CSAPP Class Notes(4)
12. Network Programming
12.1 Basic Concepts
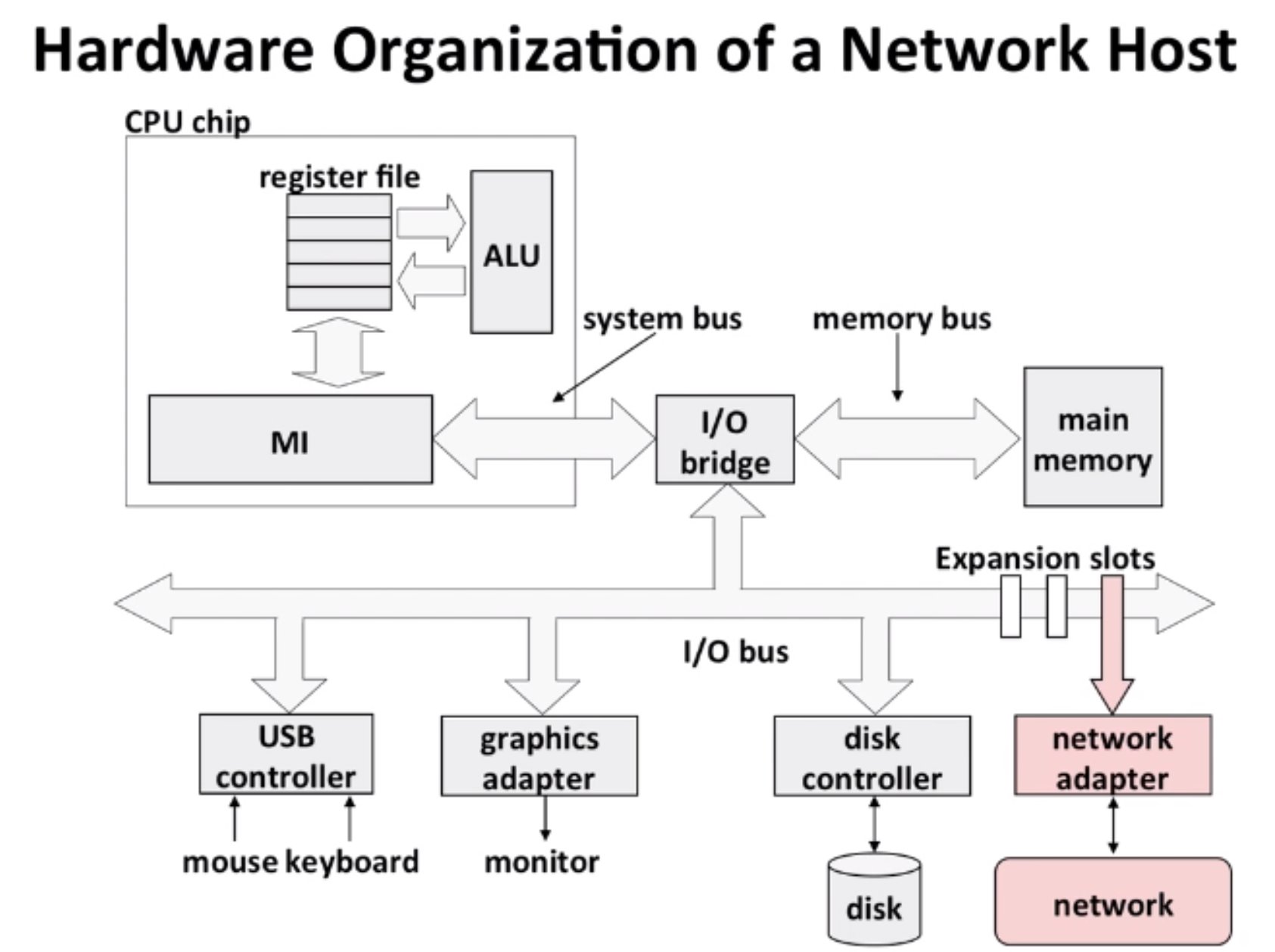
In Linux, handling network is similar to handle a file (socket interface).
Lowest Level: Ethernet Segment. eg: MAC address(00:16:ea:e3:54:e6)
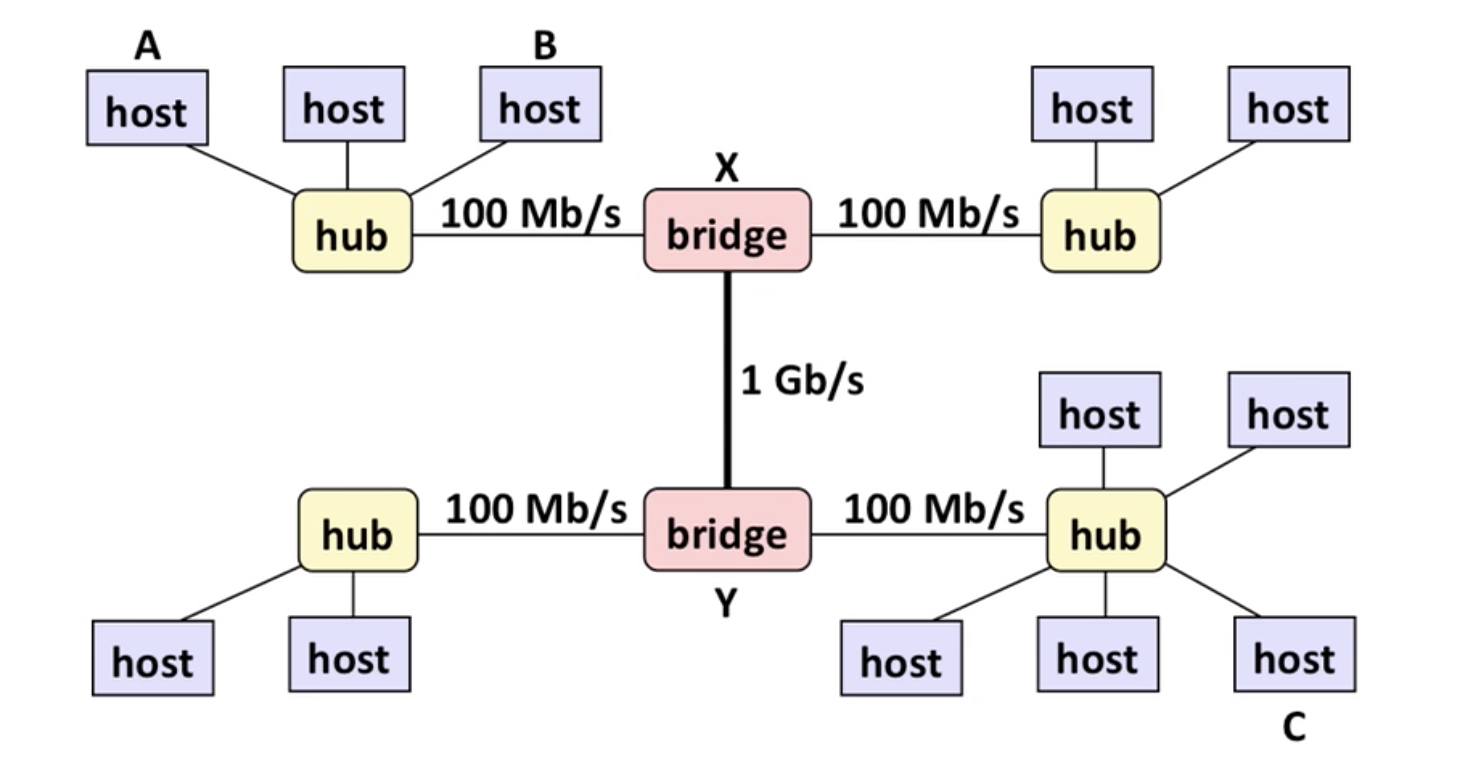
Next Level: Bridged Ethernet Segment
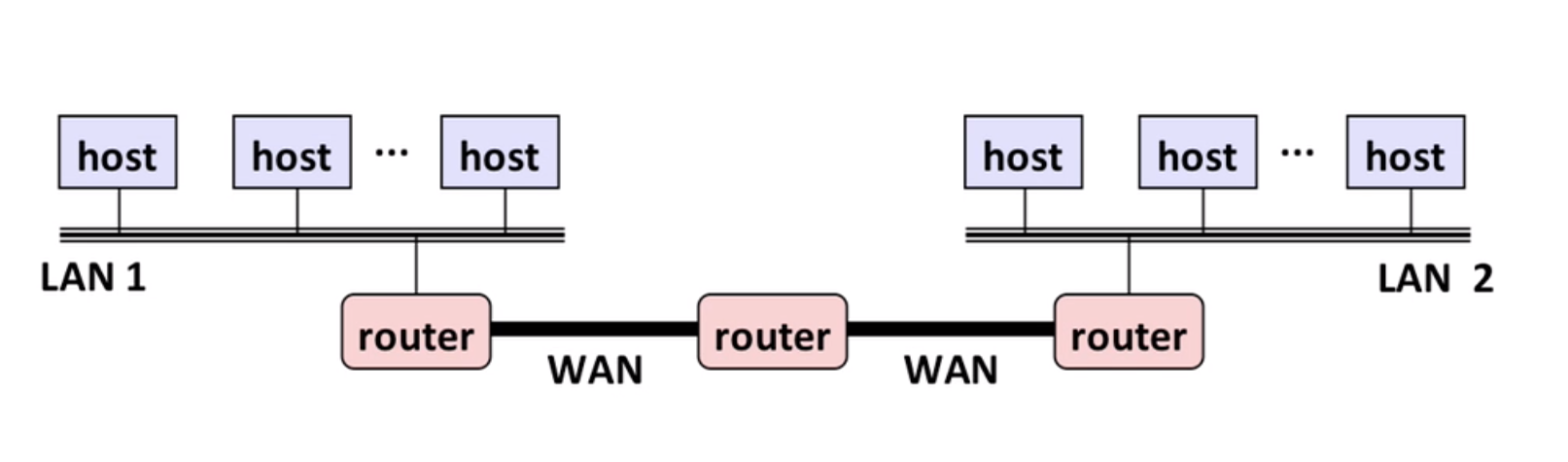
Next Level: internets - connecting multiple LANs (local area network) through routers
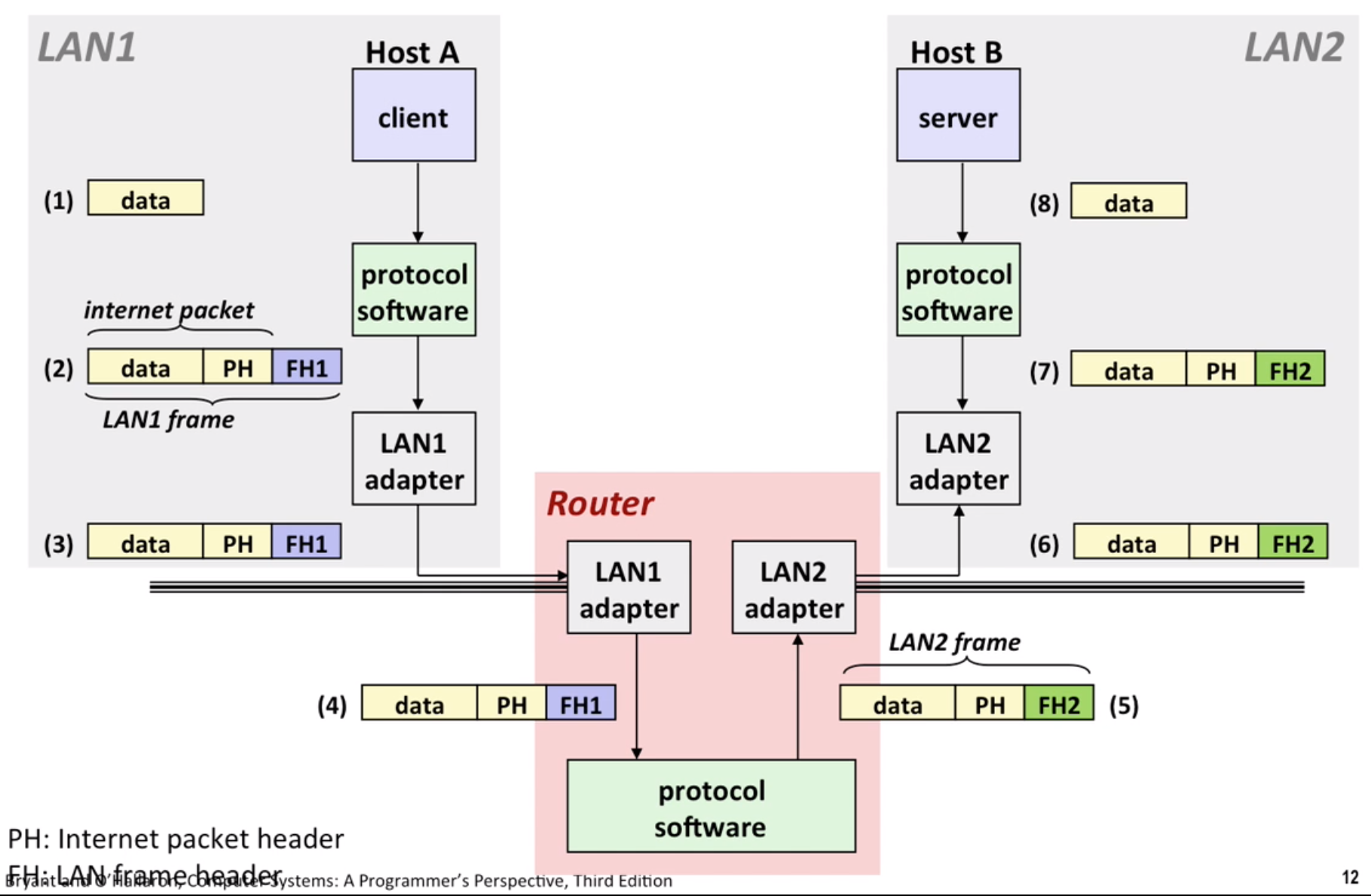
12.2 Protocol
We use Protocol to send bits across incompatible LANs and WANs (wide area network)
IP(Internet Protocol): basic naming scheme from host to host (doesn’t know send for what process)
