CSAPP Class Notes(3)
8. Exceptional Control Flow
8.1 Control Flow
program state
- jumps and branches
- calls and return
system state: exceptional control flow(ECF)
- exceptions (low level)
- process context switch: OS software + hardware timer
- signals: OS software
- non-local jumps: C runtime library
8.2 Exceptions
- An exception is a transfer of control to OS kernel in response to some event(eg:
control-c)
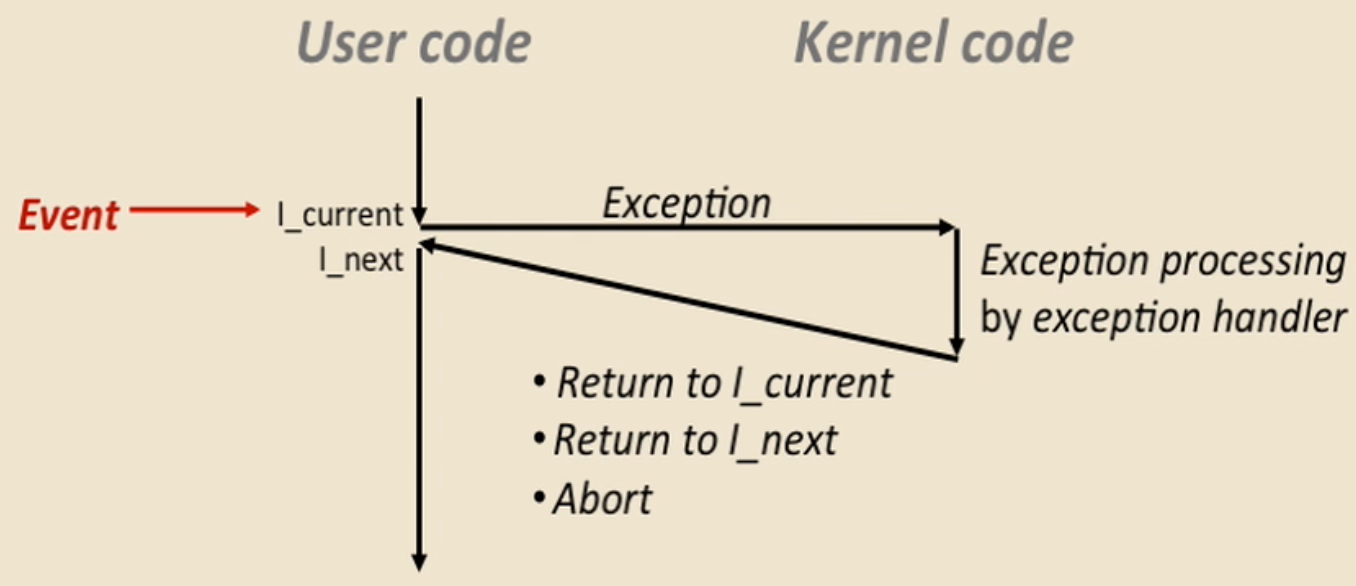
- There is an exception table and corresponding handler
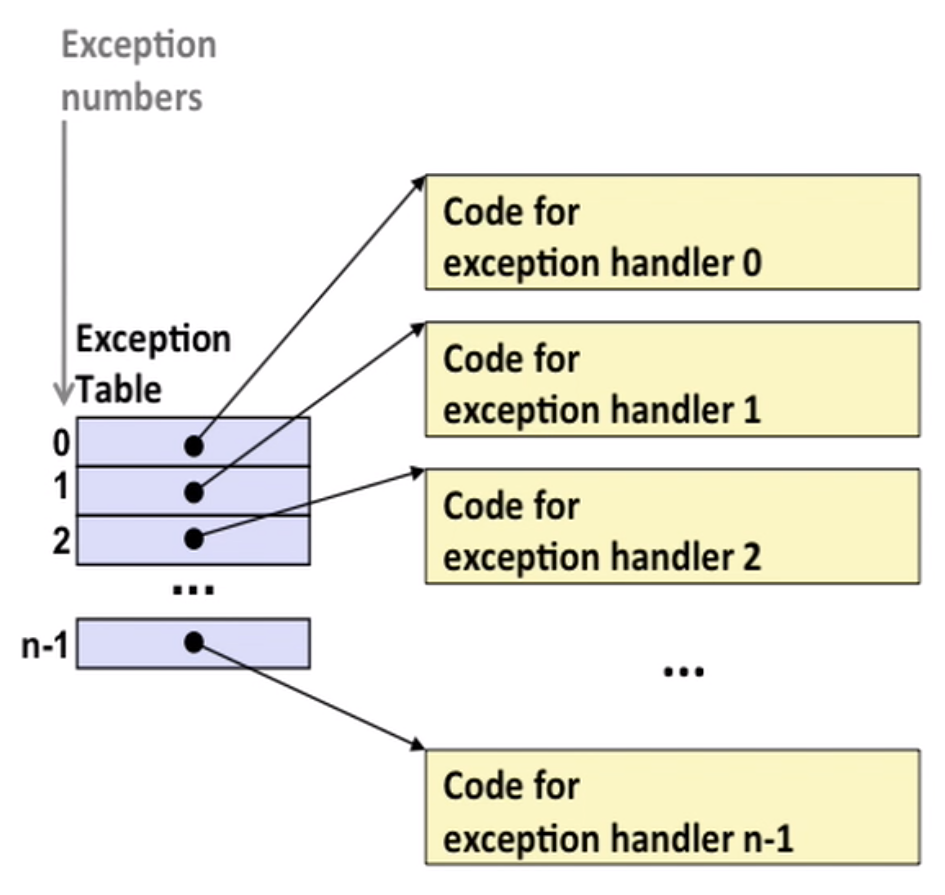
Asynchronous exceptions(Interrupts): eg–Timer interrupt
Synchronous exceptions: caused by an instruction
- trap: intentional, eg – system calls(like read, open, fork, kill etc)
- fault: unintentional, eg – page fault(recoverable), protection fault(unrecoverable)
