Distributed Training Strategy Introduction
Summary
This blog post explores advanced parallelism techniques in deep learning to optimize computational efficiency and memory usage across GPUs. It covers Data Parallelism (DP), Zero Redundancy Optimizer (Zero), Pipeline Parallelism (PP) and Tensor Parallelism (TP).
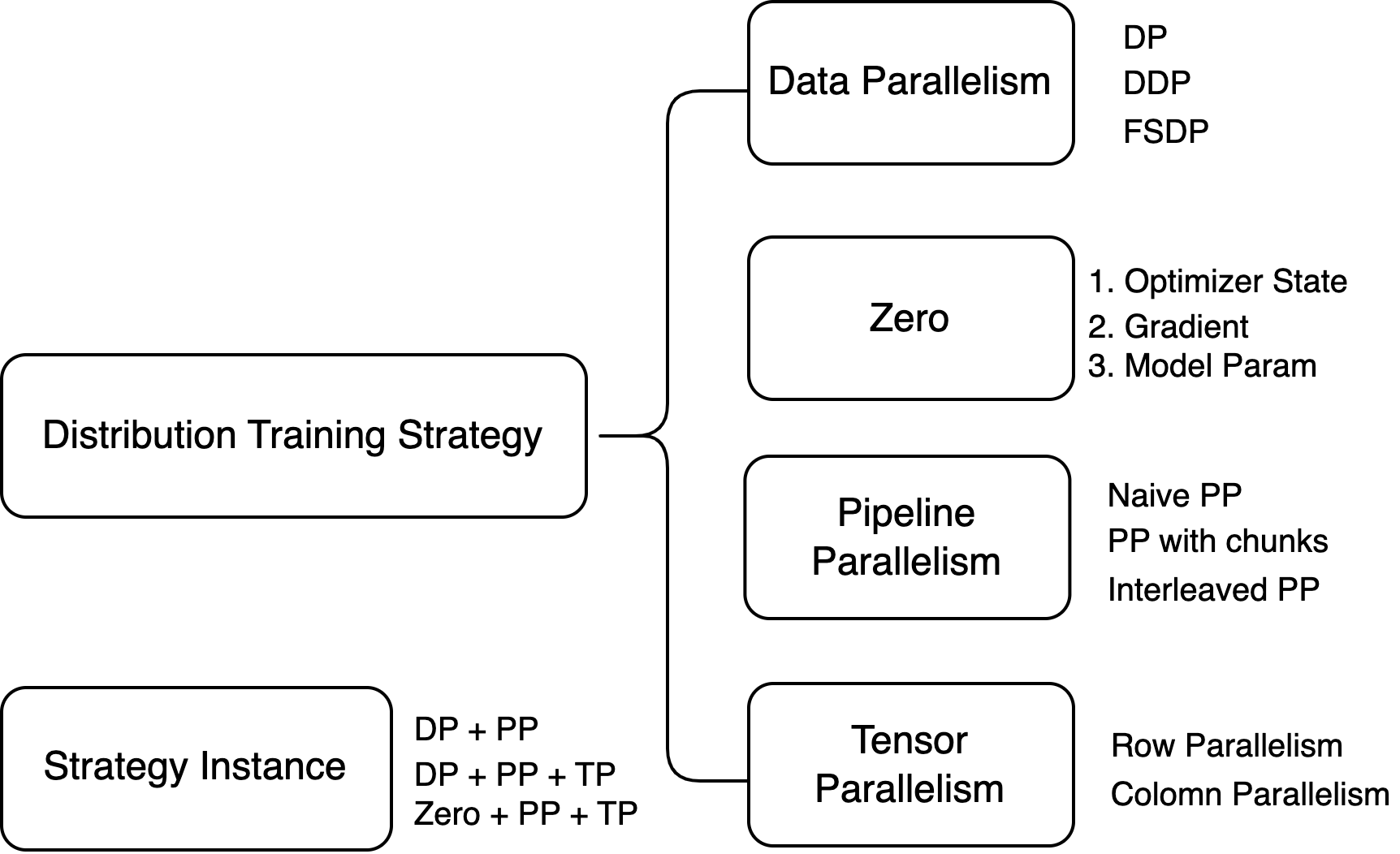
Data Parallelism
Data parallelism is the simplest strategy for parallel processing. In this setup, each GPU holds a complete copy of the model and processes different training data inputs in parallel. During forward computation, each GPU independently executes its assigned data, calculates the loss, and performs backward propagation to compute gradients. The gradients are then reduced (averaged) through communication, broadcasted to all GPUs, and used to update the model weights with the average gradient.
However, because each GPU retains the entire model parameters and optimizer state, data parallelism is not particularly memory-efficient.
Moreover, data parallelism involves a communication step to aggregate gradients after each GPU has completed forward and backward computations.
Pytorch natively supports this functionality through DataParallel (DP) or DistributedDataParallel (DDP). We strongly recommend using DDP over DP for the following reasons:
Pytorch DDP:
- Upon initialization, each GPU holds a complete copy of the model.
- The data is divided into multiple micro batches, and each GPU performs forward computation on its segment of data to compute loss and then gradients through backward propagation.
- All GPUs communicate using all-reduce to obtain an averaged gradient across all units.
- Each GPU updates its model using the averaged gradients.
Pytorch DP:
- GPU0 loads a batch of data into memory, then partitions and distributes it to other GPUs.
- GPU0 copies and transmits the entire model to the other GPUs, a process that needs to be repeated for each batch.
- The other GPUs perform forward computations and send the results back to GPU0 to compute the loss.
- Once the loss is computed, GPU0 broadcasts it to the other GPUs for backward propagation.
- The other GPUs send their computed gradients back to GPU0 to average and sum.
- GPU0 updates its model and repeats the process for the next batch.
From this, it is clear:
- In a single batch, Pytorch DDP only requires one all-reduce communication for gradient exchange, whereas DP requires five data exchanges (data distribution, model replication, forwarding results, loss broadcasting, and gradient aggregation).
- DP introduces a master node, creating a bottleneck that impedes overall utilization.
- DP employs
threadsfor communication (subject to GIL constraints), whereas DDP utilizestorch.distributed.
Additionally, Pytorch has developed the Fully Sharded Data Parallel (FSDP), which builds on DDP by sharding model parameters. However, due to its higher complexity, the industry currently favors Zero, as discussed later.
Zero Redundancy Optimizer:Zero
The Zero Redundancy Optimizer, commonly referred to as Zero, distributes the model states (parameters, gradients, and optimizer states) across various data parallel processes. This approach eliminates significant memory redundancy and employs a dynamic communication mechanism to share necessary states among devices.