UDP(Unreliable Datagram Protocol): Uses IP to deliver unreliable datagram from process to process
TCP(Transmission Control Protocol): Uses IP to deliver reliable byte streams from process to process over connections.
usage: TCP/IP or UDP/IP
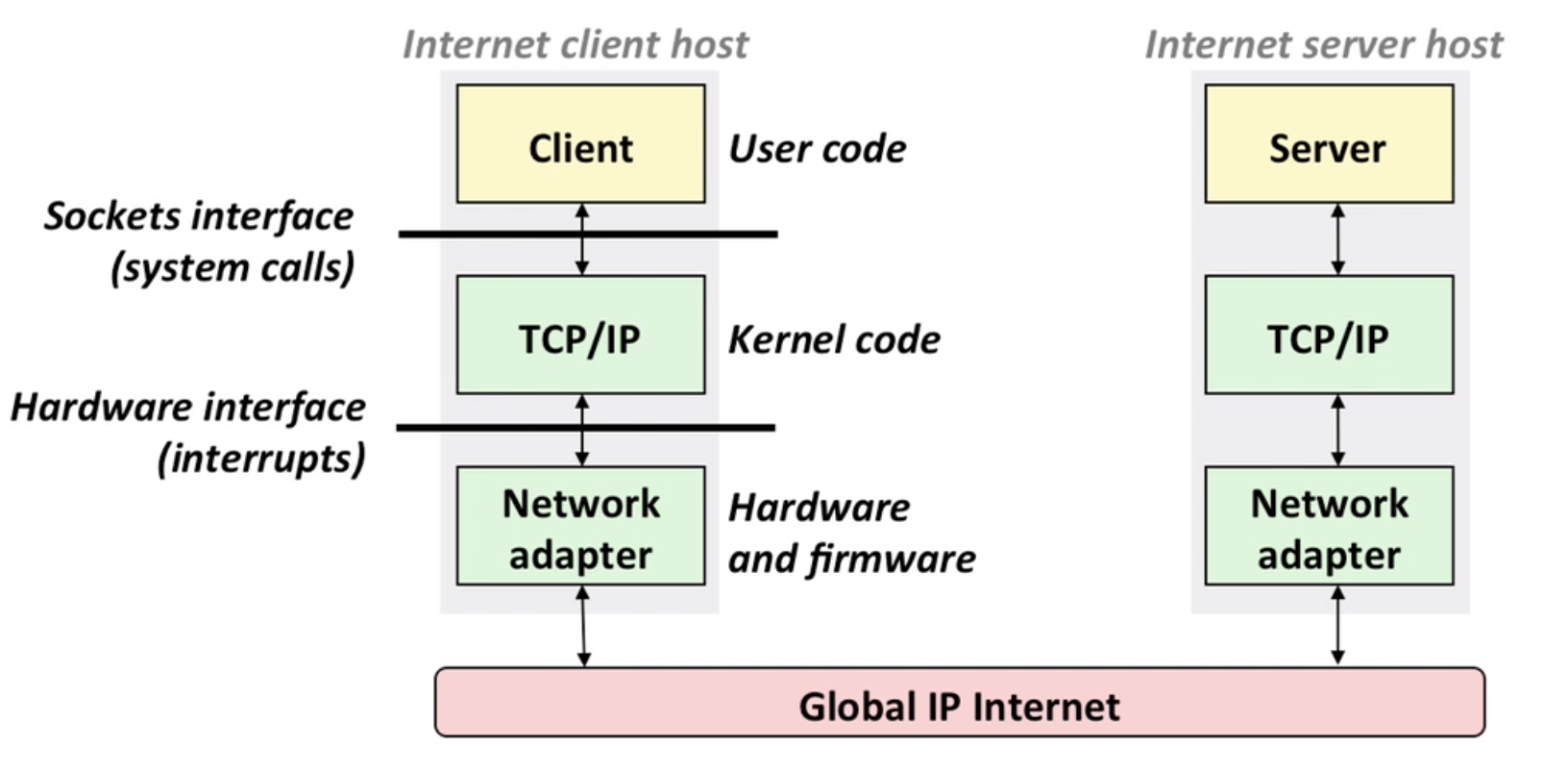
12.3 Domain names
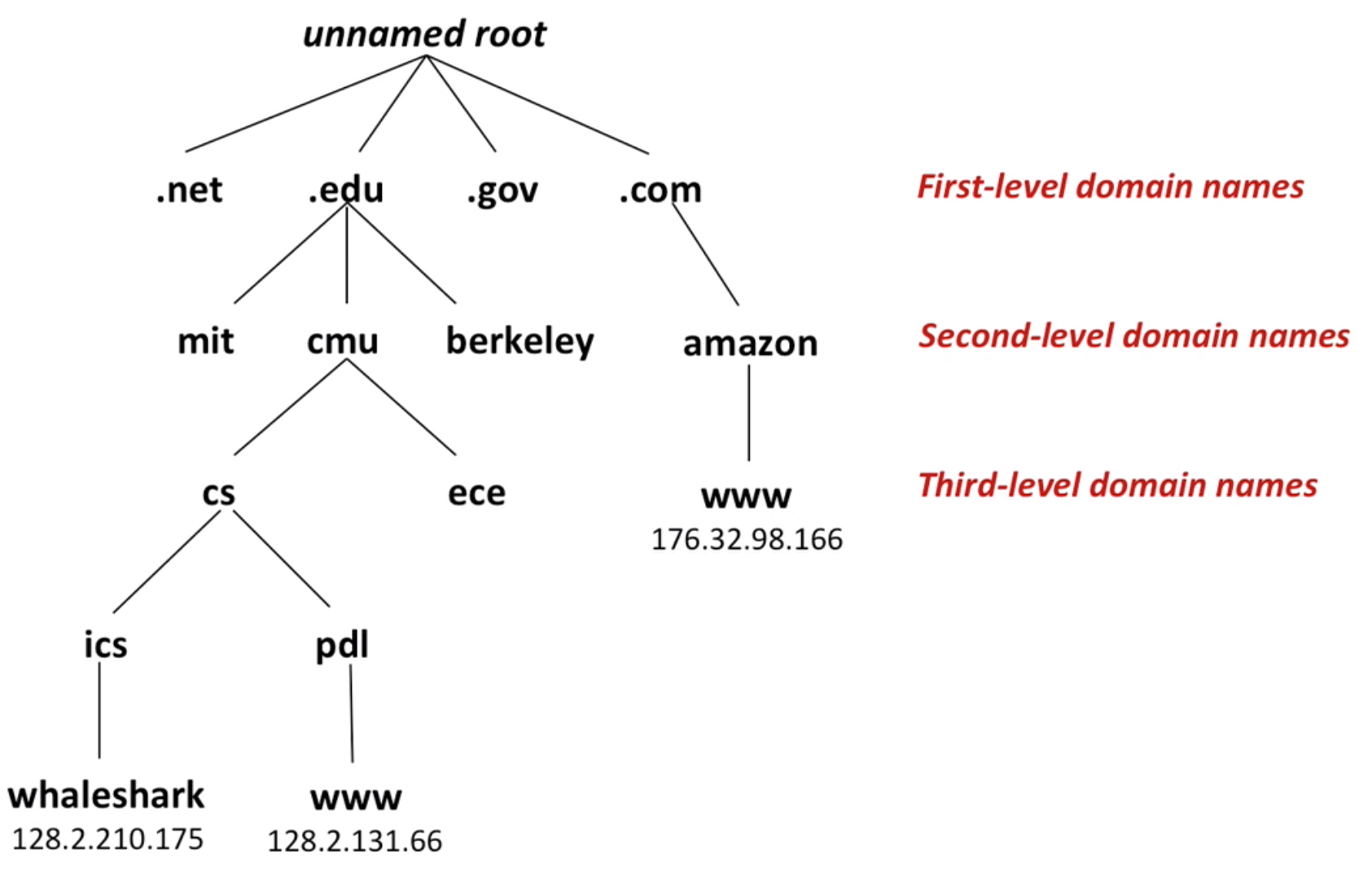
DNS (Domain Name System): Used for mapping between IP addresses and domain names. Note: mapping is multiple to multiple.
12.4 Connections
Connections features:
- point to point: connects a pair of processes
- full-duplex: data can flow in both directions
- reliable
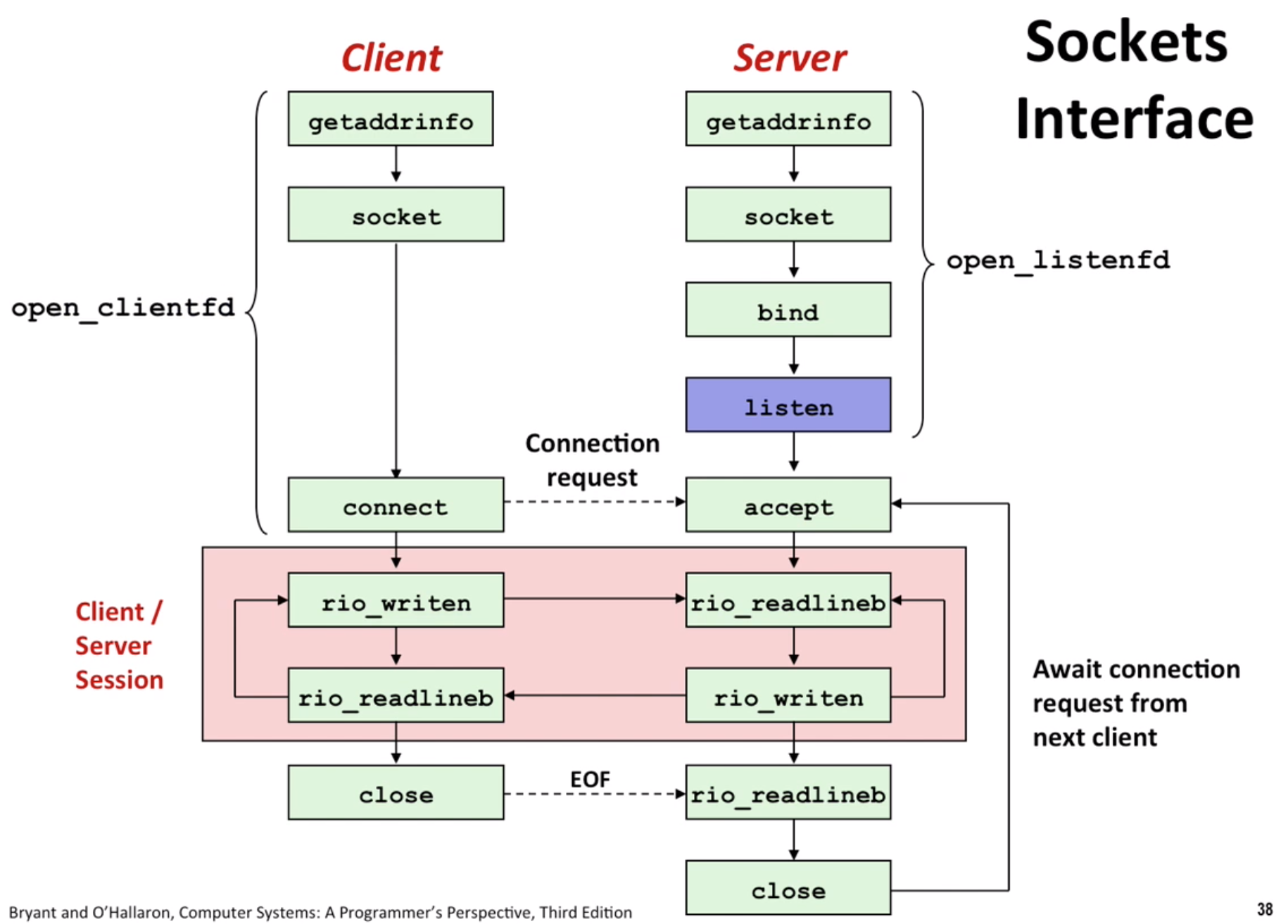
