Summary: Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
0. Materials
[Paper]https://arxiv.org/pdf/2502.12962
[Github]https://github.com/CapitalCode2020/InfiniRetri2
1. What is the paper about?
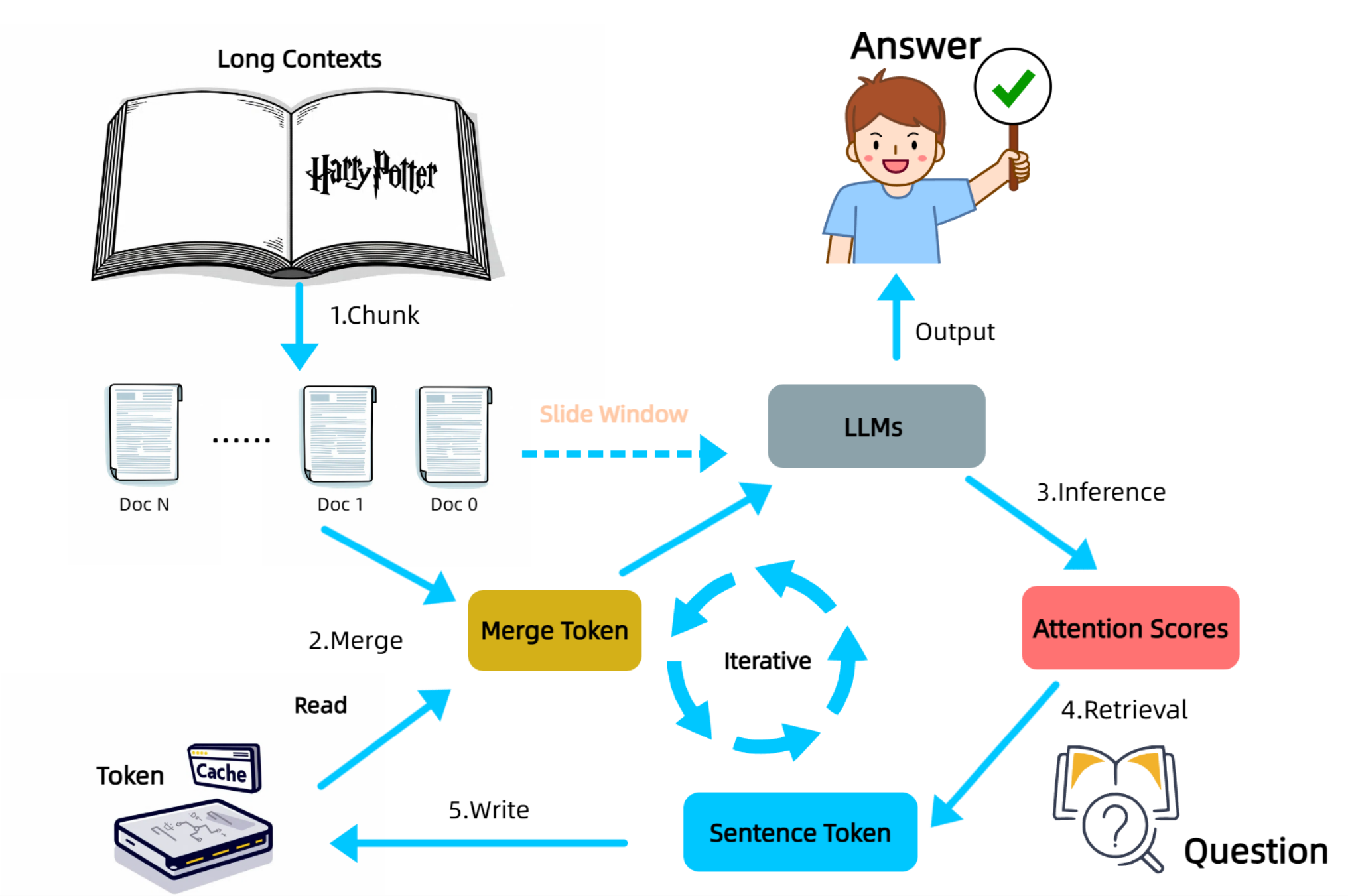
Proposes InfiniRetri, a training-free framework that equips any Transformer LLM with “infinite” context length by treating the model’s own attention scores as a retrieval signal.
Workflow: split long text into chunks → input: chunk + previous cached sentences → read final-layer attention → 1-D convolve to score short phrases (rather than scoring single token) → cache the sentences containing the Top-K tokens → slide to next chunk.
