Overview of PyTorch Distributed Training
Summary
This document provides a comprehensive overview of distributed training capabilities within PyTorch. Covering the core components of torch.distributed, it delves into Distributed Data-Parallel Training (DDP), RPC-Based Distributed Training, and Collective Communication (c10d). The discussion encompasses various communication operations, backends, and architectural insights into PyTorch’s distributed framework.
Introduction
torch.distributed mainly consists of three core components:
- Distributed Data-Parallel Training (DDP): Accelerating the training process by parallel processing data across multiple computing devices.
- RPC-Based Distributed Training (RPC, Remote procedure call): A supplement to DDP, especially suitable for situations where direct data parallel training is not available.
- Collective Communication (c10d): A communication library that underpins DDP and RPC. Typically, users wouldn’t call this library directly but would use DDP and RPC for distributed training instead.
Data Parallel Training
Data parallel training mainly includes the following cases:
- Single-machine multi-GPU training (DP): DP is used to speed up training by leveraging multiple GPUs on a single machine. It’s easy to implement with minimal code changes, but has lower performance due to GIL (Global Interpreter Lock).
- Single-machine multi-GPU training (DDP): DDP is used to further accelerate training with multiple GPUs on a single machine, albeit requiring more code modifications.
- Multi-machine multi-GPU training (DDP + launching_script): To take advantage of multiple GPUs across multiple machines, this method should be used.
- Multi-machine multi-GPU training with dynamic resource adjustments and error recovery: Utilize torch.distributed.elastic.
torch.nn.parallel.DistributedDataParallel
Compared to DP, DDP requires additional steps to start, such as calling init_process_group.
By utilizing multi-process parallelism, DDP bypasses the GIL limitations. Furthermore, with DDP, the model is broadcasted only once during the construct phase (unlike DP which broadcasts it during each forward operation). There’s no need to broadcast again in subsequent training phases, just for model parameter updates.
Therefore, DDP offers significantly higher performance than DP.
A simple example of running DDP:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()RPC-Based Distributed Training
For scenarios where DDP may not be applicable, such as the Parameter Server Paradigm (divided into worker nodes and parameter server nodes, where worker nodes are responsible for model computation, and parameter server nodes, also known as PS, store the model parameters) and distributed pipeline parallelism (where the model is divided into several stages, placed across multiple nodes, with the completion of one stage’s processing leading to the next), there’s an alternative: RPC
torch.distributed.rpc contains four main pillars:
- rpc: RPC provides the ability to execute functions on a remote worker.
- RRef: Remote REFerence, helps manage the lifecycle of remote objects.
- Distributed_Autograd: Extends the autograd engine for autograd computations across multiple machines.
- Distributed_Optimizer: A distributed optimizer that disseminates gradients computed by the distributed autograd engine to other workers for parameter updates.
A simple example of RPC:
import os
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
def remote_square(x):
print(f"Received {x} from caller. Computing its square...")
return x * x
def worker(rank, world_size):
rpc.init_rpc(
name=f"worker{rank}",
rank=rank,
world_size=world_size
)
rpc.shutdown()
def caller(rank, world_size):
rpc.init_rpc(
name=f"caller{rank}",
rank=rank,
world_size=world_size
)
response = rpc.rpc_sync(to="worker1", func=remote_square, args=(5,))
print(f"Caller received: {response}")
rpc.shutdown()
def main(rank, world_size):
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29502"
if rank == 0:
caller(rank, world_size)
else:
worker(rank, world_size)
if __name__ == "__main__":
world_size = 2
mp.spawn(main, args=(world_size,), nprocs=world_size)Collective Communication (c10d)
Collective Communication serves as the foundation for synchronizing and exchanging data among multiple processes or worker nodes, supporting DDP and RPC.
Basic Operations
- send/isend: Point-to-point data sending.
- broadcast: Data from one node is broadcasted to all other nodes.
