Deep Dive into PyTorch Device Copy Operations
Summary
This blog provides a overview of the different types of Device Copy operations within PyTorch, including Host to Device (H2D), Device to Host (D2H), and Device to Device (D2D) transfers.
0. Introduction
There are primarily two types of copy operations in PyTorch:
- Copy In host: host to host (cpu to cpu)
- Copy On device: including D2H/H2D/D2D, etc.
We have introduced the mechanism of H2H in in deep_dive_into_contiguous
In this article, we will focus primarily on device copy operation.
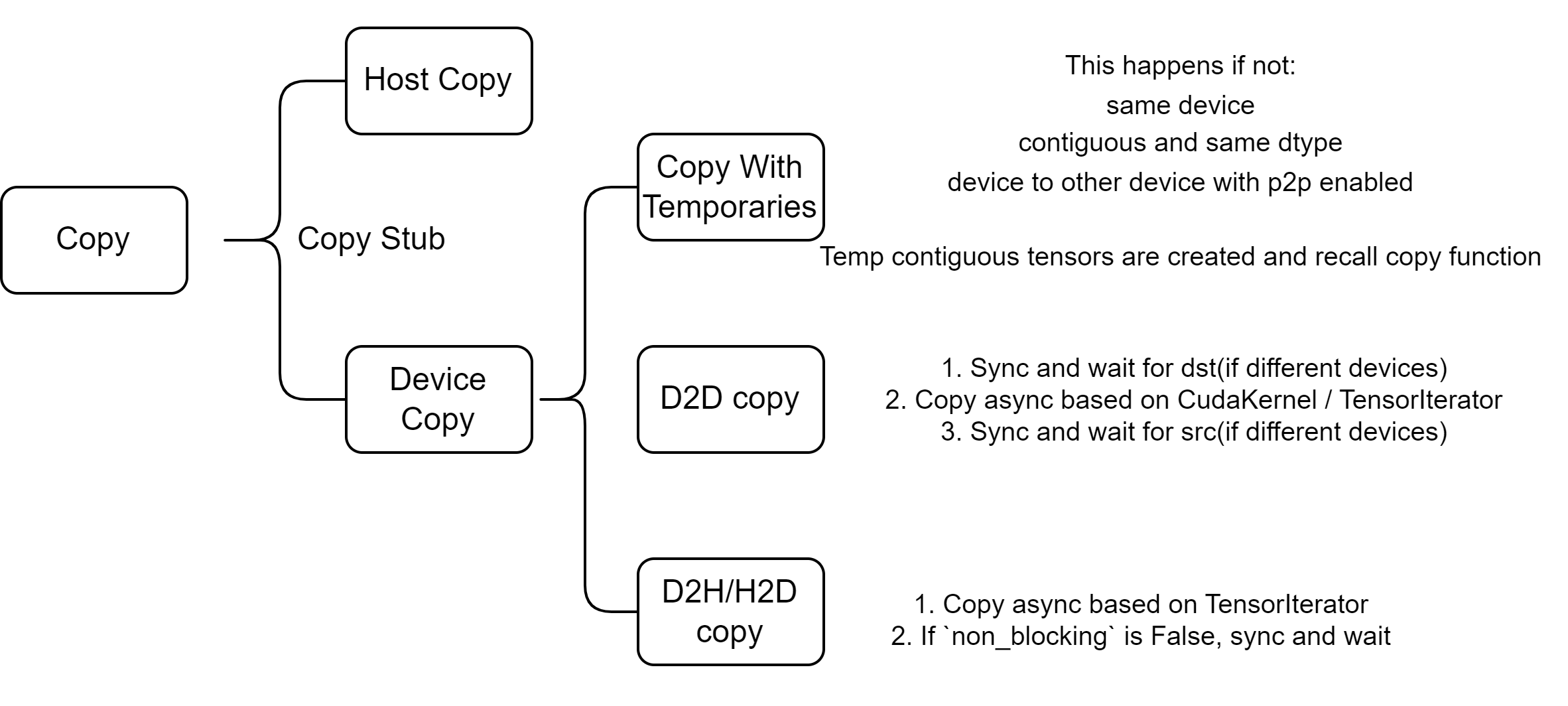
1. Copy Stub
The entry point for all types of copy operations is located in Copy.cpp.
