更稳定
Deep Learning
常识
单纯剪枝(设0)无法减少模型参数量。要真正减少模型参数量,提高训练速度,一般是把剪枝后的权重存储为稀疏格式处理,如CSR(Compressed Sparse Row)、CSC(Compressed Sparse Column)或COO(Coordinate)等。另一种方式是按channel剪枝,然后重构整个layer(如conv或linear),注意上下游shape也要对应调整
dynamic batching——动态批处理:多个独立的推理请求合并成一个批次,一次GPU操作执行
- 缓存请求,存入缓冲区等待一个短暂的时间窗口
- 时间窗口结束后或已经积攒了请求后,合并一个批次请求
例如:
[seq_len, embedding_dim]的tensor,进行padding让seq_len相同(这里也有很多衍生技术,如不同seq_len分组放到一起等,然后stack成[batch, seq_len, embedding_dim]的tensor) - 合并后的tensor启动GPU kernel计算
- 拆分输出,确保请求独立且正确的响应
Pin memory: 数据加载到一块CPU上锁页,这块内存不会被OS交换到硬盘上,所以GPU可以更快地从这块固定的内存取数。
计算图:inplace算子不能对leaf node使用(计算图破坏,报错a leaf Variable that requires grad is being used in an in-place operation.),但中间变量可以。此外,如果+= tensor(requires grad),inplace算子也是能正常算梯度给这个tensor的
FLUX.1-schnell 12B,文生图模型:基于latent adversarial diffusion distillation,1~4个步骤即可生成,非常快。FLUX.1‑schnell 属于 FLUX.1 模型系列中的一员,与 FLUX.1‑dev、FLUX.1‑pro 等其他变体相比,FLUX.1‑schnell 特别强调速度优化
latent adversarial diffusion distillation:LADD 潜在对抗扩散蒸馏
简单理解:一个厉害的老师能很多步骤生成真实图像;LADD就是让老师教给学生在一个很短steps里生成真实图像
- L:latent,在latent space工作
- Distillation:蒸馏知识
- adversarial:加入了一个对抗损失(来自discriminator)
TRELLIS是 3D asset生成模型。1~2B参数,需要16GB显存。基于SLAT来对3D asset信息统一的表示,同时捕捉几何结构和外观信息,从而生成模型
SLAT:Structured Latent Representation 统一的结构化潜在表示(把输入(图像、文本等)embedding为一个紧凑的、高维向量,和传统embedding不同,它保留了空间或层级结构信息,使得局部的几何细节和全局形状都在编码中得到体现)
stack 广播操作 tensor
stack方法与cat不同的地方在于,它会创建一个新维度
例如:
a = torch.tensor([1, 2, 3])b = torch.tensor([4, 5, 6])
result0 = torch.stack([a, b], dim=0) # 即变成了[2,3]的tensor(dim=0即将输入的所有tensor组装在一起)
tensor([[1, 2, 3],
[4, 5, 6]])
result1 = torch.stack([a, b], dim=1) # 即在第二个维度插入了新维度(dim=1,会每个元素间构成一个新维度)
tensor([[1, 4],
[2, 5],
[3, 6]])一个更大一点的示例:
import torch
# is_seg_intersect 已支持批量输入,输入形状 [batch, 2, 2],返回 [batch] 的布尔张量
def is_seg_intersect(seg_1: torch.Tensor, seg_2: torch.Tensor) -> torch.Tensor:
pass
def is_traj_intersect(traj_1: torch.Tensor, traj_2: torch.Tensor) -> bool:
"""
traj_1, traj_2 均为形状 [N, 2] 的二维轨迹
[[x0, y0], [x1, y1], ... [xn, yn]]
"""
# traj_1[:-1] 读取[[x0, y0], [x1, y1] ... [x_n-1, y_n-1]] traj_1[1:]] 读取 [[x1, y1] ... [xn, yn]]
# 读取后,两个都是[n-1, 2]的shape,然后这两在dim=1上堆叠,就构成了
# [[[x0,y0], [x1, y1]], [[x1,y1], [x2, y2]], ... , [[xn-1, yn-1], [xn,yn]]]
# segs1 shape: [n1-1, 2, 2]
segs1 = torch.stack([traj_1[:-1], traj_1[1:]], dim=1)
# segs2 shape: [n2-1, 2, 2]
segs2 = torch.stack([traj_2[:-1], traj_2[1:]], dim=1)
# 如果任一轨迹不足两个点,则无法形成线段,返回 False
if segs1.shape[0] == 0 or segs2.shape[0] == 0:
return False