Note: If you are interested in Zero, you can also read zero_paper_summary
Three Stage of Zero
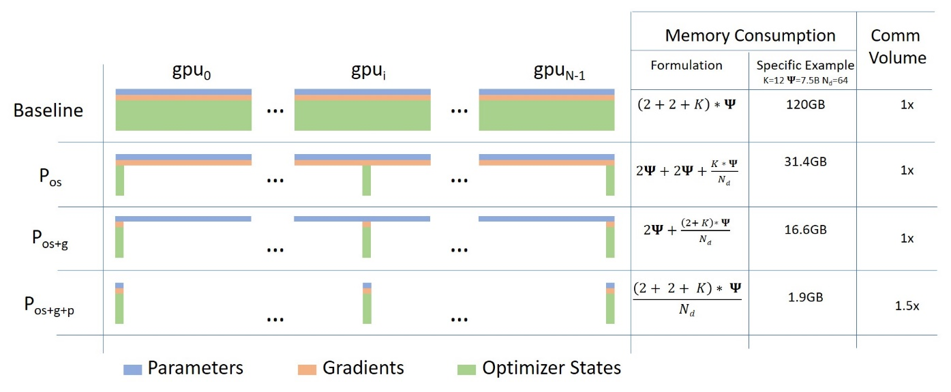
In the diagram, Ψ represents the number of model parameters, K denotes constants specific to the optimizer, and Nd indicates the number of GPUs. The optimization is segmented into three distinct stages.
Stage 1: This stage involves the partitioning of optimizer states, resulting in a fourfold reduction in memory usage as the diagram shows, with communication overhead equivalent to that of traditional DDP (One all-reduce). What are the optimizer states? e.g., for Adam optimizer, 32-bit weights, and the first, and second moment estimates
Stage 2:This stage introduces gradient partitioning (FP 16 running gradients), which further reduces memory usage by eight times as the diagram shows, still maintaining the same level of communication as DDP (However, due to the complexity, the actual communication overhead will be higher).
Stage 3:This final stage includes partitioning of the model parameters (Runtime FP16). Memory usage decreases linearly with the addition of GPUs. For instance, 64 GPUs would result in a 64-fold reduction. However, this stage increases the communication overhead by approximately 50%.
Training Process Example
Let’s consider a training scenario utilizing Zero’s three stages with four GPUs (encompassing one forward and one backward passes and parameter updates):
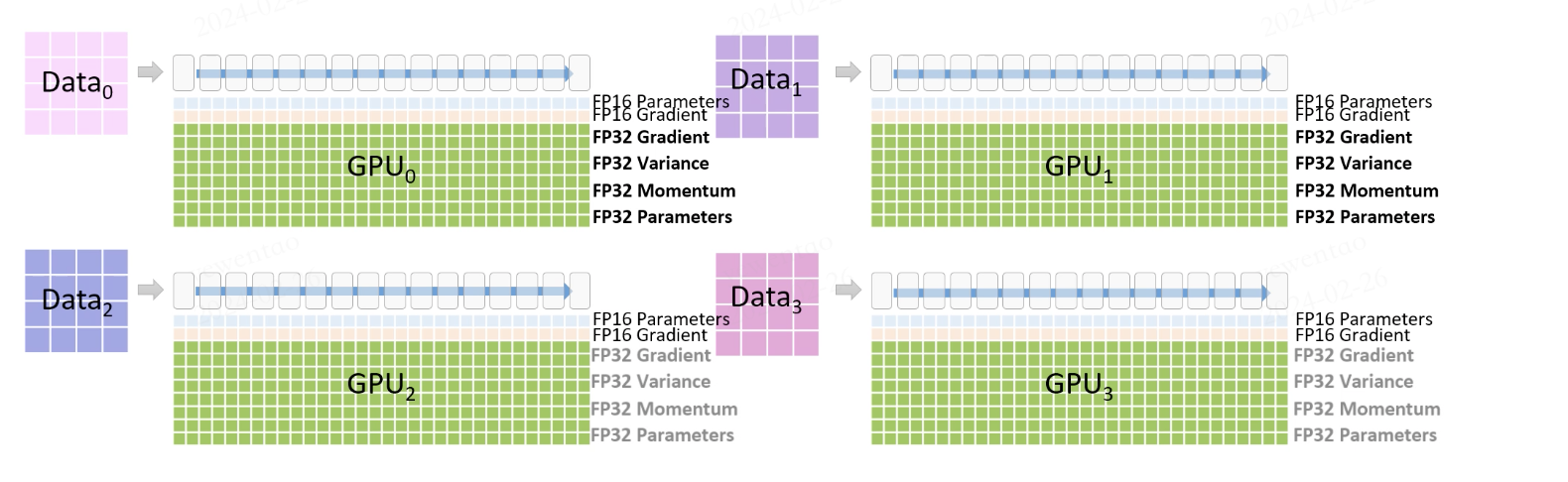
Initially, the data is divided into four parts, each fed into a GPU. Each GPU stores FP16 parameters and gradients for actual computations, alongside stored FP32 optimizer states, which are utilized after the FP16 gradient computations.
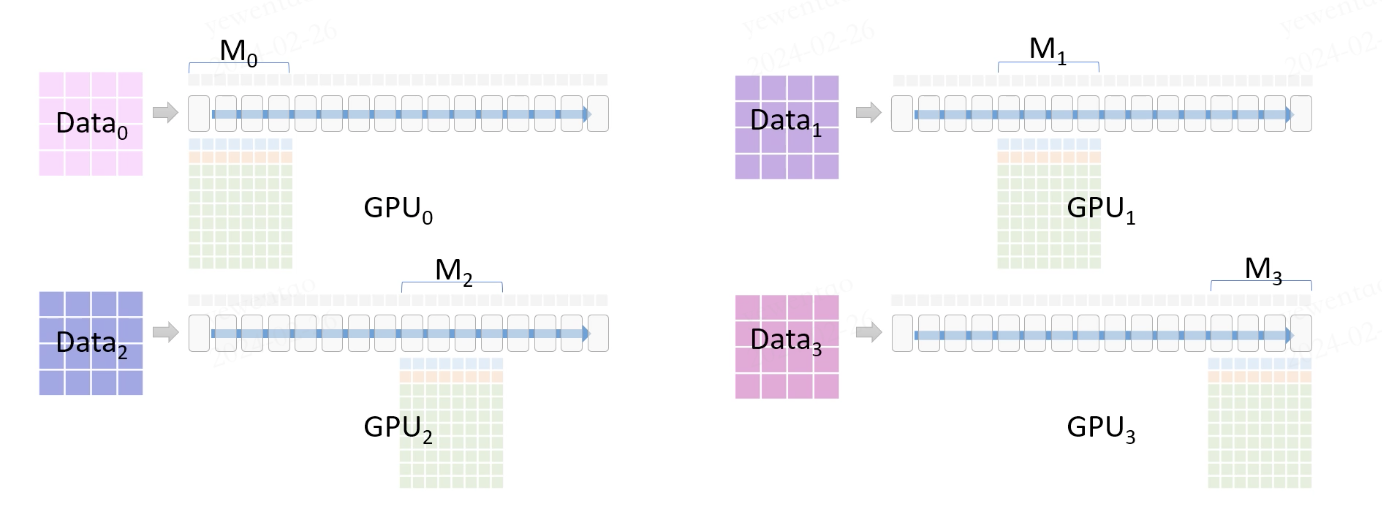
During the forward pass, each GPU holds a portion of the model parameters. For parameters not present on a GPU, communication is required.