// aten/src/ATen/native/Copy.cpp
static Tensor & copy_impl(Tensor & self, const Tensor & src, bool non_blocking) {
// ...
if (self.is_same(src)) {
return self;
}
// Exit early if self and src are views of the same data
const bool is_same_data = (
self.is_alias_of(src) &&
self.storage_offset() == src.storage_offset() &&
self.strides().equals(src.strides()) &&
self.sizes().equals(src.sizes()) &&
self.scalar_type() == src.scalar_type() &&
self.is_conj() == src.is_conj() &&
self.is_neg() == src.is_neg()
);
if (is_same_data) {
return self;
}
auto iter = TensorIteratorConfig()
.add_output(self)
.add_input(src)
.resize_outputs(false)
.check_all_same_dtype(false)
.check_all_same_device(false)
.build();
if (iter.numel() == 0) {
return self;
}
DeviceType device_type = iter.device_type(0);
if (iter.device_type(1) == kCUDA) {
device_type = kCUDA;
} else if (iter.device_type(1) == kHIP) {
device_type = kHIP;
} else if (iter.device_type(1) == kMPS) {
device_type = kMPS;
}
// ...
copy_stub(device_type, iter, non_blocking);
return self;
}After constructing a TensorIterator, the copy_stub function is invoked:
// aten/src/ATen/native/DispatchStub.h
template <typename rT, typename T, typename... Args>
struct DispatchStub<rT (*)(Args...), T> {
public:
template <typename... ArgTypes>
rT operator()(DeviceType device_type, ArgTypes&&... args) {
FnPtr call_ptr = get_call_ptr(device_type);
return (*call_ptr)(std::forward<ArgTypes>(args)...);
}
}Note that the kernel(call_ptr) is registered through DispatchStub. This registration process is declared in both Copy.cpp and Copy.h.
// aten/src/ATen/native/Copy.cpp
DEFINE_DISPATCH(copy_stub); // struct copy_stub copy_stub;
// torch/include/ATen/native/Copy.h
DECLARE_DISPATCH(copy_fn, copy_stub);
/* `DECLARE_DISPATCH` expands to:
struct copy_stub : DispatchStub<copy_fn, copy_stub> {
copy_stub() = default;
copy_stub(const copy_stub&) = delete;
copy_stub& operator=(const copy_stub&) = delete;
};
extern __attribute__((__visibility__("default"))) struct copy_stub copy_stub
*/Furthermore, the kernel is specifically registered for a particular device:
// For CPU kernel
// aten/src/ATen/native/cpu/CopyKernel.cpp
REGISTER_DISPATCH(copy_stub, ©_kernel);
// For Cuda kernel
// aten/src/ATen/native/cuda/Copy.cu
REGISTER_DISPATCH(copy_stub, ©_kernel_cuda);
// Expand to: static RegisterCUDADispatch<struct copy_stub> copy_stub__register(copy_stub, ©_kernel_cuda);
// torch/include/ATen/native/DispatchStub.h
template <typename DispatchStub>
struct RegisterCUDADispatch {
RegisterCUDADispatch(DispatchStub &stub, typename DispatchStub::FnPtr value) {
stub.set_cuda_dispatch_ptr(value);
}
};2. Copy with Device
Upon dispatch, the copy_kernel_cuda function is executed:
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
AT_ASSERT(iter.ntensors() == 2);
Device dst_device = iter.device(0);
Device src_device = iter.device(1);
// Enable p2p access between devices.
bool p2p_enabled = maybe_enable_p2p_access(dst_device, src_device);
if (copy_requires_temporaries(iter, p2p_enabled)) {
// ...
return;
}
// Copy on GPU (or between GPUs)
if (dst_device.is_cuda() && src_device.is_cuda()) {
copy_device_to_device(iter, non_blocking, p2p_enabled);
return;
}
// Copy between CPU and GPU
// ...
}This process can generally be segmented into three distinct parts:
- Copy utilizing temporaries
- Copy on the GPU, or between GPUs if P2P (Peer-to-Peer, referring to direct memory access between one GPU and another) is enabled
- Copy between the CPU and GPU, which do not require the use of temporaries
2.1 Copy with Temporaries
We don’t need to consider temporaries if:
- Same Device Copy: No temporaries are needed.
- Contiguous and Same Dtype Copy: No temporaries are needed.
- Device-to-Device Copy with P2P Enabled: No temporaries are needed.
In other cases, copy_requires_temporaries returns True and we utilize temporary contiguous tensors to facilitate the copy.
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
if (copy_requires_temporaries(iter, p2p_enabled)) {
auto& dst = iter.tensor(0);
Tensor dst_contig;
Tensor src_contig;
if (iter.device_type(0) == kCUDA || non_blocking) {
// if branch: In cuda or non_blocking is set
// uses dst if dst is contiguous, otherwise uses an empty contiguous tensor
dst_contig = dst.is_contiguous() ? dst : at::empty_like(dst, LEGACY_CONTIGUOUS_MEMORY_FORMAT);
// src is the same dtype and shape with dst, contiguous
src_contig = iter.tensor(1).to(iter.dtype(0)).expand_as(dst).contiguous();
} else {
// else branch: not in cuda and non_blocking is false
bool same_type = iter.dtype(0) == iter.dtype(1);
// uses dst if dst is contiguous and has the same dtype with src
dst_contig = (dst.is_contiguous() && same_type) ? dst : at::empty_like(dst, iter.dtype(1), LEGACY_CONTIGUOUS_MEMORY_FORMAT);
// src has the shape with dst, contiguous
src_contig = iter.tensor(1).expand_as(dst).contiguous();
}
// ...