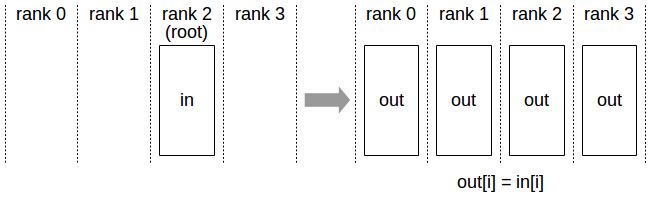
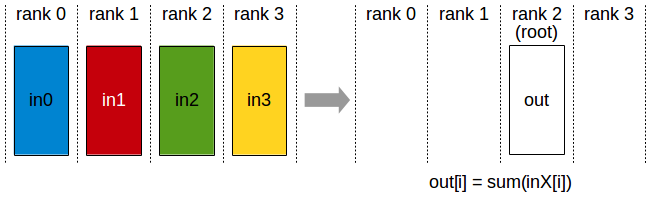
- reduce: Data from all nodes undergoes a specific operation (e.g., summation) and gets reduced to a designated node.
- scatter: Divides data from one node into multiple portions, each sent to different nodes.
- gather: Data from all nodes is collected onto a single node.
- all-gather: Data from all nodes is collected and then distributed to every node.
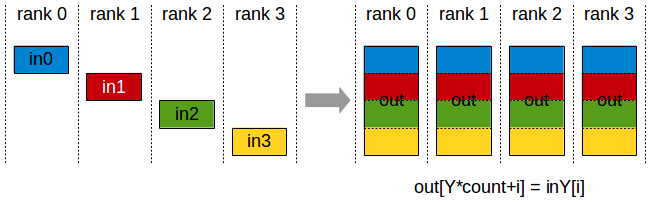
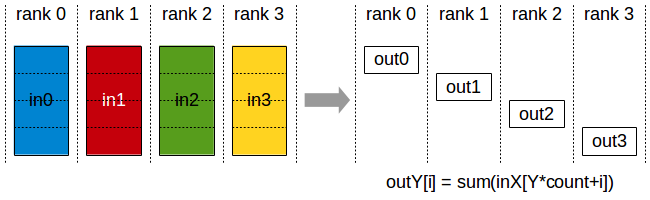
- reduce-scatter:Similar to the reduce operation, but the result is distributed across multiple nodes.
- all-reduce: Data from all nodes undergoes reduction, and the result is distributed to all nodes. (reduce-scatter + all gather in ring algorithm, using 2(n-1) time phrases)
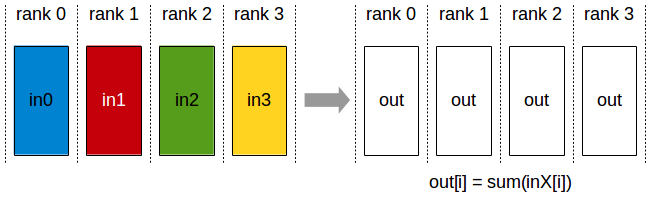
- all-to-all: Each node sends and receives different data according to its own list.
Collective communication APIs such as all-reduce, all_gather etc., are used for DDP training. P2P communication APIs like send, isend etc., are used for RPC training.
Communication Backends
c10d supports several backends, including:
- Gloo: An open-source communication library, the default backend for CPUs, cross-platform with reliable performance, not requiring specific system dependencies.
- NCCL (NVIDIA Collective Communications Library): A communication library for multi-GPU and multi-node, providing optimal performance for NVIDIA GPUs.
- NVLink: High-speed communication within a single node between multiple GPUs
- InfiniBand (IB): High-speed transmission between nodes, part of the RDMA(Remote Direct Memory Access)
- PCIe (Peripheral Component Interconnect Express): Fallback communication mechanism, slower
- First, establish a GPU topology graph, then implement communication using ring (most common), tree, and grid algorithms based on the mentioned three communication mechanisms
- MPI (Message Passing Interface): Used for cross-process message passing across multiple compute nodes. MPI is not the default backend for PyTorch and requires additional installation and adaptation.