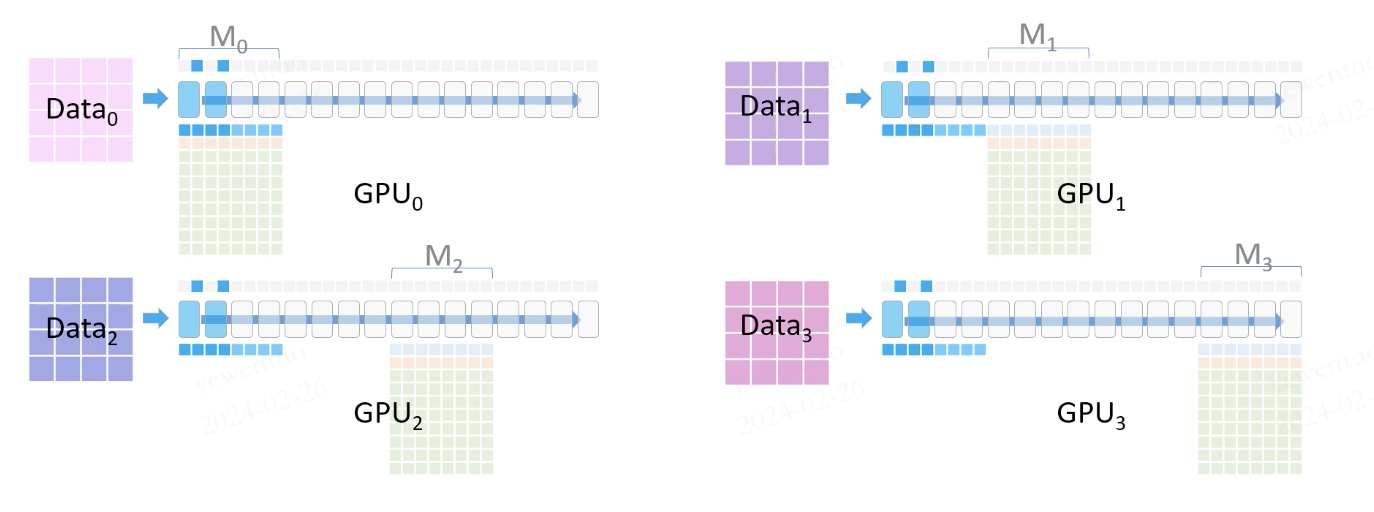
For example, GPU0 broadcasts its forward pass parameters (M0, fp16) to the other GPUs. Each GPU then performs forward computations with its portion of the data. Once the forward computations are completed, the shared parameters on other GPUs are deleted.
It is important to note that only a subset of activation values from the forward pass is retained to minimize memory usage. The discarded activation values are recomputed during the backward pass through a technique known as “checkpointing”.
Following this, GPU1 broadcasts its parameters (M1), and the process continues similarly until the entire forward pass is completed, calculating the loss for each GPU based on its dataset.
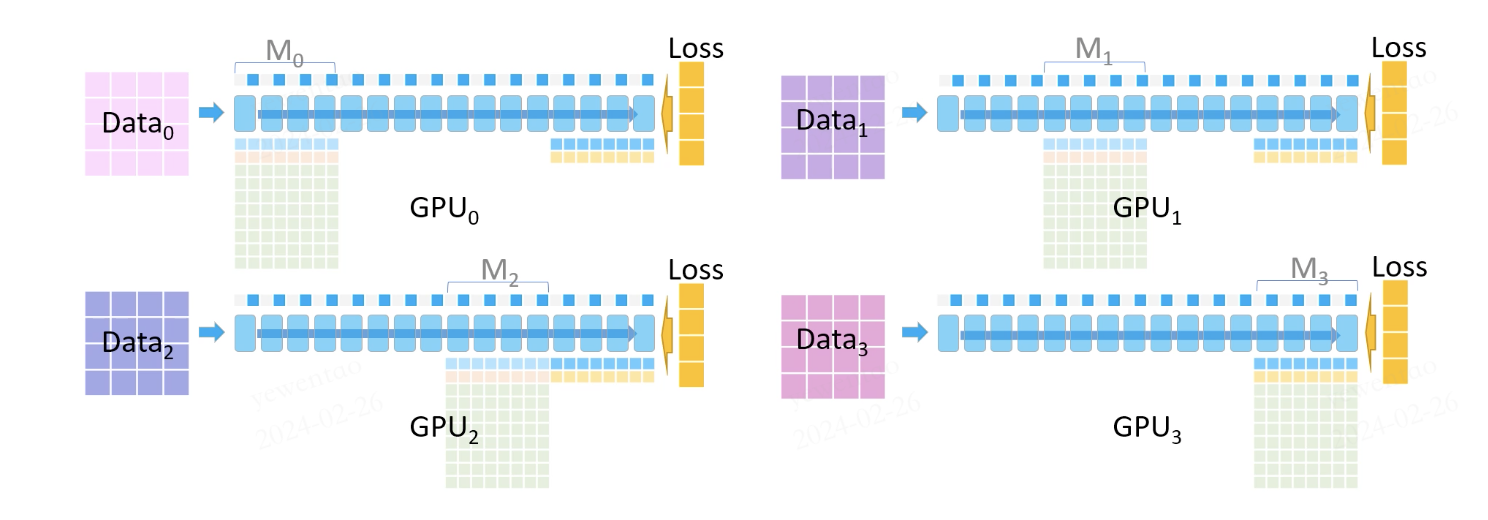
The backward pass then commences:
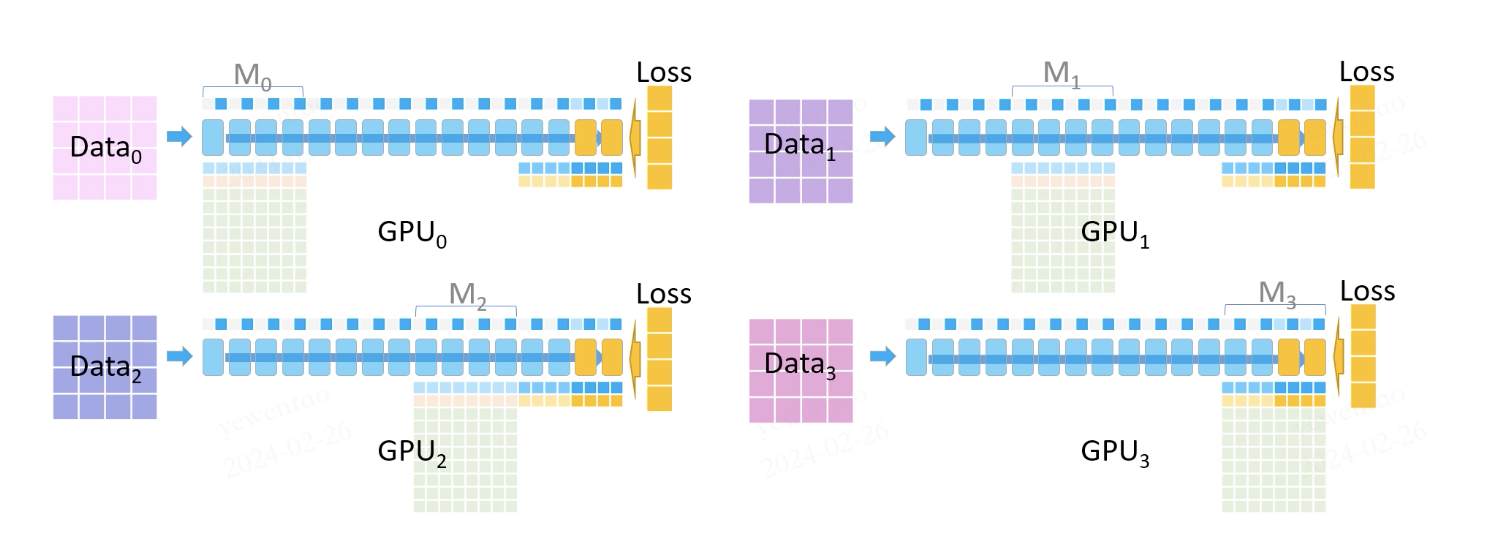