- abort: unintentional and unrecoverable, eg – illegal instruction
example of fault
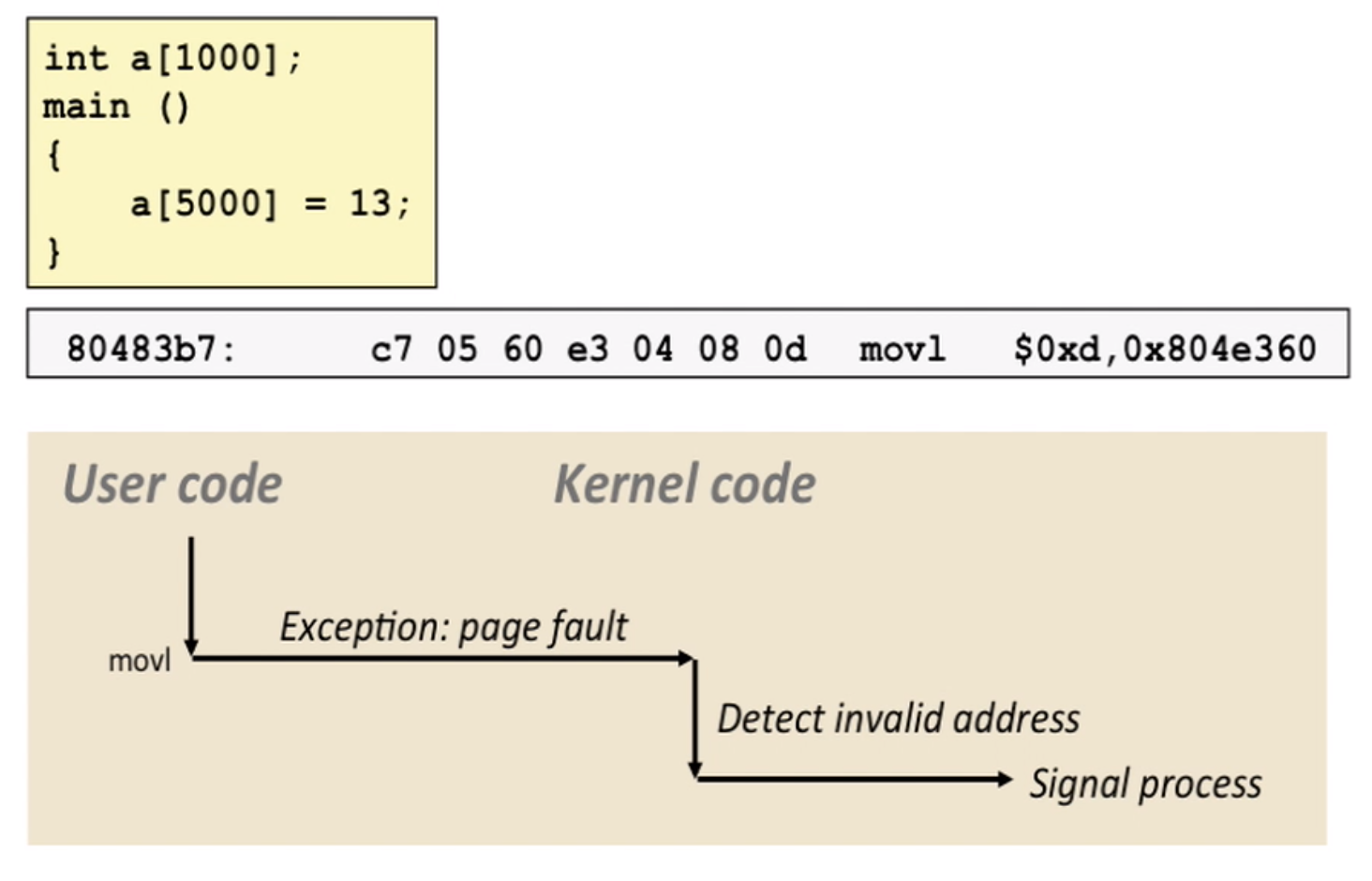
here the OS sends SIGSEGV signal to user process, and process exits with segment fault
8.3 Processes
Introduction
A process is an instance of running program
two key abstractions
- logical control flow: program seems to have exclusive use of CPU, provided by kernel mechanism called
