Summary: FLASHINFER: EFFICIENT AND CUSTOMIZABLE ATTENTION ENGINE FOR LLM INFERENCE SERVING
0. Materials
1. What is the paper about?
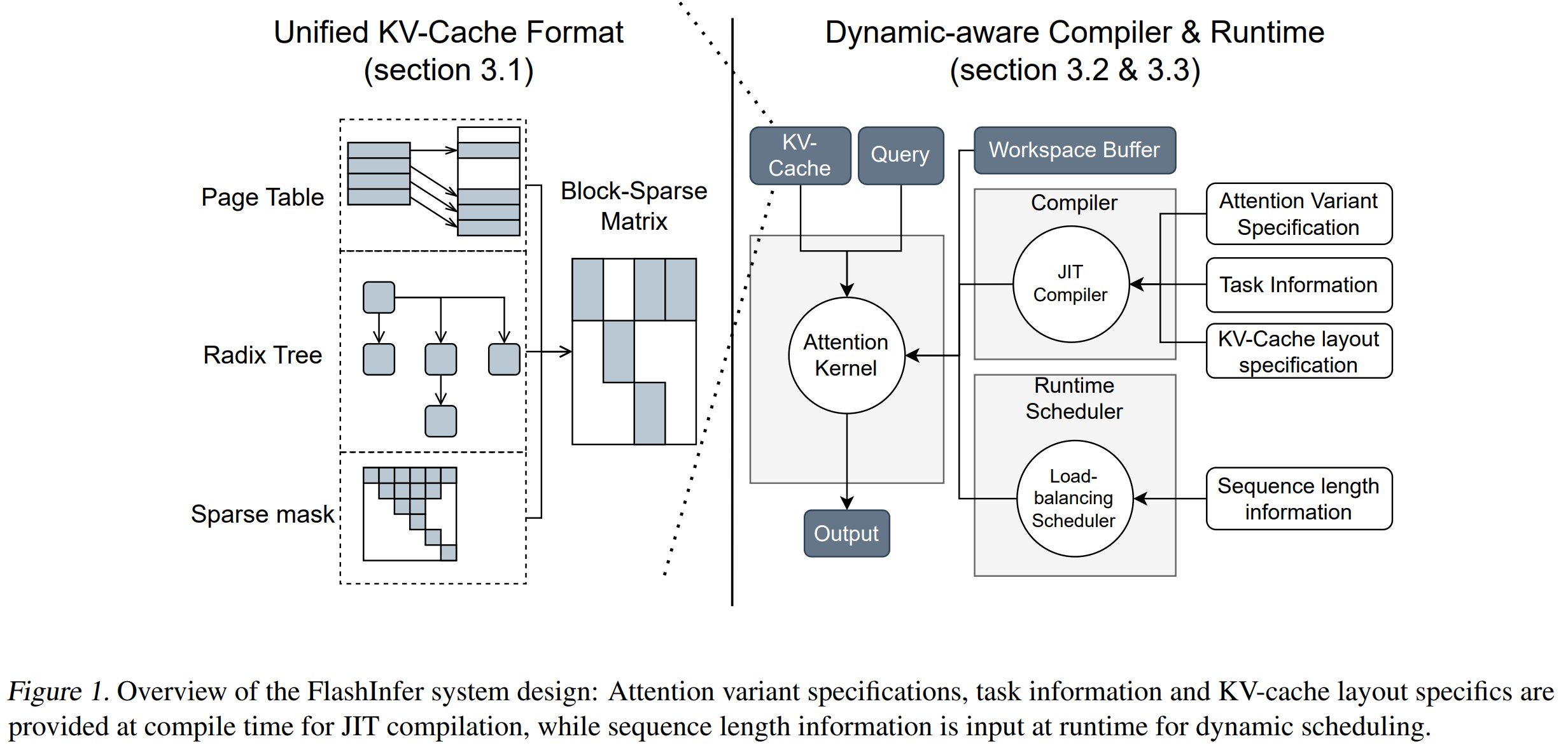
Introduces FlashInfer, a GPU kernel library and JIT compiler that accelerates attention in LLM inference.
Represent every KV-cache layout (paged, radix-tree, tree-mask, etc.) as a block-sparse row (BSR) matrix, allowing one unified kernel family to serve diverse workloads.
Seamless drop-in for vLLM, SGLang, MLC-Engine and other serving stacks, cutting online latency and boosting throughput.