During this phase, all model parameters from M3 are still present, and missing activation values are recomputed using the previously retained activations (for instance, if the model has ten layers, and activations from layers 0, 2, 4, 6, and 8 were saved, these are used to compute the outputs for layers 1, 3, 5, 7, and 9).
Each GPU computes its own gradients based on the loss, activation values and model params. These gradients are then communicated to GPU3, which accumulates them to form the complete gradient.
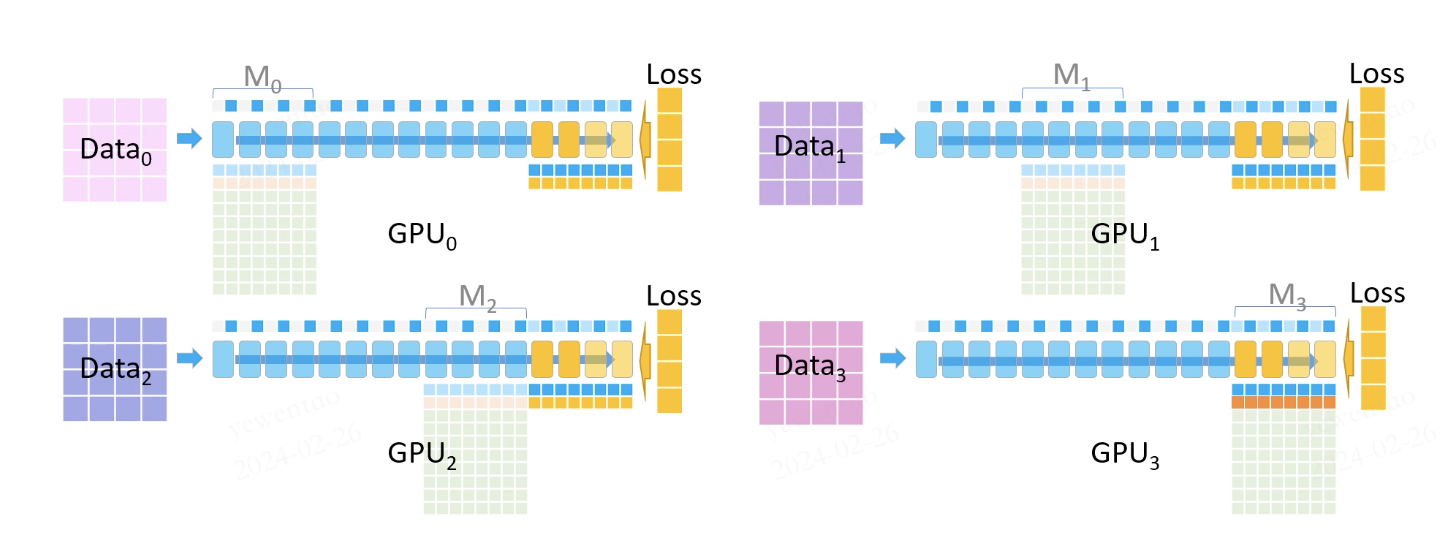
Once the gradient accumulation is complete, the other GPUs delete the parameters and gradients of M3 to further conserve memory, and all GPUs delete all stored forward activations. The backward pass continues:
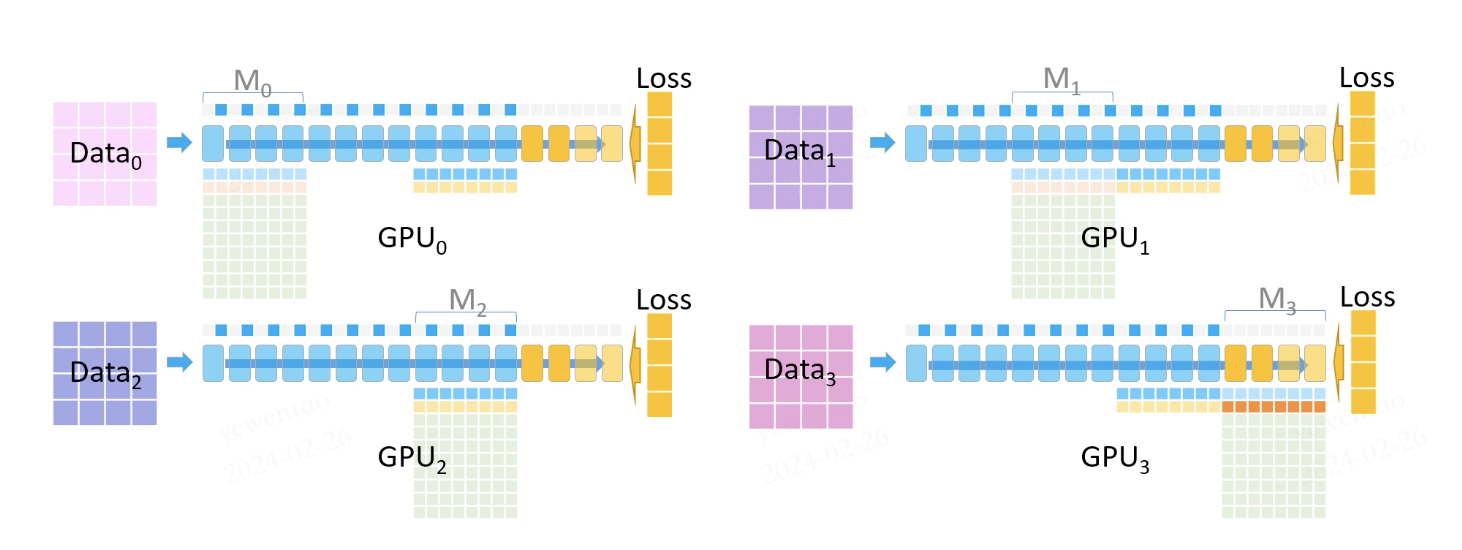
Now, we need to compute the gradients for M2. GPU2 broadcasts its parameters to the other GPUs, and the gradients are computed using the parameters, loss and the saved partial activations.