Generally, use Gloo for CPUs and NCCL for GPUs. If you’re familiar with and already use MPI communication, then consider installing MPI additionally.
All Reduce Example
Initial State:
| P0 | P1 | P2 |
|---|---|---|
| a0 | b0 | c0 |
| a1 | b1 | c1 |
| a2 | b2 | c2 |
We do reduce scatter first:
After one timestamp:
| P0 | P1 | P2 |
|---|---|---|
| a0 | b0+a0 | c0 |
| a1 | b1 | c1+b1 |
| a2+c2 | b2 | c2 |
After one timestamp:
| P0 | P1 | P2 |
|---|---|---|
| a0 | b0+a0 | c0+b0+a0 |
| a1+b1+c1 | b1 | c1+b1 |
| a2+c2 | b2+a2+c2 | c2 |
Then we do all gather, after one timestamp:
| P0 | P1 | P2 |
|---|---|---|
| c0+b0+a0 | b0+a0 | c0+b0+a0 |
| a1+b1+c1 | a1+b1+c1 | c1+b1 |
| a2+c2 | b2+a2+c2 | b2+a2+c2 |
After one timestamp:
| P0 | P1 | P2 |
|---|---|---|
| c0+b0+a0 | c0+b0+a0 | c0+b0+a0 |
| a1+b1+c1 | a1+b1+c1 | a1+b1+c1 |
| b2+a2+c2 | b2+a2+c2 | b2+a2+c2 |
Communication done.
Assuming we have N nodes and the total gradient to be communicated for each node is K, the total communication volume of whole All Reduce is: 2 * K/N * (N-1)
Further Reading - Pytorch Distributed Architecture
C10D and DistributedDataParallel
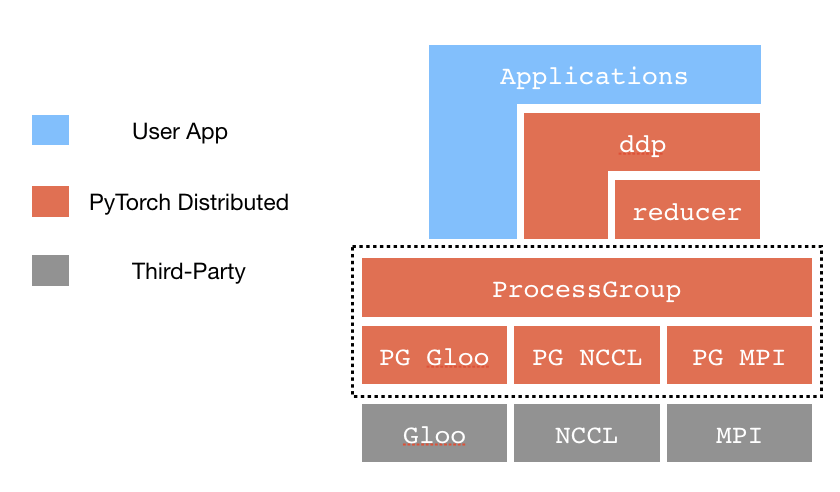
Process Groups (PG): Manages cross-process communication, exposing a series of communication APIs like
broadcast,send,all-reduce, etc.Store: A key-value storage system used for sharing information between processes. It includes
FileStore(a shared file for storing key-value pairs),TCPStore(using a TCP server for storage),HashStore(stored in memory, used for single-process modes or testing), as well as third-party stores likeetcd,Redis.Reducer: Responsible for gathering model gradients from different devices, performing reduction operations (like averaging), and then broadcasting the gradients back to all nodes to ensure consistent model parameter updates. Reducer employs a Bucketing strategy, combining multiple parameter gradients and then broadcasting them all at once to maximize bandwidth utilization.