A socket is an endpoint of connection
A port identifies a process.

socket pair: to identify a connection.
A client-server model:
12.5 HTTP
HTTP: HyperText Transfer Protocol
Content: a sequence of bytes with an associated MIME(Multipurpose Internet Mail Extensions)
MIME eg: text/html, image/png
URL: Universal Resource Locator
12.6 CGI
CGI: Common Gateway Interface
Eg: http://add.com/cgi-bin/adder?15213&18213 Here the adder is a CGI
12.7 Proxy
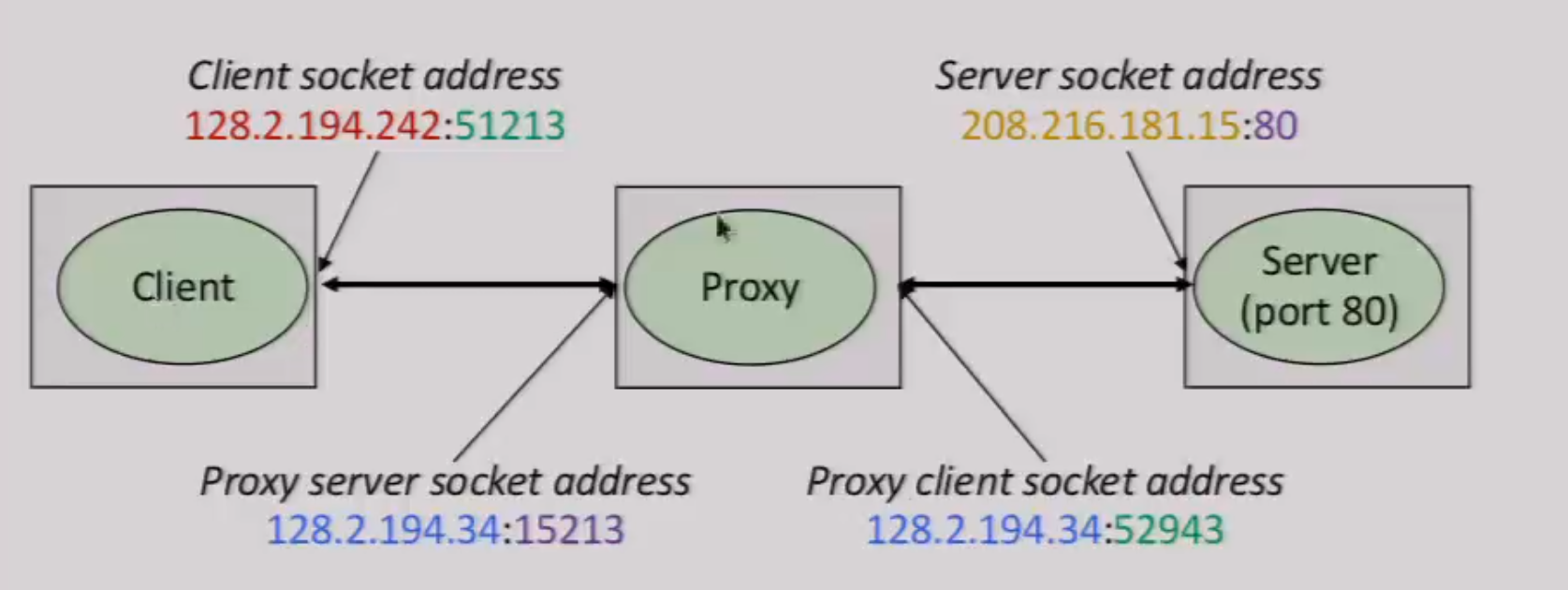
Develop your own proxy:
- Sequential proxy: easy start
- Concurrent proxy: multi-threading
- Cache Web Objects: cache separate objects, using LRU(Least Recently Used) eviction.