# 利用广播构造所有可能的线段组合
# broadcast segs1 to [n1-1, n2-1, 2, 2]
segs1_expanded = segs1.unsqueeze(1).expand(-1, segs2.shape[0], -1, -1)
# broadcast segs2 to [n1-1, n2-1, 2, 2]
segs2_expanded = segs2.unsqueeze(0).expand(segs1.shape[0], -1, -1, -1)
# 将两者 reshape 为批量输入 [batch, 2, 2],其中 batch = (n1-1)*(n2-1)
segs1_batch = segs1_expanded.reshape(-1, 2, 2)
segs2_batch = segs2_expanded.reshape(-1, 2, 2)
# 批量调用 is_seg_intersect,返回的结果形状为 [batch] 的布尔张量
intersect_result = is_seg_intersect(segs1_batch, segs2_batch)
# 只要有任意一对线段相交,则轨迹相交
return intersect_result.any().item()BMM代替conv
场景:比如conv算子是for循环写的,执行很慢,我们希望tile的思路调用高效的BMM代替conv。(有时也叫im2col)
import torch
import torch.nn.functional as F
def conv2d_bmm(input: torch.Tensor, weight: torch.Tensor) -> torch.Tensor:
# input: (N, C_in, H, W) = (5, 1, 4, 4)
# weight: (C_out, C_in, kH, kW) = (2, 1, 2, 2)
N, C_in, H, W = input.shape
C_out, C_in_2, kH, kW = weight.shape
assert C_in_2 == C_in
stride, padding = 1, 0
H_out = (H + 2 * padding - kH) // stride + 1 # 3
W_out = (W + 2 * padding - kW) // stride + 1 # 3
# (N, C_in, H_out, W, kH) -> (5, 1, 3, 4, 2)
tmp = input.unfold(2, kH, stride)
# (N, C_in, H_out, W_out, kH, kW) -> (5, 1, 3, 3, 2, 2)
input_unf = tmp.unfold(3, kW, stride)
# permute to (N, C_in, kH, kW, H_out, W_out) # (5, 1, 2, 2, 3, 3)
input_unf = input_unf.permute(0, 1, 4, 5, 2, 3).contiguous()
# view to (N, C_in * kH * kW, H_out * W_out) (5, 4, 9)
input_unf = input_unf.view(N, C_in * kH * kW, H_out * W_out)
# view weight to (C_out, C_in * kH * kW) # (2, 4)
weight = weight.view(C_out, -1)
# broadcast weight to (N, C_out, C_in * kH * kW) # (5, 2, 4)
weight_expanded = weight.unsqueeze(0).expand(N, -1, -1)
# output: (N, C_out, H_out * W_out) # (5, 2, 4) @ (5, 4, 9) -> (5, 2, 9)
output = torch.bmm(weight_expanded, input_unf)
# view output to (N, C_out, H_out, W_out) # (5, 2, 3, 3)
return output.view(N, C_out, H_out, W_out)
if __name__ == "__main__":
N, C_in, H, W = 5, 1, 4, 4
C_out, kH, kW = 2, 2, 2
x = torch.randn(N, C_in, H, W)
weight = torch.randn(C_out, C_in, kH, kW)
output = conv2d_bmm(x, weight)
output_conv = F.conv2d(x, weight, stride=1, padding=0)
assert torch.allclose(output, output_conv)vLLM
vLLM:专门为LLM推理加速设计的开源服务框架
KV Cache
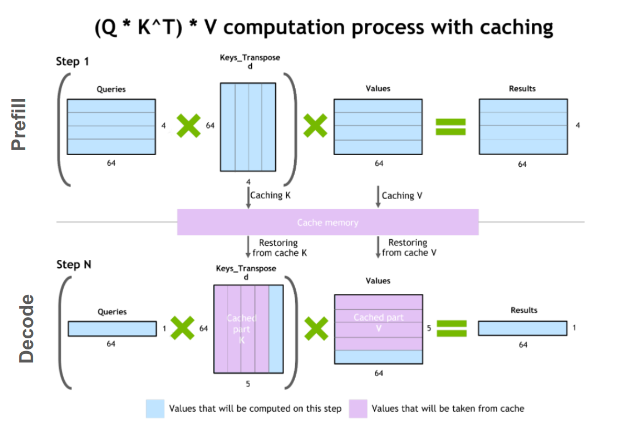
背景:传统方法中,每一步generate都要重新计算所有token的Q K V,推理效率极低。所以我们应用cache,将每一层的K和V缓存下来,后续新token生成时只需要计算新token的K和V并与缓存内容拼接即可。
自回归模型(Autoregressive)阶段:
启动阶段(prefill):基于prompt一次性算出所有token的K和V,初始化K V cache
生成阶段(decoding):每生成一个新token,只计算该Token的 QKV,然后将新计算出的KV添加到cache中,然后用完整的KV cache计算新token的attention分数,得到结果
KV cache优化点在哪?