This process repeats until all gradients have been computed.
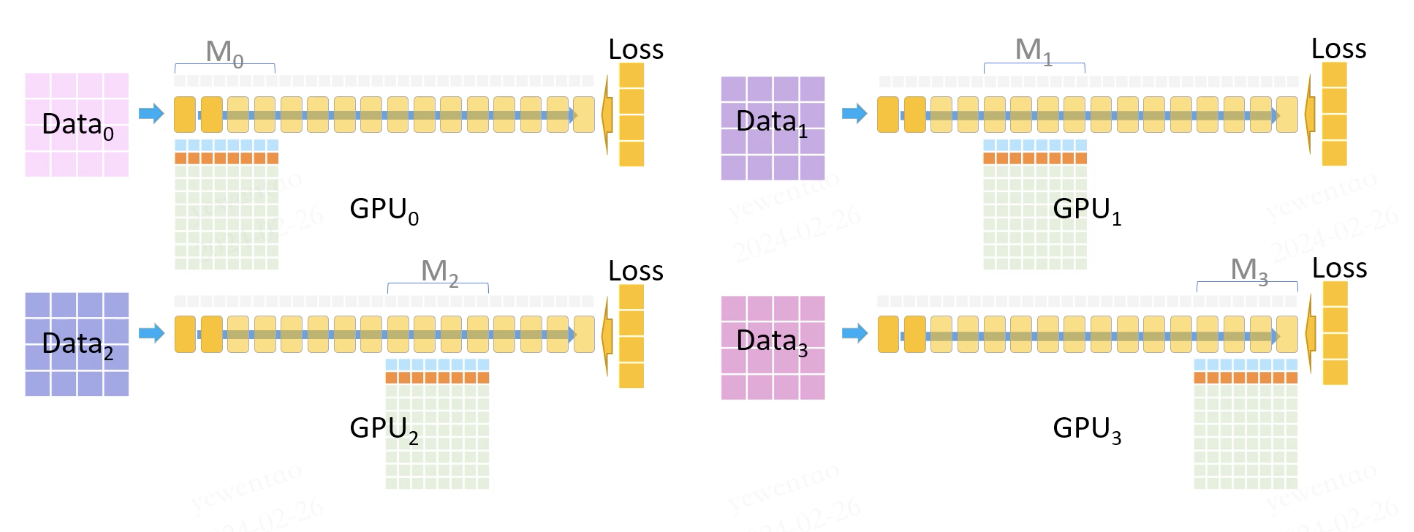
At this point, each GPU has its gradients (accumulated from all datasets).
The optimizer then uses these gradients (FP16) to update its model parameters (FP32). (Computation based on FP32 gradients + FP32 momentum/variance + FP32 params)
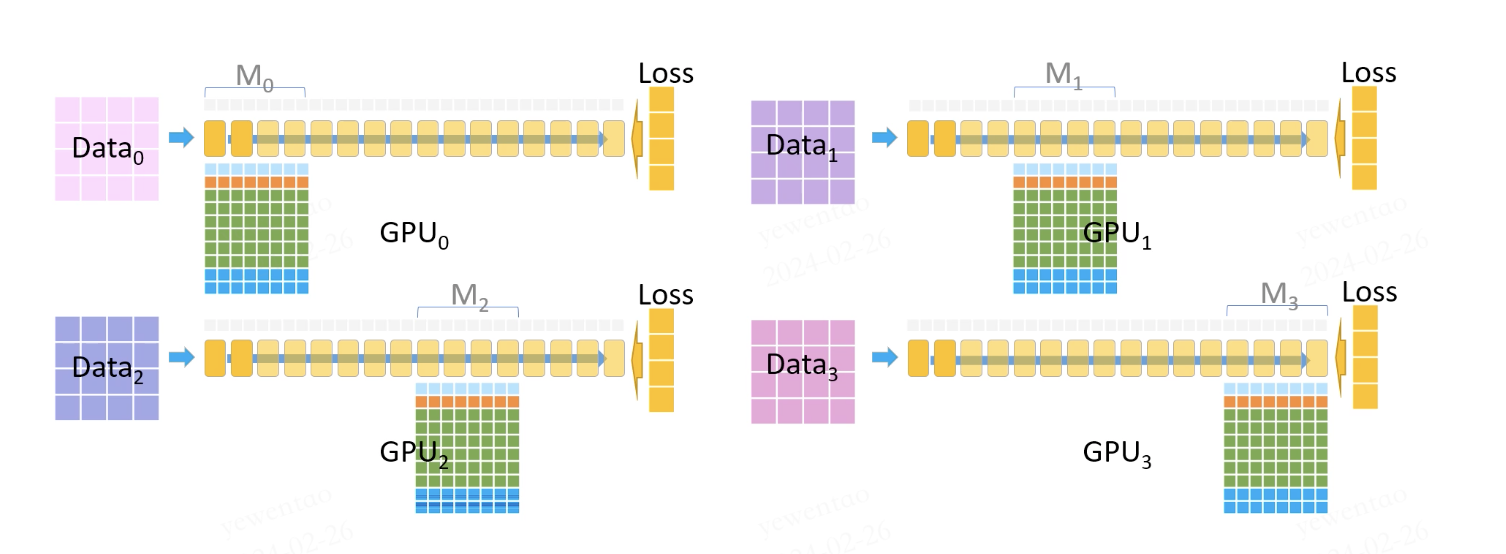
Finally, these FP32 model parameters are cast to FP16, ready for the next iteration of model training (mixed precision training).