13. Concurrent Programming
Classical problems: Races, Deadlock, livelock/starvation/fairness
13.1 Concurrent Servers
Process-Based: fork a new process to handle connections
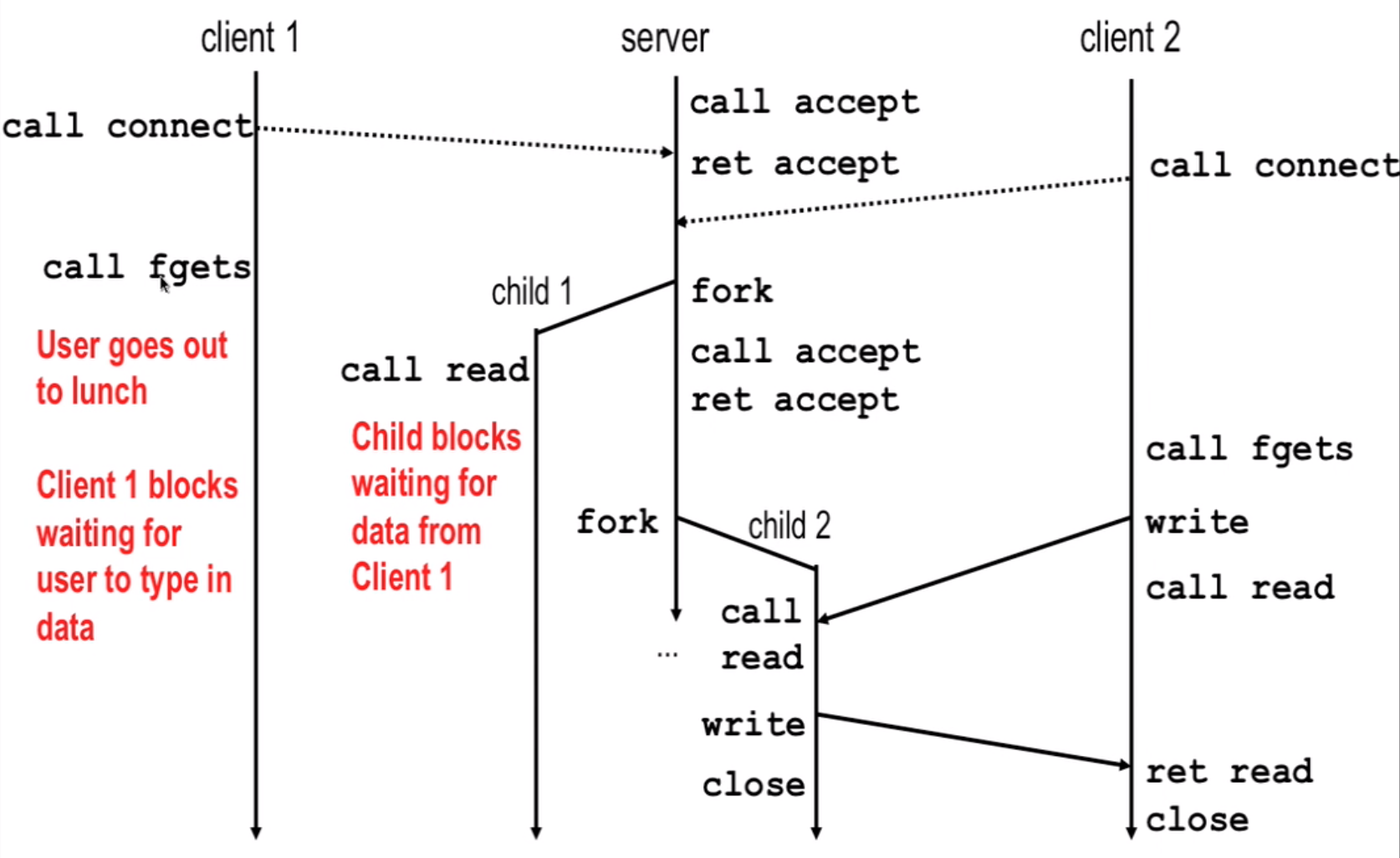
Event-Based: use i/o multiplexing technique, non-block in one process
Thread-Based: use multithreading in one process
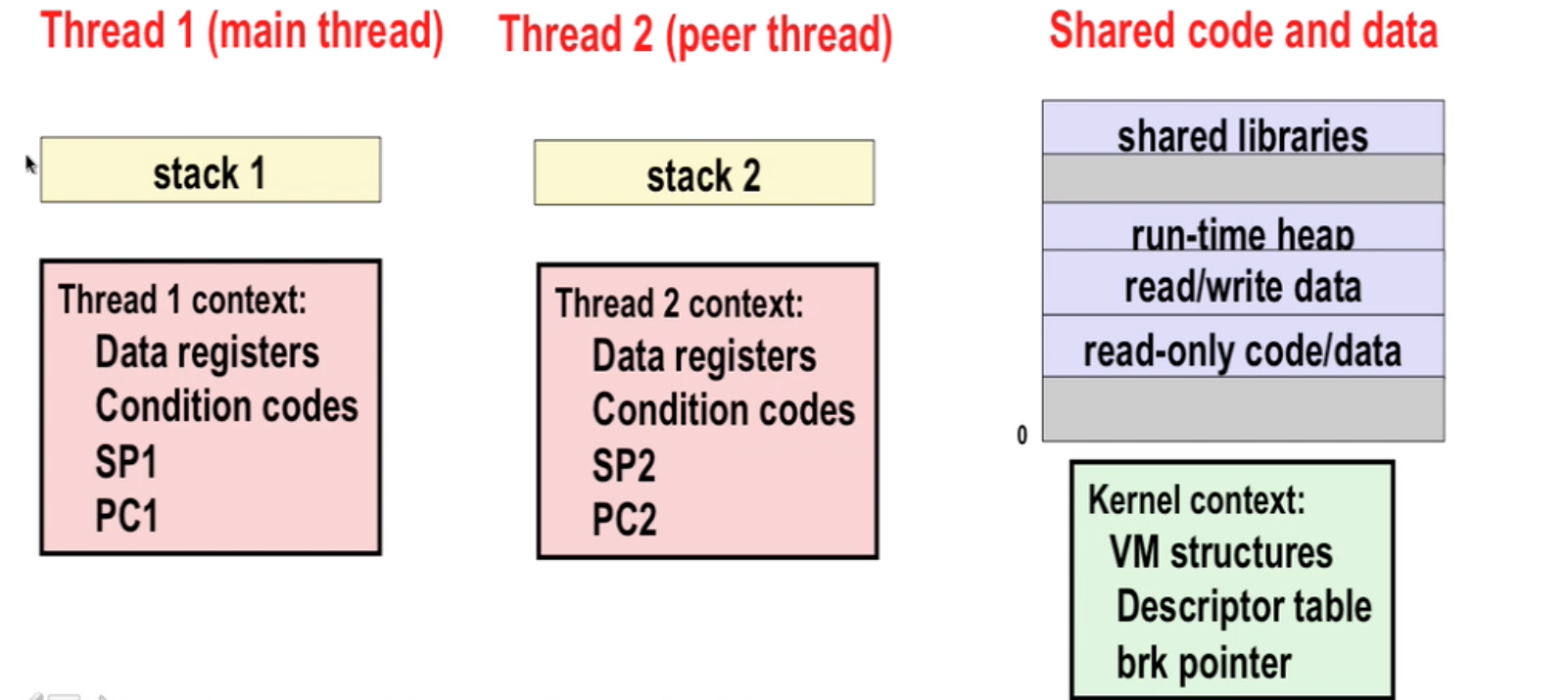
Thread:
- has its own logical control flow
- shares the same code, data and kernel context
- has its own stack for local variables (not protected from other threads)
- State:
- Joinable: can be reaped and killed by other threads(default)
- Detached: Automatically be reaped on termination
13.2 Semaphores
Non-negative global integer synchronization variable. Maintained by P and V
mutex = 1
P(mutex) // mutex -= 1
// do something
V(mutex) // mutex += 1
Producer-Consumer Example
buffer[n]
mutex = 1 // semaphore
items = 0 // semaphore
slots = n // semaphore
Reader-Writer Example–First Reader: as long as there is a reader, writer should wait

Note: mutex is only for readcnt
13.3 Prethreaded Concurrent server (thread pool)
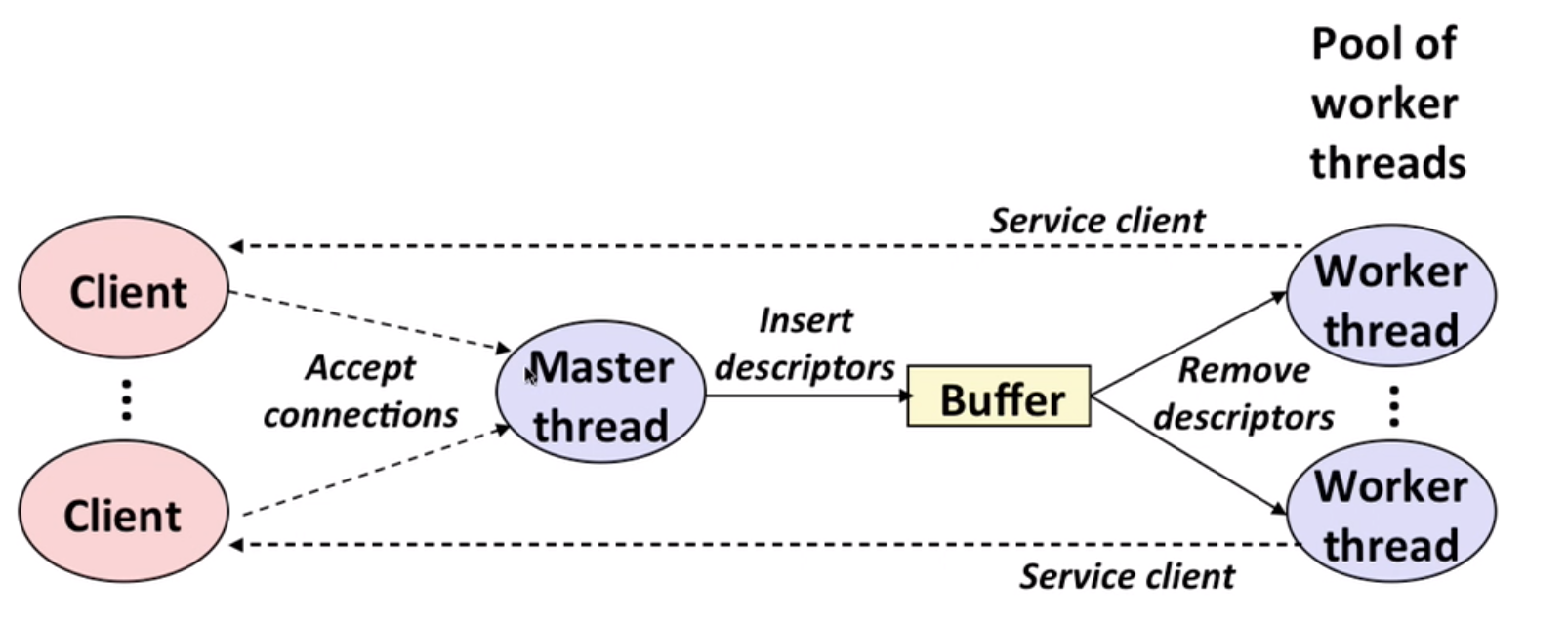
Here, we do not need to create/destroy a thread each time a connection is built.
