Summary: Efficiently Modeling Long Sequences with Structured State Spaces
Materials
1. What is the paper about?
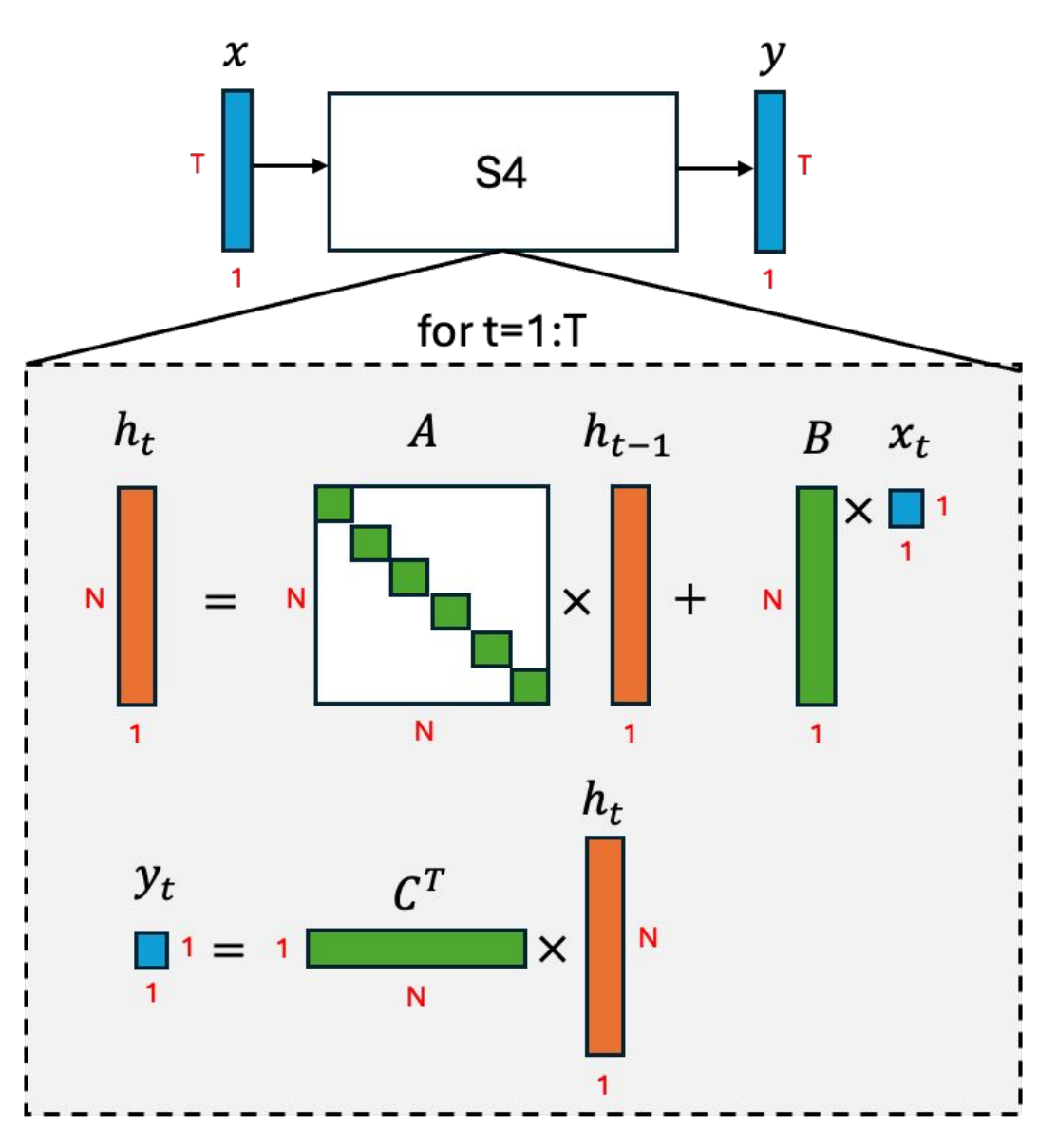
(RNN-like view)
Proposes S4 (Structured State Space Sequence Model), which makes State Space Models (SSMs) practical for very long sequences.
Unifies three views of SSMs—Continuous, Recurrent (RNN-like), and Convolutional, showing how to compute them efficiently and stably.
Targets long-range dependencies (LRDs) using HiPPO-based state matrices while achieving near-linear time and memory.
2. What is new about this specific paper, compared to prior work?
NPLR parameterization decomposes the HiPPO matrix as Normal + Low-Rank ($A = V\Lambda V^* - P Q^*$), enabling well-conditioned diagonalization.
Frequency–domain kernel computes the SSM convolution kernel by evaluating a truncated generating function(Lemma C.3).
Woodbury(Algorithm 1: 3) + Cauchy reduction(Algorithm 1: 2) handles the low-rank correction, reducing the problem size to near-linear.
3. What experiments were run to support the arguments in this paper?
S4 achieves up to ~30× faster training and ~400× less memory than LSSL; speed/VRAM comparable to Performer/Linear Transformer.
S4 attains SOTA across all 6 tasks in Long Range Arena (LRA), including solving Path-X (length 16,384) where prior models failed
98.3% accuracy on raw 16k-sample inputs for Raw speech classification (SC10)
*20.95 ppl, for WikiText-103, ~60× faster generation.
Ablations (CIFAR-10, ≤100K params) shows that Random NPLR alone is not enough, HiPPO+NPLR (full S4) wins
4. What are the shortcomings/limitations of this paper?
Requires specialized kernels (Cauchy multiplies, FFTs, NPLR machinery); harder to implement/optimize than standard conv/attention
While strong, S4 does not surpass top Transformers on large-scale language modeling
Many vision results treat images as 1-D sequences; lacking native 2-D inductive bias can be suboptimal for some vision tasks.
Choice of state size (N), step size, and HiPPO variant still hyperparameter-heavy; limited guidance on automatic selection.
5. What is a reasonable next step to build upon this paper?
Combine S4 with local/global attention or convolutions for Hybrid models
Pretrain larger S4 backbones on language/audio with modern recipes to test competitiveness at scale.
Design 2-D/ND SSM kernels (avoiding flattening) for vision, video, and spatiotemporal forecasting.
Optimized GPU/TPU ops for Cauchy and memory-efficient recurrence for long-context decoding.
Appendix
- SSM (State Space Model): A linear dynamical system that maps input
u_tto outputy_tvia a hidden statex_tusing matrices &A, B, C, (D)& - HiPPO: A family of specially structured (A) matrices that provably compress and track recent history, giving SSMs strong long-range memory
- Path-X: The hardest LRA task requiring reasoning over a flattened image (length 16,384) to decide if two markers are connected