An example for using DeepSpeed:
model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,
model=model,
model_parameters=params)
# Behind the scenes, torch.distributed.init_process_group(...) is replaced by deepspeed.init_distributed()DeepSpeed defaults to the NCCL backend and allows you to write training loops as usual:
for step, batch in enumerate(data_loader):
loss = model_engine(batch)
model_engine.backward(loss)
model_engine.step()When scaling to multiple nodes, DeepSpeed typically leverages Open MPI for high-performance message passing.
ZeRO-DP: Communication Analysis
In standard DP, each iteration requires a gradient all-reduce. This typically involves a communication volume of . That’s because reduce-scatter costs , and then all-gather also costs .
Stage 1:
- At Stage 1, only the optimizer states (e.g., Adam’s momentum, variance) are partitioned across GPUs. Gradients and parameters remain fully replicated on each GPU.
- Consequently, the communication volume remains at for gradient all-reduce.
- We do not transmit the fp32 optimizer states themselves because they’re partitioned and only exist locally where needed.
- However, the communication method has changed: first, we fully compute the gradients for our portion of the data. Then, we perform a reduce scatter operation to distribute the gradient shards across all devices. Each device uses its own shard of the gradients and optimizer state to update the portion of the parameters it is responsible for. After that, an all gather operation is performed to synchronize the updated parameters across all devices.
Stage 2:
- Each GPU holds only the subset of gradients needed for its parameter partition.
- Implementation-wise, we no longer perform an all-reduce on the entire gradient. Instead, each GPU’s portion of the gradients is reduced to whichever GPU is responsible for that partition. Each such reduce operation handles data, and there are such operations (one per GPU).
- Crucially, each GPU only needs its local gradients for backward computation, so it does not depend on receiving the reduced/accumulated gradients from other GPUs. Therefore, these reductions can be overlapped with local computations, making this stage highly efficient in practice.
- From a global perspective, this is effectively a reduce-scatter of size .
- After each GPU has updated its local parameters, we need to gather these updated parameters so that all GPUs end up with the latest model parameters. This all-gather also costs .
- Thus, the total is still overall (the same as standard DP).
Stage 3:
Now each GPU stores only its own partition of the model parameters (fp16). As a result, we need to communicate these parameters at run time:
- Forward Pass: For each layer’s partition, the responsible GPU broadcasts that chunk of parameters (i.e., ) to the others so they can compute that layer’s forward pass. Doing this times gives a total of in communication. (This is similar as scheduling an all-gather in a global view.)
- Backward Pass: Similarly, we need of parameter communication to reconstruct each partition of parameters in reverse order for backprop.
- Gradient Reduce: Each GPU calculates the gradients for its slice of data, then reduces them back (via N times ), effectively a global reduce-scatter to sum up those gradients. This sums to another .
Adding these up: , which is 1.5x compared to the in standard DP.
Note that, unlike Stage 2, we don’t need an all-gather to unify parameters at the end because each GPU permanently maintains only its own partition of the parameters.
ZeRO-R: Further Optimizations for Residual Memory
Beyond ZeRO-DP, ZeRO-R addresses residual memory consumption, namely activations, temporary buffers, and memory fragmentation. It encompasses the following:
Partitioned Activation Checkpointing
- Instead of replicating activations for every GPU, ZeRO-R partitions them. The activation chunk is gathered only on-demand when computing a layer’s backward pass.
- If GPU memory remains tight, ZeRO-offload can move these partitioned activations to CPU memory. For highly compute-intensive models (e.g., GPT-2), offloading doesn’t significantly slow down training because computation can overlap with communication.
CB: Constant-Size Buffers
- Large language models (LLMs) typically fuse parameters and gradients into a single massive buffer to improve all-reduce efficiency. However, as model size grows, this buffer can become huge.
- ZeRO-R uses a fixed-size buffer strategy, splitting the work into chunks if necessary, preventing the fused buffer from monopolizing GPU memory.
MD: Memory Defragmentation
- In training, long-lived tensors (activations, gradients) interleave with short-lived ones (temporary activations, operator workspaces), causing fragmentation.
- ZeRO-R allocates contiguous memory regions in advance for major tensors, which reduces fragmentation and speeds up allocation/deallocation operations.
The paper shows partitioned activations add only about 10% extra communication compared to tensor (model) parallelism, yet it can significantly increase batch size. Larger batch sizes speed up training and reduce the overall number of iterations, thereby lessening DP’s total gradient communication. Hence, ZeRO-R provides substantial benefits both in memory savings and training performance.
Pipeline Parallel
The core idea of Pipeline Parallelism (PP) is to distribute different layers of a model across multiple GPUs, with each GPU responsible for a specific segment of the model.
For instance, consider a model with six layers divided across two GPUs (naive pipeline parallelism):
============= =============
| 0 | 1 | 2 | 3 | 4 | 5
============= =============
gpu0 gpu1When a batch of data is inputted, it first processes through layers 0 to 2 on gpu0, and then moves via the .to() to gpu1 for processing through layers 3 to 5.
Typically, labels are sent to the GPU where the last layer of the model resides to compute the loss directly, followed by backward propagation and parameter updates.
However, this design poses a problem: when gpu1 is processing a batch, gpu0 remains idle. To minimize GPU idle time, we introduce pipeline parallelism.
One implementation approach is GPipe:
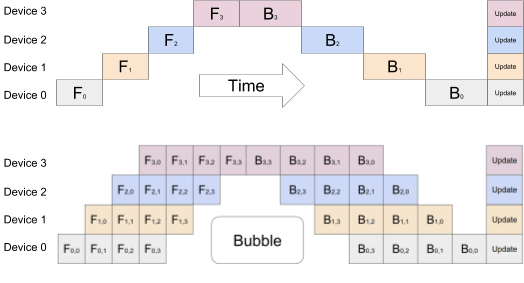
The principle of GPipe is to divide the input data into several micro-batches, allowing GPUs to process different micro-batches in parallel to maximize utilization and minimize idle time (often referred to as bubbles). In the diagram, four GPUs train with chunk=4 (meaning each pipeline stage simultaneously processes four batches of data). For example, GPU0 would perform four forward computations from F0 to F3 before handing off to the next GPU, and then perform four backward computations from B3 to B0.
When training simultaneously utilizes Data Parallelism (DP) and PP, we have global_batch_size = micro_batch_size * dp_size * chunk. For instance, if global_batch_size=512, DP=4, and chunk=4, then each micro_batch_size=32, meaning each micro-batch contains 32 data points.