// perform a same-dtype copy on contiguous tensors
dst_contig.copy_(src_contig, non_blocking);
// if necessary, copy back into dst
if (!dst_contig.is_same(dst)) {
TORCH_INTERNAL_ASSERT(dst_contig.device() == dst.device());
dst.copy_(dst_contig, non_blocking);
}
return;
}
}
static bool copy_requires_temporaries(TensorIterator& iter, bool p2p_enabled) {
// ...
if (dst_device == src_device) {
// same device, no temporaries needed
return false;
}
bool same_dtype = iter.dtype(0) == iter.dtype(1);
if (same_dtype && iter.is_contiguous()) {
// Contiguous same-dtype copies can always use `cudaMemcpyAsync`
return false;
} else if (dst_device.is_cuda() && src_device.is_cuda()) {
// Copies between GPUs can use the copy kernel if P2P is supported
return !p2p_enabled;
} else {
// The remaining cases require temporaries.
return true;
}
}Here temporary tensors such as dst_contig and src_contig are created, followed by the reuse of copy_. Now that all inputs are contiguous, we can proceed to other branches below and complete the copy.
Finally, if necessary, the data is copied back into the dst tensor as outlined in the code.
2.2 Copy on GPU
When both tensors reside on the GPU, a D2D copy occurs.
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
if (dst_device.is_cuda() && src_device.is_cuda()) {
copy_device_to_device(iter, non_blocking, p2p_enabled);
return;
}
// ...
}
void copy_device_to_device(TensorIterator& iter,
bool non_blocking,
bool p2p_enabled) {
int64_t numel = iter.numel();
// We can directly use memcpy if memcpy_eligible
bool same_type = iter.dtype(0) == iter.dtype(1);
bool same_conj = iter.tensor(0).is_conj() == iter.tensor(1).is_conj();
bool same_neg = iter.tensor(0).is_neg() == iter.tensor(1).is_neg();
bool memcpy_eligible = same_type && same_conj && same_neg && iter.is_contiguous();
Device dst_device = iter.device(0);
Device src_device = iter.device(1);
// device guard is used to set/restore the current device context
CUDAGuard device_guard(src_device);
CUDAStream copy_stream = getCurrentCUDAStream(src_device.index());
if (src_device != dst_device) {
// sync ...
}
if (memcpy_eligible) {
// same dtype, contiguous, same conjugation and negation
void *dst = iter.data_ptr(0);
void *src = iter.data_ptr(1);
size_t size = numel * iter.element_size(0);
if (src != dst || src_device != dst_device) {
// Due to bizarre cuda driver intricacies, copies of
// cudaMallocAsynced memory between devices that aren't
// peer-to-peer-capable need "cudaMemcpyPeerAsync".
bool needs_pool_specific_peer_access = CUDACachingAllocator::get()->needsPoolSpecificPeerAccess();
bool needs_MemcpyPeer = (src_device != dst_device &&
needs_pool_specific_peer_access &&
!p2p_enabled);
if (needs_MemcpyPeer) {
AT_CUDA_CHECK(cudaMemcpyPeerAsync(
dst, dst_device.index(),
src, src_device.index(),
size, copy_stream));
} else {
AT_CUDA_CHECK(cudaMemcpyAsync(
dst, src, size,
cudaMemcpyDeviceToDevice,
copy_stream));
}
}
} else {
if (same_neg) {
if (!same_conj) {
conj_kernel_cuda(iter);
} else {
direct_copy_kernel_cuda(iter);
}
} else {
if (!same_conj) {
neg_conj_kernel_cuda(iter);
} else {
neg_kernel_cuda(iter);
}
}
}
if (src_device != dst_device) {
// sync
}
AT_CUDA_CHECK(cudaGetLastError());
}This process is divided into three main stages:
- Block and wait for the dst tensor.(synchronization 1)
- Perform the copy asynchronously.
- Block and wait for the src tensor.(synchronization 2)
The logic for asynchronous copying is straightforward: If memcpy_eligible, we directly use cudaMemcpyPeerAsync or cudaMemcpyAsync.