Achieves 100 % accuracy on NIH with 1 M-token inputs using a 0.5 B LLM, and large gains on LongBench QA tasks, while reducing inference tokens by ~90 – 95 %.
2. What is new compared to prior work?
Earlier KV-compression work (SnapKV, H₂O, PyramidKV, DynamicKV, CAKE, etc.) observes attention patterns but still stores KV vectors; InfiniRetri replaces KV storage with sentence-level token IDs selected purely by attention scores.
It keeps whole sentences (semantic units) instead of individual tokens or vectors, preserving context while remaining lightweight.
Unlike RAG (needs a separate embedding model) or StreamingLLM (keeps “attention sinks” KV), it requires no additional modules and discards all KV tensors.
First method that outperforms Full-KV accuracy and uses less memory on standard long-context benchmarks.
3. What experiments were run to support the arguments in this paper?
NIH: It extends accurate retrieval from 32 K → 1 M tokens and beats StreamingLLM, SnapKV, PyramidKV, etc.
LongBench V1 (9 tasks): compared against Full-KV, StreamingLLM, H₂O, SnapKV, PyramidKV, DynamicKV, CAKE; It is the only method that surpasses Full-KV on all three open-source models, with up to +288 % on HotpotQA.
LongBench V2 – Qwen 2.5-7B + InfiniRetri matches the 72 B model on overall score, especially strong on Long samples.
It shows average retained tokens drop to ~4.5 % (e.g., 18 k → 834 on NrtvQA) while accuracy rises.
Ablation: swapping sentence-ID cache for past-KV cache drops QA F1 by 10–15 pts, proving token-ID cache is key.
4. What are the shortcomings/limitations of this paper?
Gains on LongBench summarization sets (GovReport, MultiNews) are small because summarization needs holistic context, not sparse cues.
Performance hinges on hyper-parameters (chunk size, phrase width k, Top-K); sub-optimal values hurt recall.
Relies on sentence boundaries; noisy or code-like text may break the assumption of “sentence = minimal semantic unit”.
Approach is text-only; multimodal long-context tasks (images, video) remain unexplored.
Empirical success, but lacks formal guarantees on recall vs. chunk hyper-parameters.
5. What is a reasonable next step to build upon this paper?
Integrate a lightweight on-the-fly abstractive summarizer to condense non-selected chunks, helping tasks that need global coverage.
Automatically tune chunk size and Top-K per task or per input distribution to balance recall and latency.
Apply the attention-retrieval + sentence caching concept to vision-language models (e.g., VideoStreaming) for long videos or PDFs.
Appendix
StreamingLLM: A training-free “sliding-window” decoder that keeps only the first & last KV tokens (“attention sinks”) so the model can produce arbitrarily long outputs.
SnapKV: Drops low-score KV pairs selected by attention to shrink GPU memory during decoding.
H2O (Heavy-Hitter Oracle): Keeps the most-attended (“heavy-hitter”) tokens plus a small recency buffer in every layer’s KV cache.
PyramidKV: Allocates larger KV budgets to lower layers and smaller ones to higher layers in a pyramidal schedule.
DynamicKV / ZigZagKV: Adjusts KV retention on-the-fly based on per-layer uncertainty or task need.
CAKE (
Computation and NetworkAwareKV CachEloader): A “load-or-recompute” scheduler that parallelizes KV generation to mask GPU/CPU I/O latency.InfiniPot: Two-stage KV eviction + top-k sparse attention to fit infinite context in fixed memory.
DuoAttention: Splits heads into “retrieval” (full KV) and “streaming” (windowed) subsets to halve memory.
SelfExtend: Inserts grouped & neighbor-attention blocks at inference time to extrapolate context without fine-tuning.
TransformerFAM: Builds a feedback loop so hidden states become a long-term working memory.
LongLoRA: Applies parameter-efficient LoRA finetuning to extend context length economically.
Needle-in-a-Haystack (NIH): Stress-test that hides one “needle” sentence in a huge document and asks the model to retrieve it exactly.
LongBench V1 / V2: A bilingual multi-task benchmark (QA, summarization, etc.) whose inputs range from 1 K to 30 K+ tokens.
HotpotQA – 113 K multi-hop Wikipedia questions that require combining two evidence paragraphs.
YaRN: A recipe for scaling RoPE’s base frequency during continued pre-training to reach 128 K–1 M context.
Mistral-7B: High-efficiency 7 B-parameter model with grouped-query attention, 32 K window.