避免重复的QKV计算:假设没有KV cache,比如已经生成了t个token,生成t+1个token时,需要对这t+1个token都计算一遍QKV。而如果使用KV cache,那么每生成一个token,都将该token的K和V加入cache,之后就可以避免之前t个token的KV重复计算
attention重复计算:假如没有KV cache,那么每步计算attention矩阵大小为
(t+1) * (t+1)规模。而如果有KV cache的话,只需要将新token的Q和缓存中所有KV(包括新token自己的KV)计算即可,即(t+1) * 1规模。注意:旧token生成的输出在GPT language modeling中本身是看不到未来的词的,不依赖后续的token。换句话说,新token 生成不影响旧token的输出。
公式:y = softmax(q_new * K.T / dk^0.5) @ V,具体shape见图
PagedAttention
传统LLM推理框架为每个请求分配一定尺寸的KV缓存,随着token的增加,KV缓存不断增长。
PagedAttention 将每个请求的KV缓存划分为多个固定大小的逻辑块(page),然后通过page table mapping到具体的内存单元,按需分配内存,又能实现请求间的内存共享。
推理过程中,生成过程包含prefill(处理prompt)和decode阶段(逐步生成token),利用动态内存分配,逐步生成token的过程可以利用缓存
dynamic batching
不同请求的输入合并到同一个批次处理。
细分策略:Continuous Batching,每个推理只生成一个token,使得结果立刻返回(流式处理)。Continuous Batching将推理分为一个个迭代步骤,每个迭代中可以不仅处理当前批次的请求,还允许新请求动态加入。
这两个一起用,支持了多个客户端同时流式处理
架构
LLMEngine:vLLM核心模块,接受请求,构造SequenceGroup ,将infer抽象成一个个step。
Worker:每个worker对应一个GPU,集合了CacheEngine
此外,vLLM支持多种硬件和多种主流LLM。
补充:attention里 Q、K、V矩阵是怎么得到的?Q=XWq,K=XWk,V=XWv。这里 X 是[seq_len, hidden_dim]的一个tensor。
其他常用知识
分布式存储HDFS(Hadoop Distributed File System):Hadoop的核心组件,将文件划分为多个块(如128MB)并默认三份备份,不是Raft等强一致性算法,而是最终一致性(eventual consistency)
Apache Spark:基于内存计算的分布式数据框架,能高效处理大规模数据
- 数据清洗和预处理:从HDFS、S3等读取log,利用DataFrame等进行清洗、去重和转换
- 数据聚合和统计分析:用Spark SQL对数据进行复杂查询和聚合操作,如访问量,用户行为统计等
- 离线ML,集成了MLlib等库,数据用于离线机器学习模型
canary deployments——金丝雀部署,即灰度发布,生产环境中逐渐将新版本推给一小部分用户或服务器,逐渐增加比例直到新服务完全部署
ELK Stack(elasticsearch + logstash + kibana)
EFK:elastic search + fluentd + kibana。logstash更强大,fluentd更轻量
Blue-green deployment蓝绿部署,有点像test和prod的区分,但蓝绿环境更多是强调prod两套系统。
cherry pick:选一个或几个应用到当前分支
rebase:将一整个分支的提交历史移动到另一个分支,有点像每个commit的自动化cherry pick
例如:
A(共同祖先) --- B --- C (feature)
/
D --- E --- F (master)
->
B' --- C' (feature)
/
A --- D --- E --- F (master)