Another PP implementation strategy is the Interleaved Pipeline:

As illustrated, through a strategic pipeline parallel design, we can reduce bubbles and enhance GPU utilization.
It is worth noting that PP only requires the transmission of batch data results between adjacent model layers. Furthermore, we can overlap computation and communication to further reduce overhead. Therefore, PP generally requires the least amount of communication and is often implemented across nodes, allowing intra-node high bandwidth communication to be reserved for Tensor Parallelism (TP).
Note: we usually do not use PP for inference unless we don’t have enough memory, because for inference, there will not be enough data and therefore a lot of bubbles.
Tensor Parallel(Model Parallel)
Tensor Parallelism, also known as Model Parallelism, is a computational optimization technique where each GPU processes only a part of the tensor (unlike Pipeline Parallelism, which handles different layers, Tensor Parallelism splits a single layer of the model) and aggregates the parts only when necessary.
For example, consider the operation Y = GELU(XA), where Y is the output, X is the input, A represents the model weights, and GELU is a nonlinear activation function.
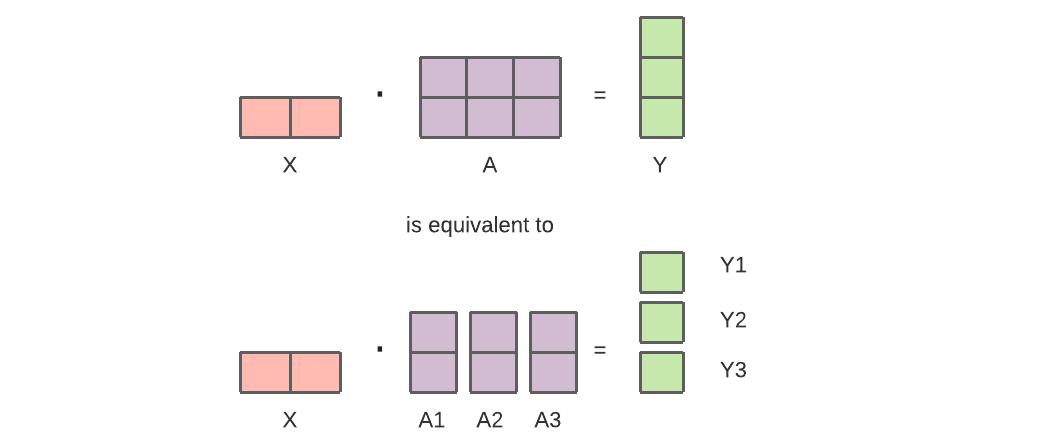
In this setup, the segments of A (A1, A2, A3) can be distributed across different GPUs to save on memory usage.
There are two primary methods of splitting in Tensor Parallelism: row parallel and column parallel:
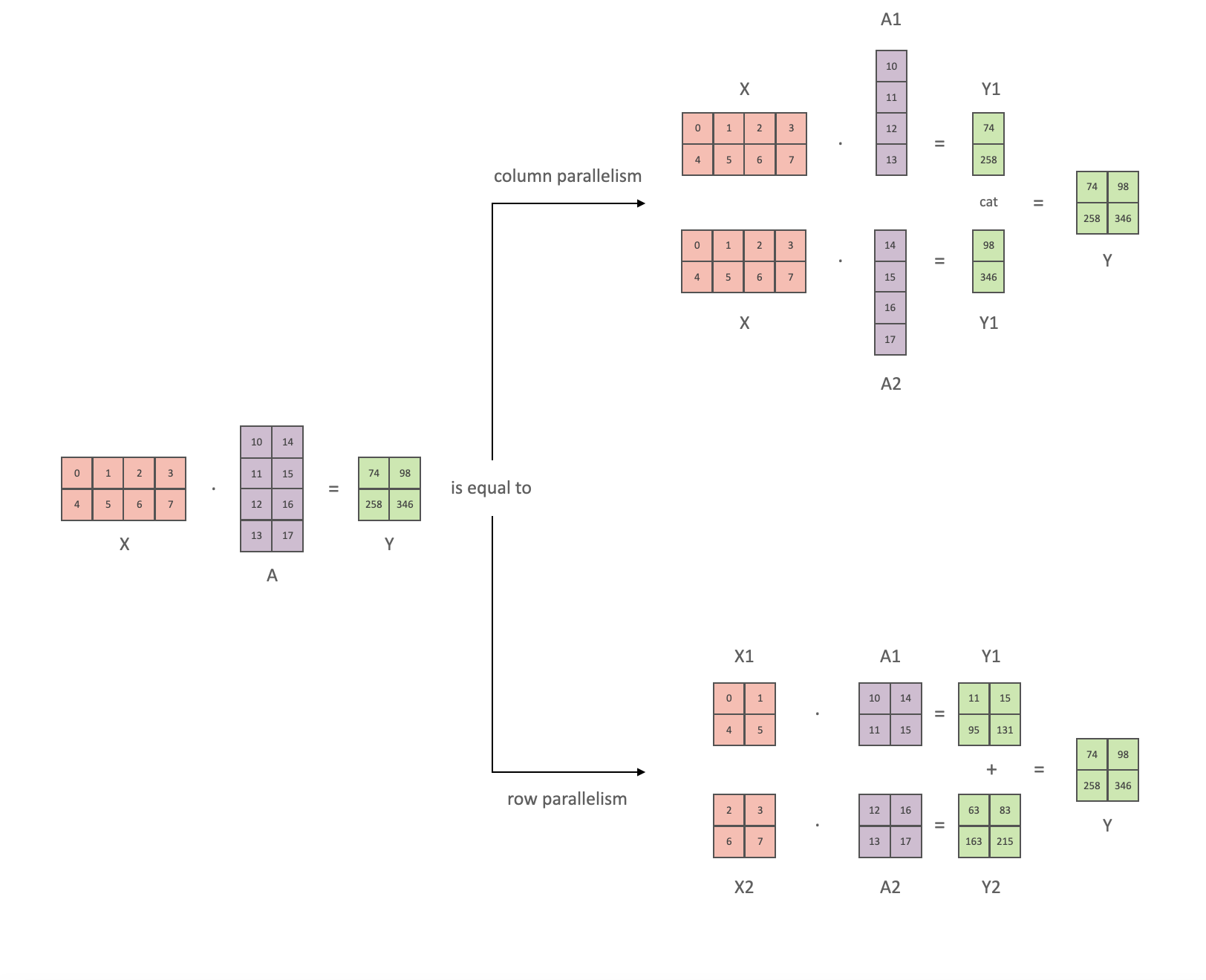
In column parallelism, the model parameters are divided by columns (4*1), and the output (2*1) is concatenated to produce the final result (2*2). The input data (2*4) remains unpartitioned.