RPC Framework
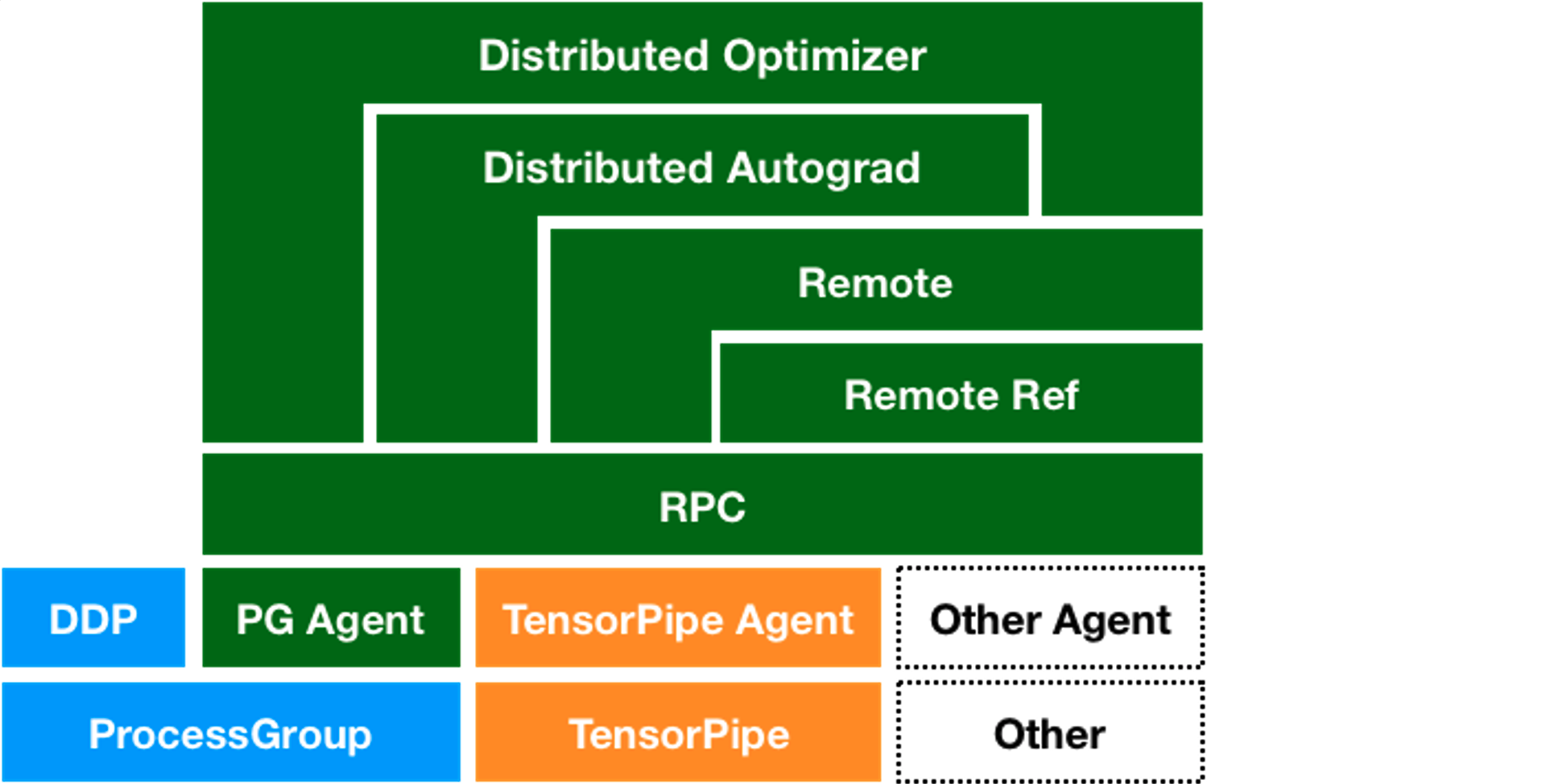
RPC Agents: To support various communication protocols and backends, PyTorch offers the Agent abstraction responsible for cross-process message passing. This includes ProcessGroupAgent (based on c10d::ProcessGroup implementation) and TensorPipeAgent (optimized specifically for tensor communication).