Main idea: put a task(descriptor) into a buffer, threads in pool try to fetch the task.
13.4 Thread Safe
Key: Fail to protect shared variables
Solution: solved by lock/semaphores or try to make shared variables local.
Reentrant function: access no shared variables when called by multiple threads. Safe and efficient
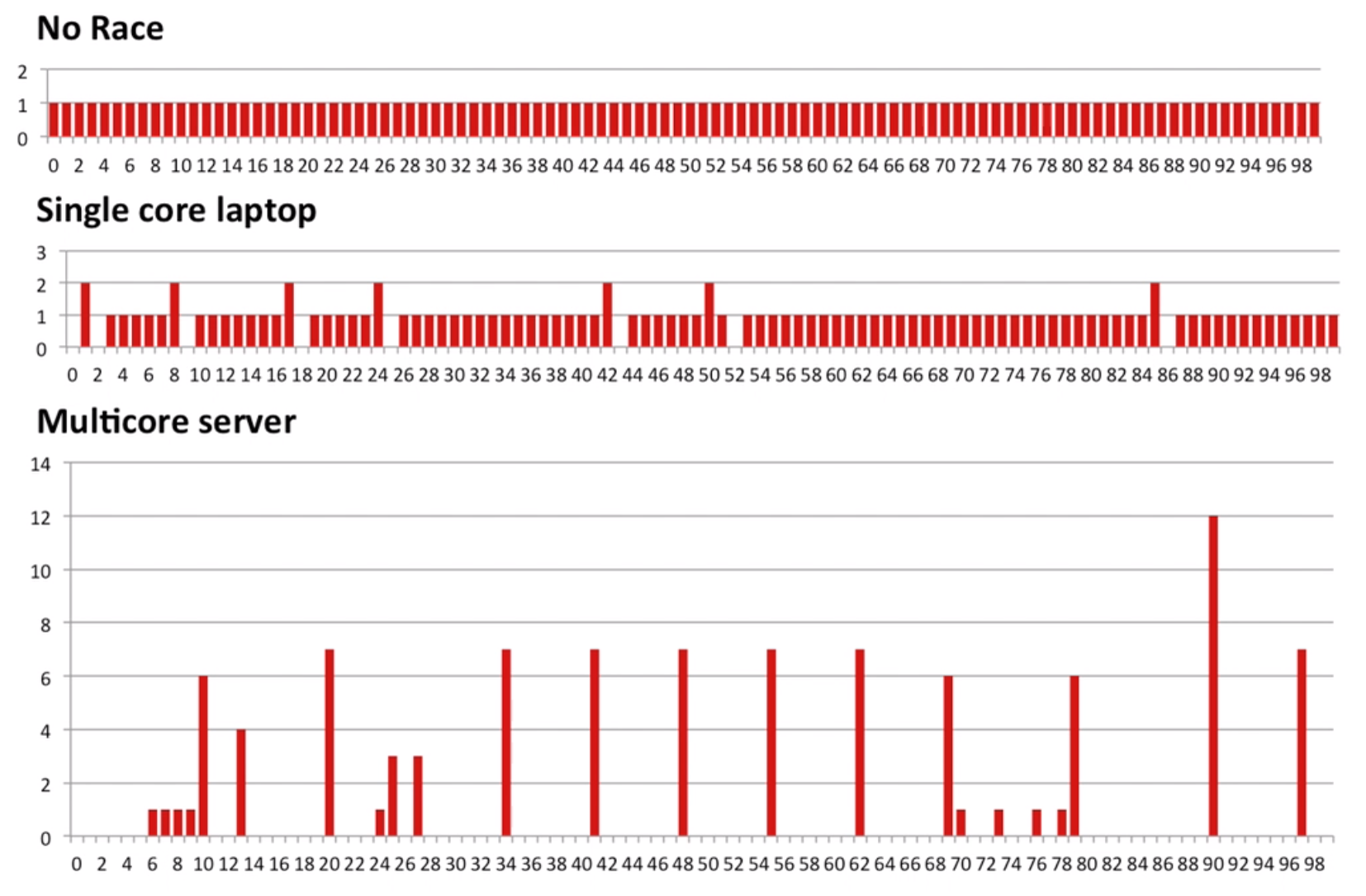
Do not race: i may = 50 when thread 0 try to fetch the value

Race Result:
Deadlock: t1 P(s0), t2 P(s1), t1 P(s1), t2 P(s0) – Deadlock!
Try to acquire resources in the same order to solve the deadlock.