# 注意:B和B'提交的内容一样,但sha不一样。找不到历史记录了,所以一般都不用rebase标准差比方差好:与原数据相同量纲:如数据是人身高,方差单位是平方厘米,标准差仍然是厘米,也更符合直觉
标准差还有3 sigma定律异常检测:68-95-99.7对应三个sigma
shared_ptr 引用计数,引用计数的更新是线程安全的,对同一内存的并发读写需要外部同步;unique_ptr 独占所有权,没有引用计数,不支持拷贝和赋值。
System Design
短视频审核场景
背景:用户在短视频平台上传视频,系统需要在几秒内对视频内容进行审核,判断是否存在暴力、色情、敏感图像或其他违规内容,以便后续人工复核或直接拦截违规视频。
我们划分为3块
1、data
data层面,输入为短视频,最先考虑的应该是标题、标签等文本,转化为embedding。然后分级处理,如果标题已经有问题倾向则先打回然后进入详细分析(人工审核等),如果没有的话我们需要提取关键帧用CLIP提取embedding特征,并对audio做embedding获取特征做简单分析
输入可能有很多(高并发),可以使用kafka消息队列处理。
补充:存入s3或ceph等对象存储
2、model
提取embedding后,假设已经有一个nn(如果训练的话还需要离线数据集先训一个nn,然后分布式训练 scale)
我们会期待将nn部署得高效一点,如量化、剪枝、知识蒸馏等策略压缩模型大小,然后nn对embedding信息输入输出是否有问题
补充:batching等方式聚合请求一起访问 补充:RDMA怎么做? 1、选择支持RDMA的网卡,部署InfiniBand 或RoCE(RDMA over Converged Ethernet)环境,然后设计网络拓扑结构, 2、注册RDMA缓冲区,使得RDMA NIC 能够直接访问这部分内存而不需要CPU(GPU也可以注册进这个缓冲区实现高速互联) 3、利用 RDMA 的 one-sided 操作(如 RDMA Write 和 RDMA Read)直接在缓冲区进行数据交换,避免TCP/IP大量数据交互
3、deploy
将模型container化打成image,然后部署在kubernetes上,部署好CICD可以一键发布。
同时提供三个环境,dev、test和prod,每个环境测试通过后发布到下一个环境保证模型质量。
同时prod不断收集新的数据让数据回流便于之后训练更新
自动驾驶场景
针对自动驾驶系统,如何设计一个实时数据处理和模型更新的系统,以确保模型能够快速适应新的环境和情况?
从三个方面着手:
1、data 分为离线数据和在线数据两种。离线数据可以offline预处理然后用于模型训练和更新,在线数据比如路况信息等需要实时推送给用户。
为了满足高并发低延迟的需求,我们可能用kafka消息队列批处理等方式
补充:数据闭环机制——数据采集-> 数据回流->数据标注-> 模型训练 -> 测试验证
多模态数据融合,考虑不同传感器的多模态数据(摄像头、激光雷达等)
2、model 自动驾驶模型一般不需要从头训练,更多是微调。对于dev的模型我们可以用离线数据微调
对于在线model我们尽量不直接推送更新以保证安全
补充:Federated Learning,FL联邦学习。在保护数据隐私的前提下,将模型训练下沉到数据源端。在本地进行训练,然后将参数发送到中央服务器聚合。这样解决了数据隐私和安全性问题。
3、deploy
可以分为dev、test、prod三个环境的model,满足条件推送到下一个level的环境。
然后发布的时候可以考虑灰度发布而不是一把全部发布
使用prometheus和grafna进行实时数据监控,EFK体系(ES、fluentd、kibana)日志管理等
补充:自动驾驶安全性至关重要,所以一定要有冗余机制(比如模型挂了,有人工硬规则刹车等),确保故障时有序运行。
注意:自动驾驶系统要充分利用边缘计算能力,在本地实现数据处理和模型推理
常识补充:OTA(over the air)空中下载,通过无线通信技术远程更新设备的软硬件