Row parallelism, on the other hand, partitions the input data by columns (2*2) and divides the model parameters by rows (2*2). The dot products are then summed to produce the result (2*2).
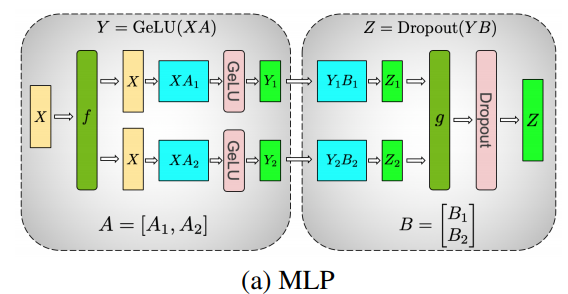
Tensor Parallelism can be directly incorporated into model designs such as the Multi-Layer Perceptron (MLP):
Another example is the Multi-Head Attention (MHA), which naturally supports parallel processing, making the introduction of Tensor Parallelism straightforward:
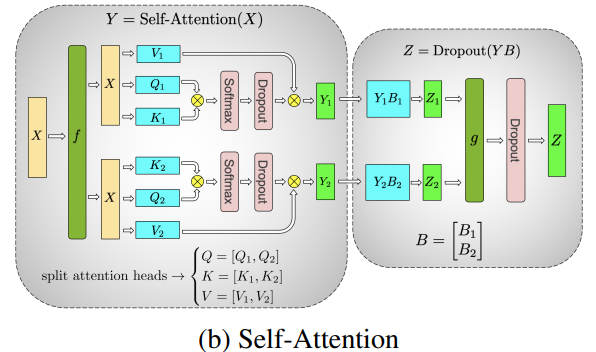
Note: Since Tensor Parallelism often requires gathering data across GPUs after computation, it typically involves significant communication overhead. It is not advisable to use Tensor Parallelism across different nodes (keep tp_size < GPUs per node).
Additionally, after partitioning, the amount of forward activation values each GPU needs to store is also divided, which can effectively reduce memory consumption.
Instance Introduction
DP + PP
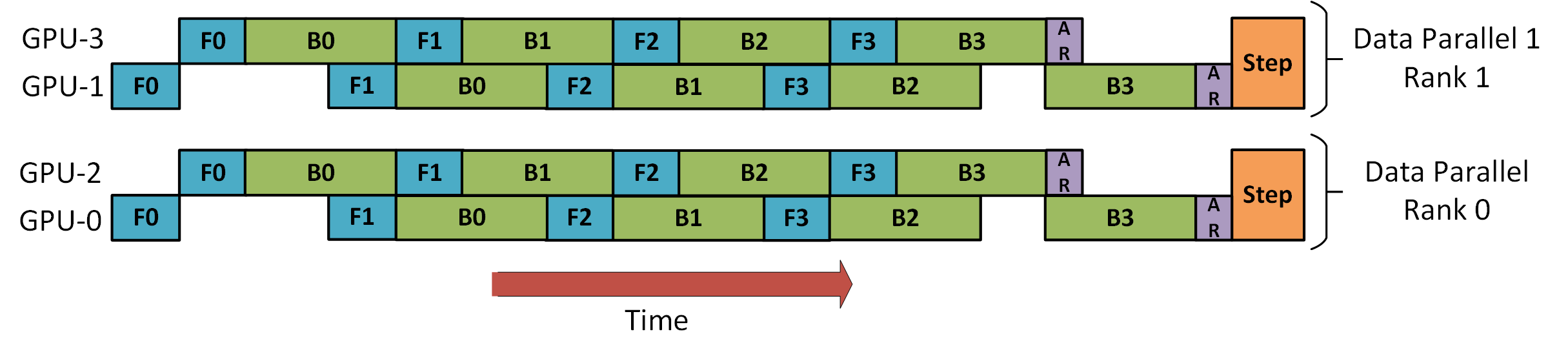
As shown in the diagram, there are 4 GPUs configured with 2 DP + 2 PP. The GPUs GPU[0, 2] and GPU[1, 3] form Pipeline Parallelism (PP) communication groups, while GPU[0, 1] form a Data Parallelism (DP) communication group.
For DP, only GPUs 0 and 1 are visible to each other, and GPUs 2 and 3 are “invisible.” During training, DP divides the data between the two visible GPUs. GPUs 0 and 1 then covertly delegate part of their tasks to GPUs 2 and 3 using PP.
Zero(DP) + PP + TP
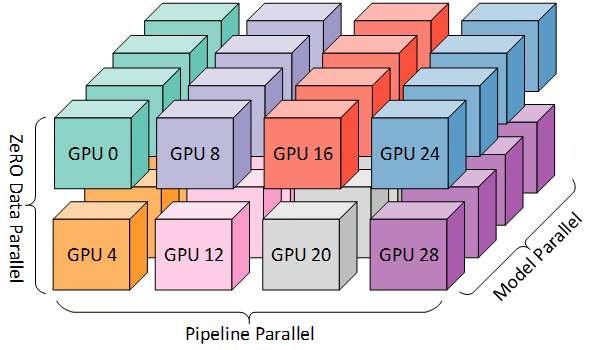
This setup involves eight nodes with a total of 32 GPUs, each node equipped with four GPUs. The Tensor Parallelism (TP) communication groups are set to the same node. Then, Pipeline Parallelism (PP) is set to 4, and Data Parallelism (DP) to 2, achieving a three-dimensional parallel training structure.
Zero can be seen as a highly scalable form of DP, compatible with both PP and TP, but typically only suitable for Zero Stage 1.
This limitation arises because introducing Zero Stage 2 gradient partitioning means that each micro-batch operation would require a communication step to aggregate gradients. With PP naturally employing more micro-batches, this increases the communication overhead. Moreover, after introducing PP, the model is layered, and the gradient sizes become 1 / PP_size, reducing the effectiveness of memory savings. Therefore, Zero Stage 2 is generally not used in conjunction with PP.
Referrence
- Microsoft Research Blog: “Zero DeepSpeed: New System Optimizations Enable Training Models with Over 100 Billion Parameters”
- Hugging Face Transformers Documentation: “Parallelism Techniques”
- Google AI Blog: “Introducing GPipe: An Open Source Library for Efficiently Training Large-scale Neural Network Models”
- AWS SageMaker Documentation: “Model Parallel Core Features”
- Arxiv Preprint: “An Analysis of Model Parallelism in Training Large-scale Neural Networks”
- DeepSpeed Tutorial: “Pipeline Parallelism Tutorial”
- Microsoft Research Blog: “DeepSpeed: Extreme-Scale Model Training for Everyone”
- Hugging Face Documentation: “Training Large Models: A Deep Dive on GPU Performance”