Livelock: Just like deadlock, but this time it will release the lock and retry, so it looks like this:
start
t1 P(s0)
t2 P(s1)
t1 P(s1) fail
t2 P(s0) fail
t1 V(s0)
t2 V(s1)
goto start13.5 Hardwares
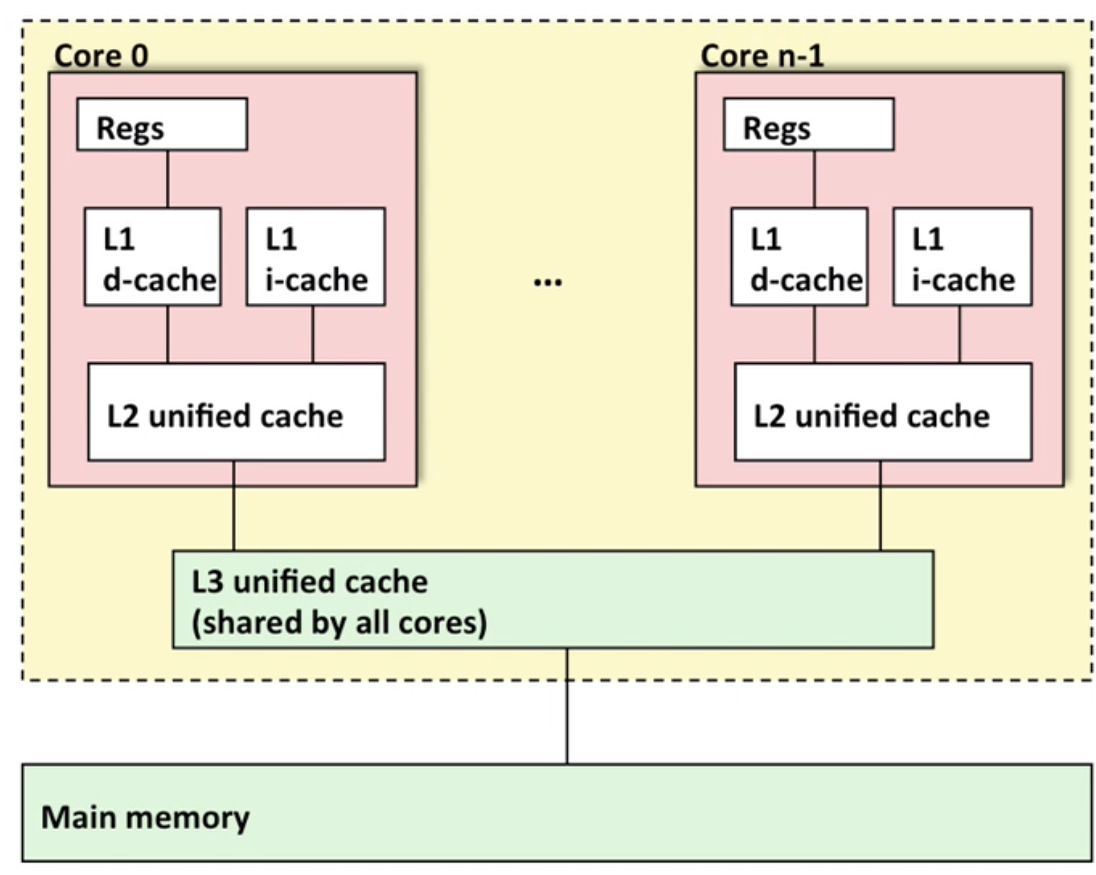
Typical multi-core processor:
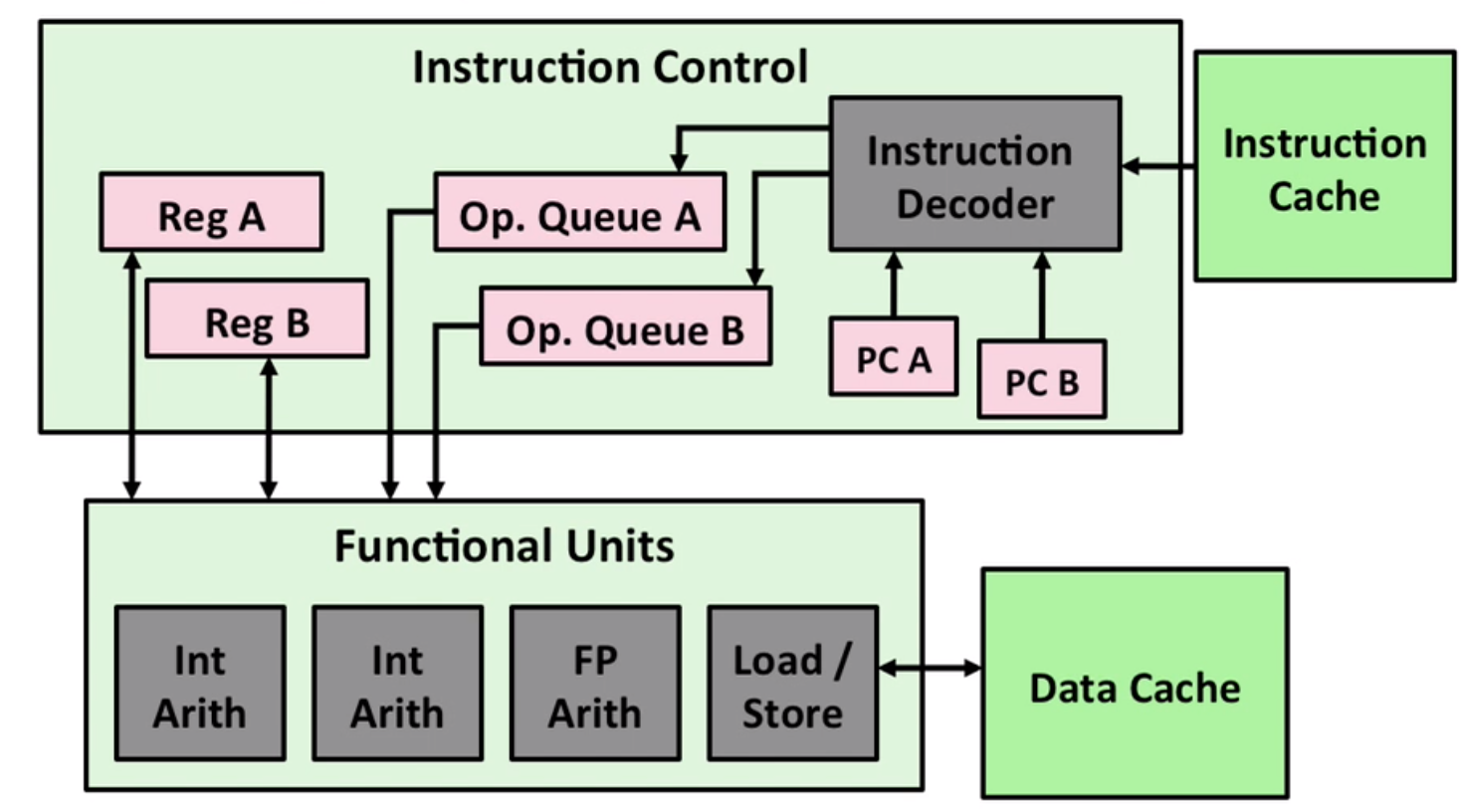
Hyper-threading implementation:
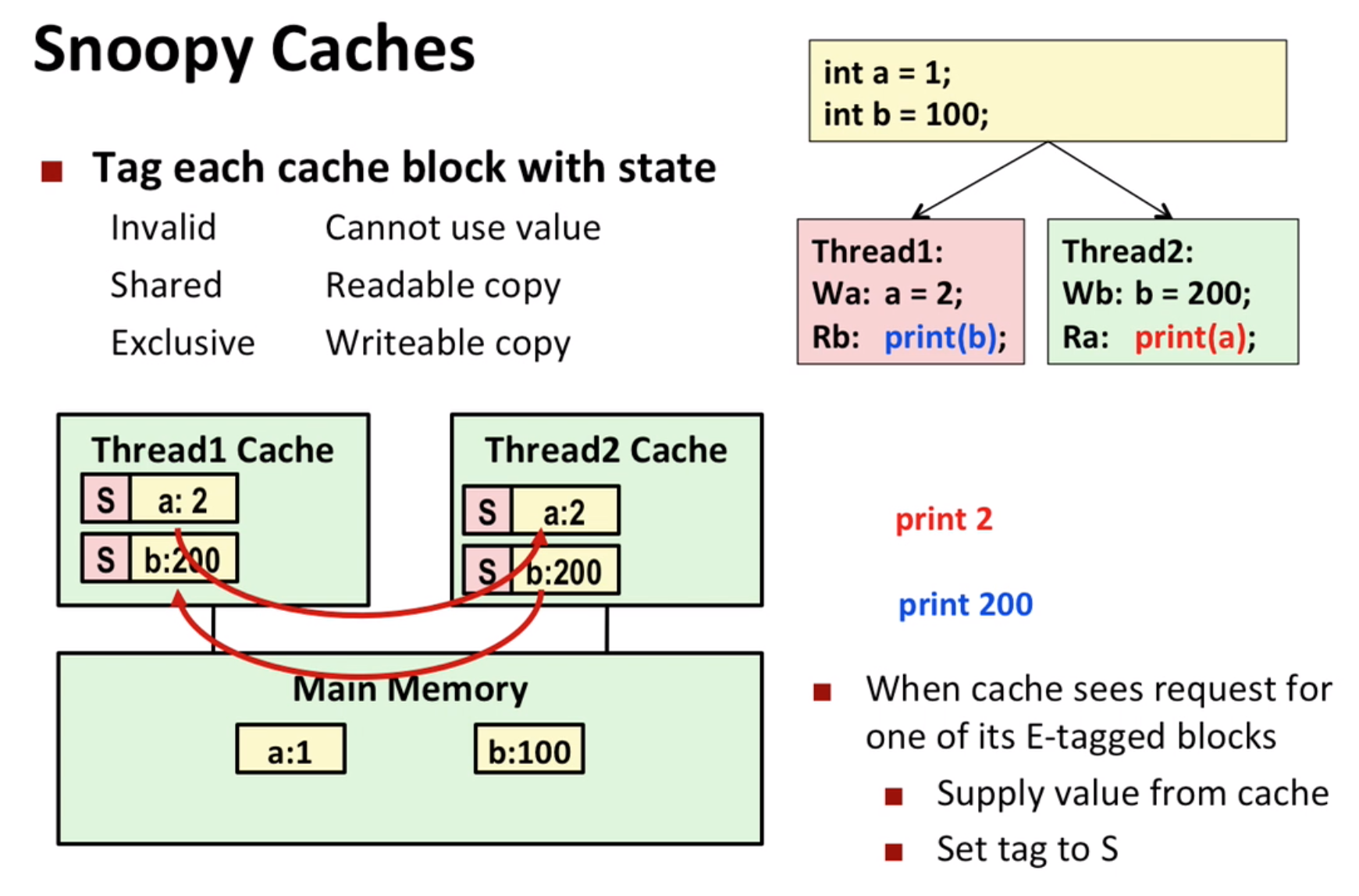
Snoopy Cache:
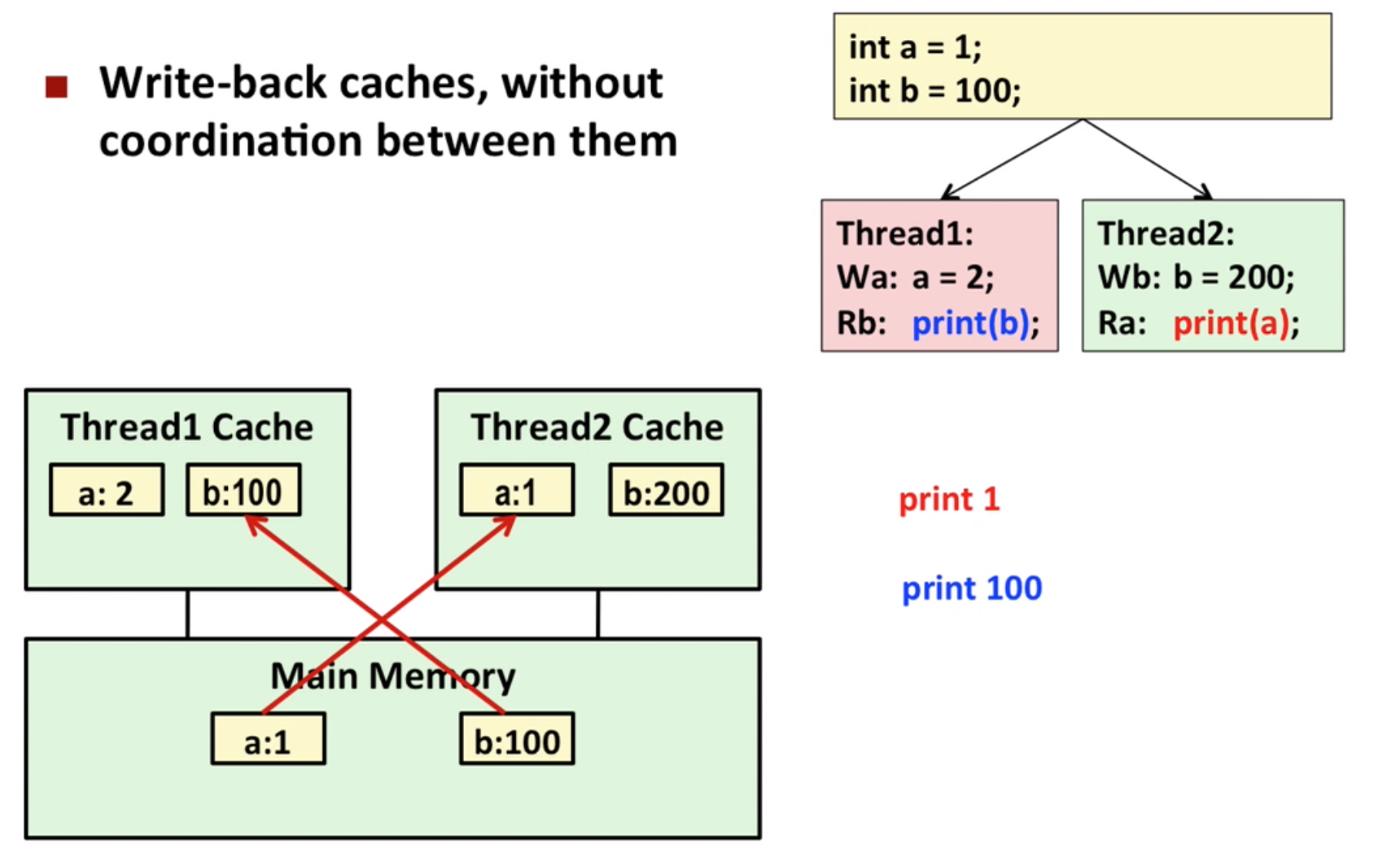
First, the program can not print 1, 100 or 100, 1
However, if the cache is not protected, it can print 1, 100