If not, some other operations are performed. For example, in the case of direct_copy_kernel_cuda (for tensors have the same conj and neg conditions):
// aten/src/ATen/native/cuda/Copy.cu
void direct_copy_kernel_cuda(TensorIteratorBase &iter) {
ScalarType dtype = iter.dtype(0);
if (isQIntType(dtype)) {
AT_DISPATCH_QINT_TYPES(dtype, "copy_", [&] {
gpu_kernel(iter, [] GPU_LAMBDA(scalar_t x) { return x; });
});
} else {
AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND4(
kHalf, kBool, kBFloat16, kComplexHalf, dtype, "copy_", [&] {
gpu_kernel(iter, [] GPU_LAMBDA(scalar_t x) { return x; });
});
}
}Here we employ gpu_kernel to launch a CUDA kernel using the data pointers calculated in TensorIterator and a simple lambda function return x;. This section will not be expanded upon here, but for those interested, more information can be found in my document on TensorIterator.
Regarding synchronization, there are two blocking points in the code, one at the src stream and one at the dst stream:
// aten/src/ATen/native/cuda/Copy.cu
void copy_device_to_device(TensorIterator& iter,
bool non_blocking,
bool p2p_enabled) {
// ...
// device guard is used to set/restore the current device context
CUDAGuard device_guard(src_device);
CUDAStream copy_stream = getCurrentCUDAStream(src_device.index());
if (src_device != dst_device) {
CUDAEvent dst_ready;
device_guard.set_device(dst_device);
// record this event in dst's stream
dst_ready.record(getCurrentCUDAStream(dst_device.index()));
device_guard.set_device(src_device);
// block until all of the operations in dst before dst_ready event are done
// Note: won't block code in CPU here, only block for cuda stream
dst_ready.block(copy_stream);
}
// ... do copy async
if (src_device != dst_device) {
CUDAEvent src_ready;
// record this event in src's stream
src_ready.record(copy_stream);
// block until all of the operations in src are done
device_guard.set_device(dst_device);
src_ready.block(getCurrentCUDAStream(dst_device.index()));
}
AT_CUDA_CHECK(cudaGetLastError());
}The first synchronization (at the src stream, waiting for the dst to be ready) ensures that all operations in dst stream preceding the dst_ready event are completed, setting the stage for the copy operation.
Then, the copy is performed asynchronously, with a task scheduled in the source stream.
Finally, synchronization occurs at the dst stream to ensure the completion of the copy operation.
With these synchronization, we can ensure the copy process is safe.
2.3 Copy between CPU and GPU (no temporaries)
This section addresses copying for contiguous tensors between hosts and GPUs.
// aten/src/ATen/native/cuda/Copy.cu
static void copy_kernel_cuda(TensorIterator& iter, bool non_blocking) {
// ...
// Copy between CPU and GPU
cuda::OptionalCUDAGuard device_guard;
cudaMemcpyKind kind;
if (dst_device.is_cuda() && src_device.is_cpu()) {
device_guard.set_device(dst_device);
kind = cudaMemcpyHostToDevice;
} else if (dst_device.is_cpu() && src_device.is_cuda()) {
device_guard.set_device(src_device);
kind = cudaMemcpyDeviceToHost;
} else {
TORCH_INTERNAL_ASSERT(false, "unsupported devices in GPU copy_()");
}
void* dst = iter.data_ptr(0);
void* src = iter.data_ptr(1);
int64_t nbytes = iter.numel() * iter.element_size(0);
CUDAStream stream = getCurrentCUDAStream();
if (non_blocking) {
AT_CUDA_CHECK(cudaMemcpyAsync(dst, src, nbytes, kind, stream));
const auto& dst_tensor = iter.tensor(0);
const auto& src_tensor = iter.tensor(1);
const auto& host_tensor = (dst_device == kCPU ? dst_tensor : src_tensor);
auto* ptr = (dst_device == kCPU ? dst : src);
auto* ctx = host_tensor.storage().data_ptr().get_context();
// record an event in current cuda stream based on the context and data ptr
// of the host tensor
CachingHostAllocator_recordEvent(ptr, ctx, stream);
} else {
at::cuda::memcpy_and_sync(dst, src, nbytes, kind, stream);
}
// ... neg and conj operations
}
// torch/include/c10/cuda/CUDAFunctions.h
C10_CUDA_API void __inline__ memcpy_and_sync(
void* dst,
void* src,
int64_t nbytes,
cudaMemcpyKind kind,
cudaStream_t stream) {
// ... gpu trace
C10_CUDA_CHECK(cudaMemcpyAsync(dst, src, nbytes, kind, stream));
C10_CUDA_CHECK(cudaStreamSynchronize(stream));
}Here using TensorIterator, we obtain the pointers for the src and dst tensors. Depending on non_blocking, we either directly call cudaMemcpyAsync and record an event or opt for memcpy_and_sync.
Note: The recorded event pertains to CUDAHostAllocator (managing the memory of host tensors). Typically, a tensor’s memory block is not reused until the event is marked ready. For those interested in Memory Cache, further details can be found in aten/src/ATen/cuda/CachingHostAllocator.cpp.
Graph Summary