context switching(saved register and switch to another process). Note: physical control flow is the level of instructions. - private address space: program seems to have exclusive use of main memory, provided by kernel mechanism called
virtual memory
- logical control flow: program seems to have exclusive use of CPU, provided by kernel mechanism called
concurrent process(one single core)
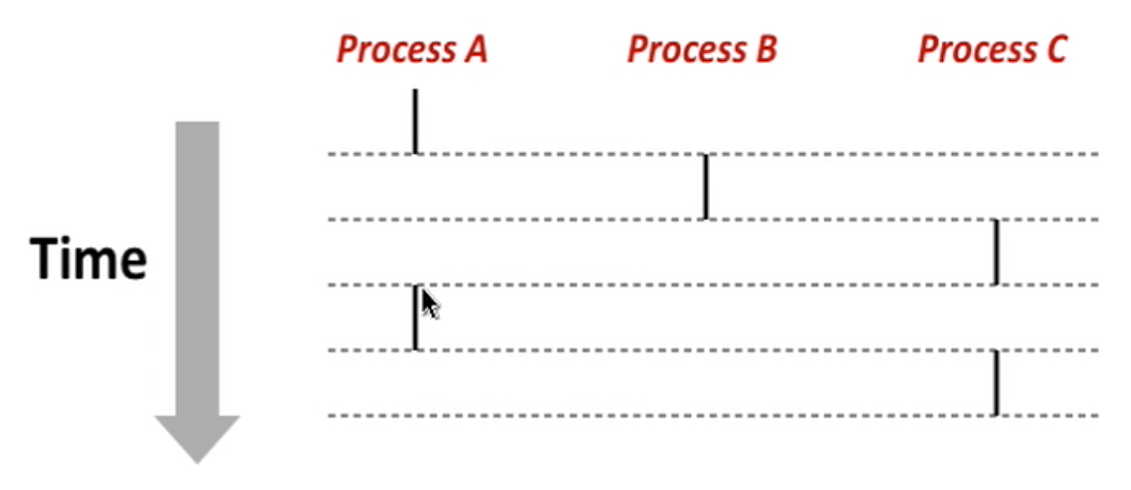
concurrent: flows overlap in time – A & B, A & C