So, we have some mechanism to protect, like the writer-reader problem:
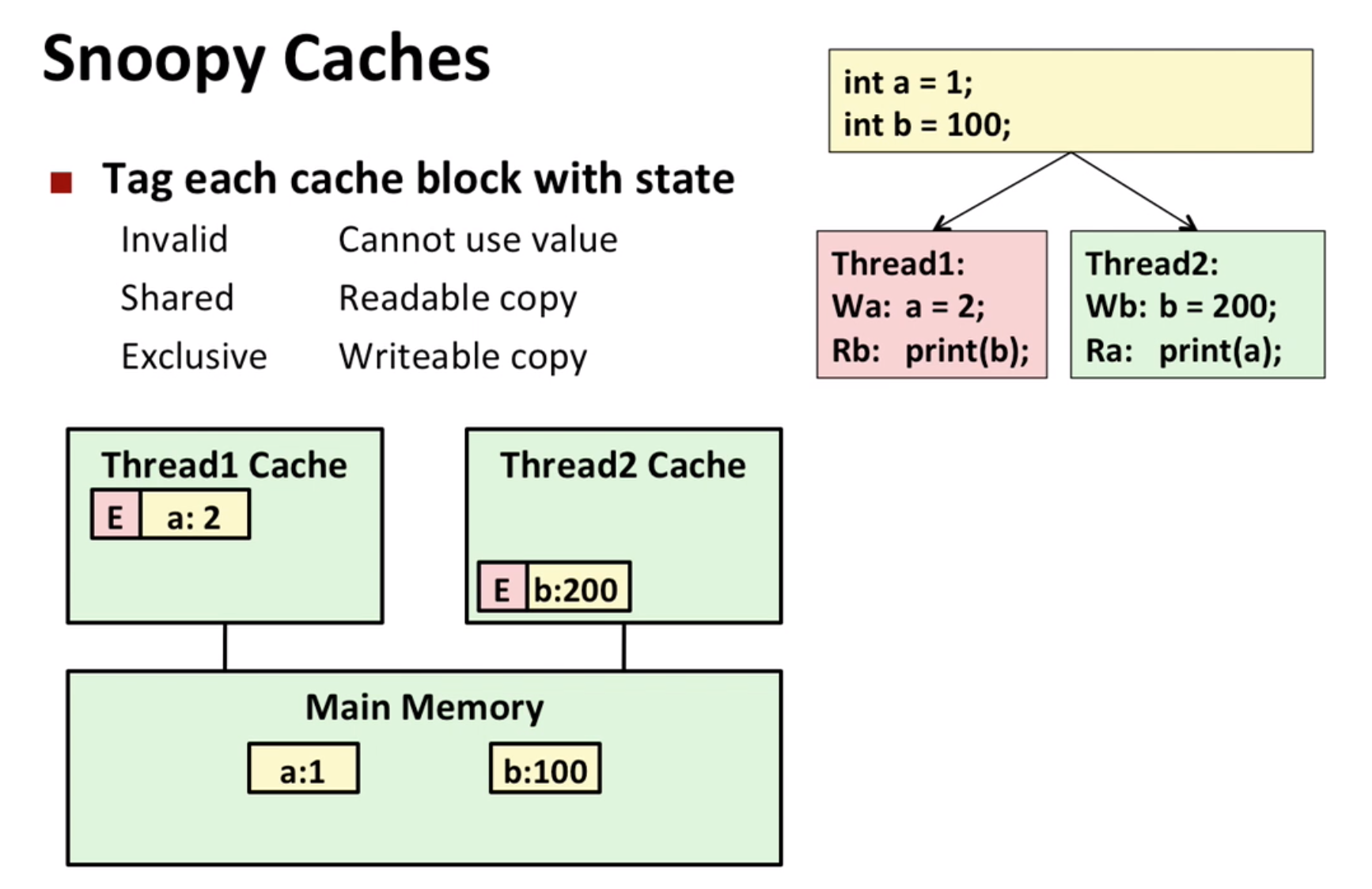
Then when read, instead of reading from main memory, it reads from another cache:
13.6 Sum Example
case1: sum to a global variable using multithreading

This can be very slow because the lock takes a lot of time.
case2: sum by each thread

This is much faster
13.7 Sort Example
Amdahl’s law:
$T_{new}=(1-\alpha)T_{old} + (\alpha T_{old})/k$
Here we optimize the $\alpha$ part by $k$ times. When $k=\infty$, the time still be $(1-\alpha)T_{old}$, which means that we should pay attention to the bottleneck.