2. What is new compared to prior work?
Unified BSR abstraction generalises Page-, Radix- and Tree-Attention into one data format.
Extends FlashAttention 2/3 to arbitrary column widths (even 1 × 16) via gather→shared-mem→tensor-core; prior Blocksparse or FlexAttention required 16 × 16 blocks.
Users inject functors (Query/Key/Logits Transform, Mask, etc.) and obtain a fused kernel in minutes—Plug-and-play JIT template. Faster than Triton-based FlexAttention and without its performance gap on Hopper GPUs.
3. What experiments were run to support the arguments in this paper?
Integrated into SGLang and compared with Triton backend on Llama-3 8 B (1×H100) & 70 B (4×H100); median ITL dropped 29-69 % and TTFT up to 21 %.
Measured bandwidth & FLOP utilisation on A100-40 GB and H100-80 GB across constant / uniform / Zipf length distributions; FlashInfer reached 70-83 % bandwidth in skewed batches vs ≈45 % for FlashAttention.
Generated a RoPE-fused kernel via JIT (≈20 LoC); achieved 28-30 % lower latency and 1.6-3.7× higher bandwidth than unfused FlashAttention.
4. What are the shortcomings/limitations of this paper?
Generates native CUDA/CUTLASS, limiting adoption on non-NVIDIA hardware.
Although amortised over layers, planning still happens on CPU each generation step; extremely high QPS setups might hit a CPU bottleneck.
Benchmarks centre on Llama-family and two GPU SKUs (A100/H100); results on consumer GPUs, Intel/AMD cards, or >4-GPU clusters remain unreported.
Focuses on KV sparsity; other operator classes (FFN, MoE) still rely on external optimizations.
5. What is a reasonable next step to build upon this paper?
Emit Triton-IR, HIP or SYCL to cover AMD/Intel GPUs and integrate with compiler stacks like OpenAI Triton 3 or Mojo.
Generalise the block-sparse abstraction to FFN GEMMs and MoE routing, enabling E2E sparse execution under one runtime.
Extend the deterministic load-balancer across multiple nodes, co-optimising network traffic with NVLink/InfiniBand topology.
Appendix
Online-Softmax – technique that incrementally maintains running max and sum to compute softmax in constant memory instead of materialising the full attention matrix
Sigmoid-Attention / FlashSigmoid – attention variant that replaces softmax with an element-wise sigmoid to clip logits.
RadixAttention – SGLang’s variant that indexes KV blocks with a radix tree, enabling efficient prefix reuse
Prefix-Caching – storing a shared prompt once so that multiple parallel continuations can reuse the same KV prefix
Ragged Tensor – tensor whose rows may have different lengths, implemented via an index pointer array instead of padding
Block-Sparse Row (BSR) – sparse-matrix format that groups non-zeroes into fixed-sized blocks (br × bc) to improve register reuse and tensor-core compatibility
Vector-Sparsity – extreme case of BSR where one dimension of the block is 1 (e.g., 16×1), letting the kernel skip individual vectors while still using tensor cores.
Gather -→ Shared-Mem -→ MMA – strategy of first fetching sparse columns into shared memory, then issuing dense tensor-core instructions (MMA) on the packed data.
Tensor Memory Accelerator (TMA) – Hopper hardware engine that asynchronously copies tiles between global and shared memory without blocking the warp
WGMMA (WarpGroup Matrix-Multiply-Accumulate) – Hopper PTX instruction that performs Warp-Grouped Matrix Multiply-Accumulate on 64-row tiles, enabling larger persistent kernels
CTA (Cooperative Thread Array): same as a block in CUDA.
Stream-K – GPU load-balancing scheme that partitions inner-loop iterations evenly across CTAs to avoid tile quantisation artefacts. (Eg: 100 tiles, 32 blocks, 4 tiles remaining for the fourth round.)
Deterministic Load-Balanced Scheduler (FlashInfer) – modified Stream-K algorithm that assigns work tiles to CTAs without atomics, guaranteeing repeatable outputs.
Persistent Kernel – kernel that loops internally over tiles instead of being relaunched, keeping registers and shared memory hot.
FlexAttention – Triton-based framework that lets users express attention variants through functors
MLC-Engine – TVM-based cross-device serving stack.
Inter-Token Latency (ITL) – average time between two consecutive generated tokens during streaming inference.