Quick Sort Algorithm:
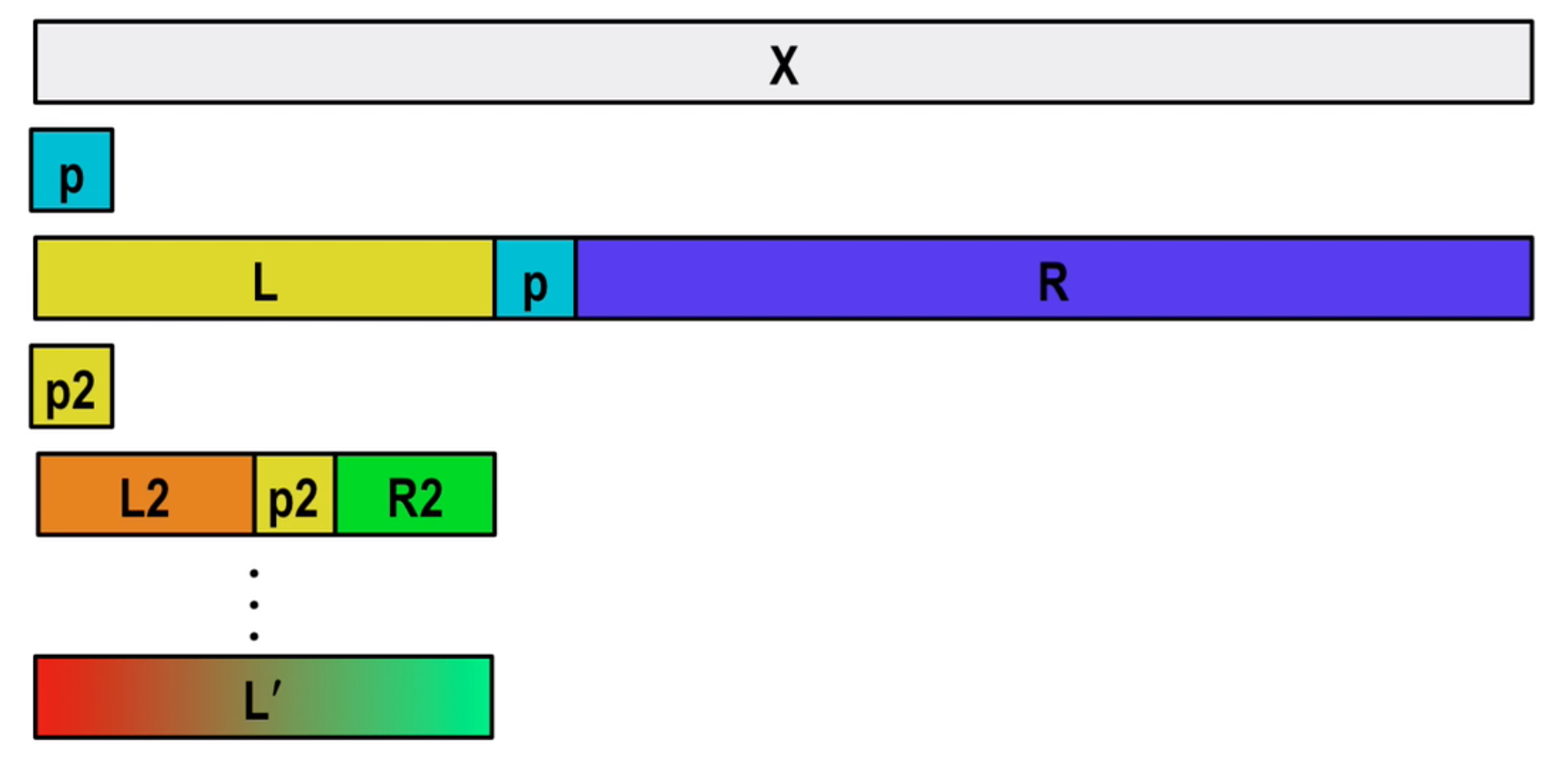
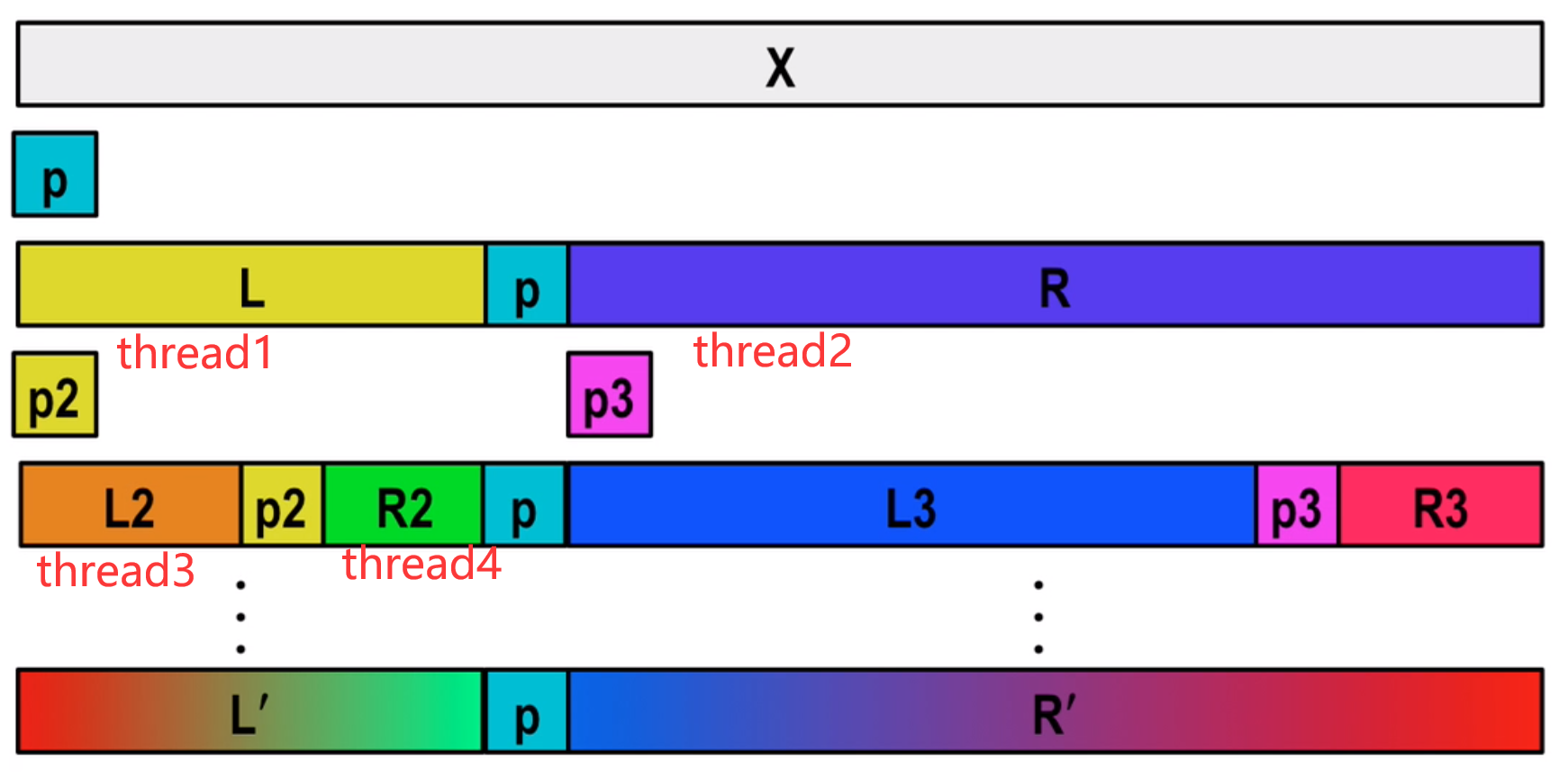
Parallel Algorithm:
Performance:
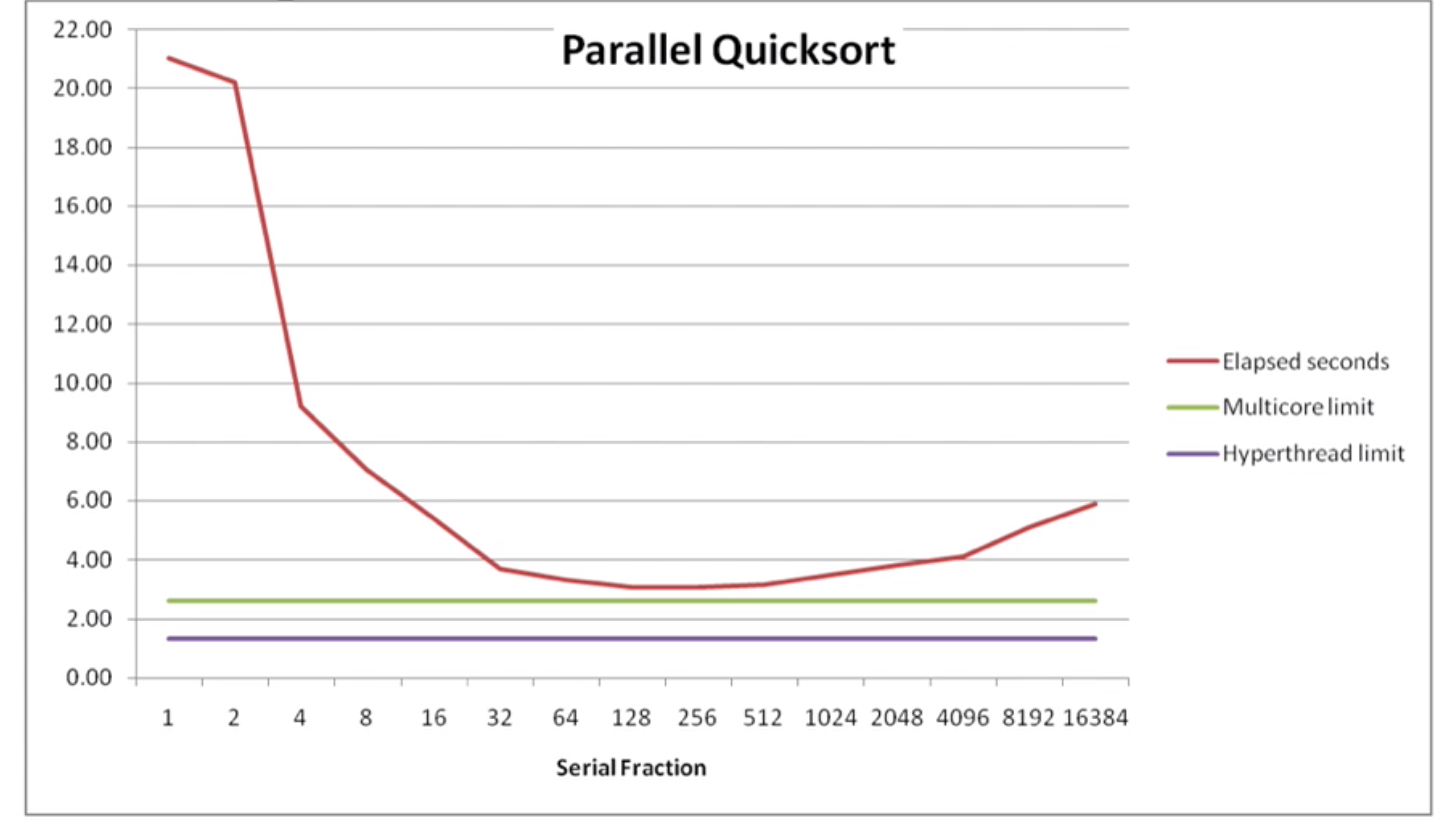
fraction: How many threads will be spawned (this is a hyper-parameter can be set), with an input array of 134 217 728 values. If too much, thread overhead can be the main time-killer.