sequential: otherwise – B & C
- context switch
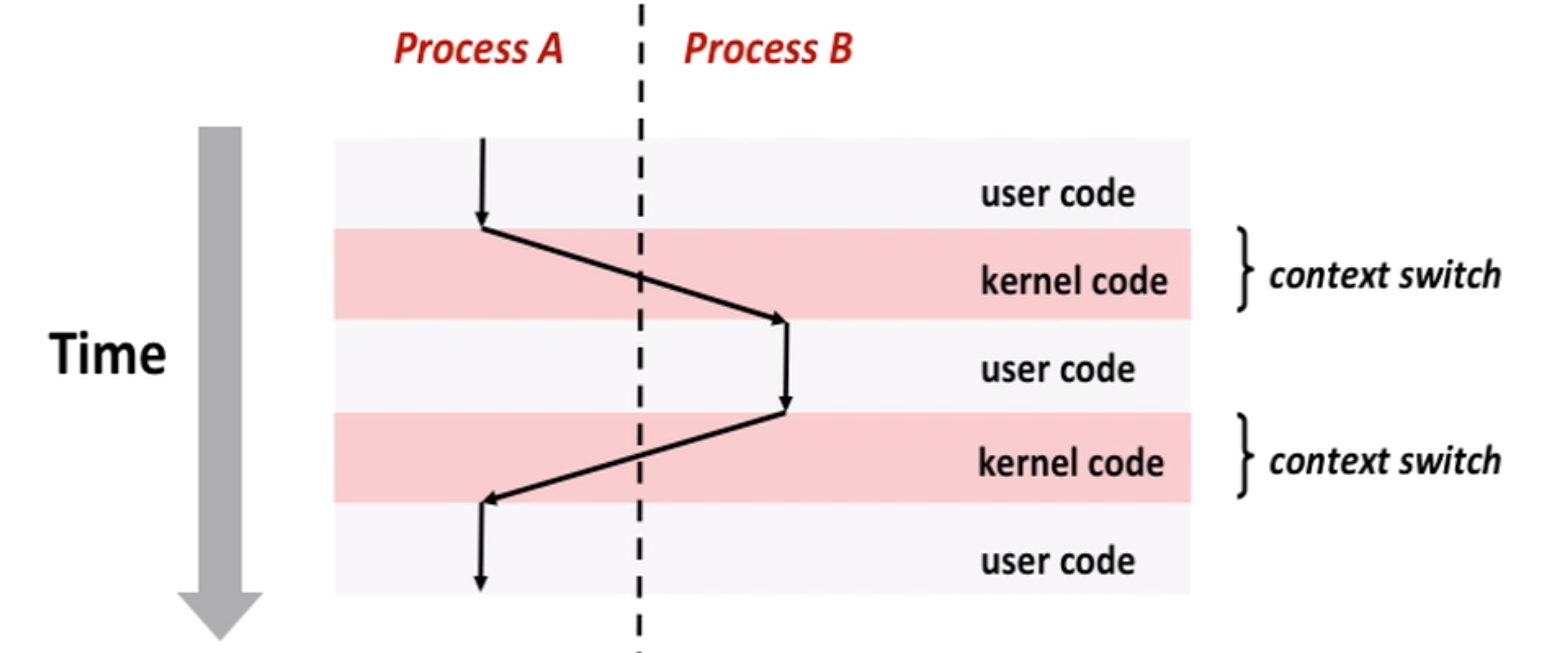
Process Control
pid = fork();to create a child process (Note: always check the pid)Child is almost identical to parent:
- Child get an identical (but separate) copy of parent’s virtual address space
- identical copies of parent’s open file descriptors
- different PID
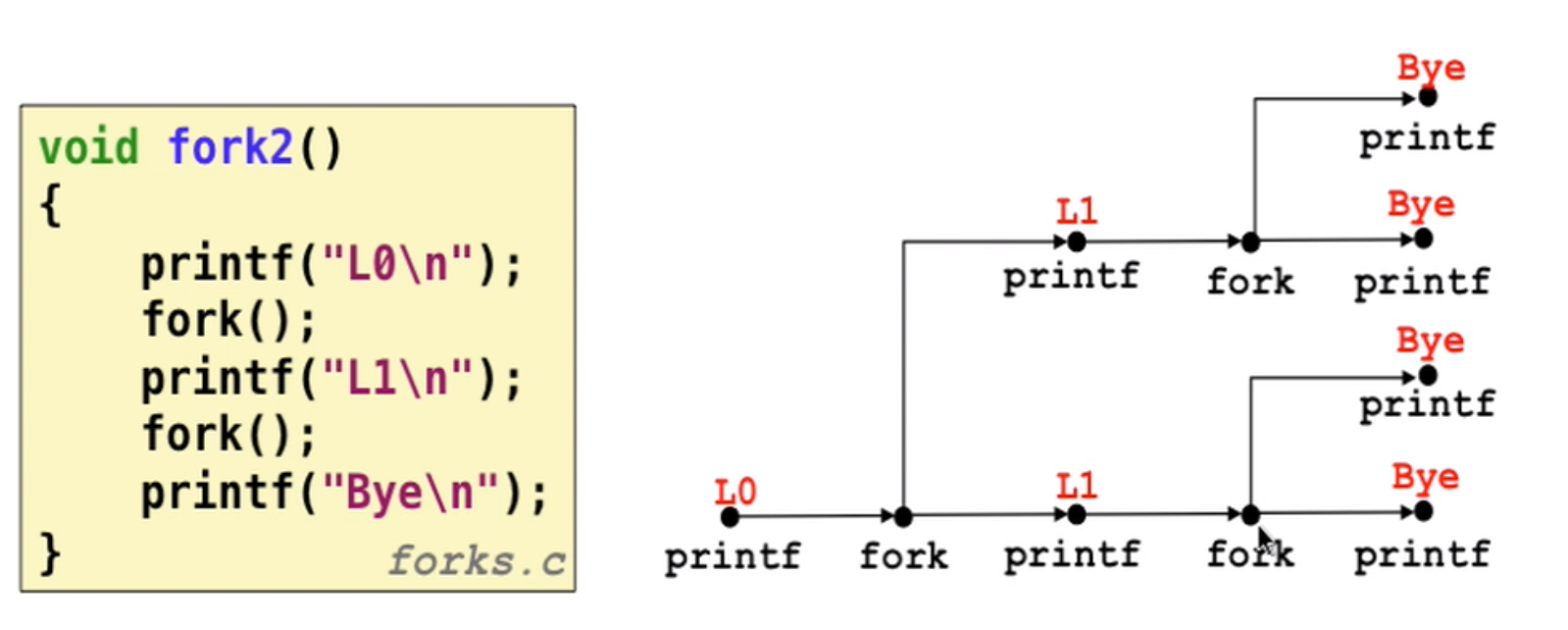
fork example
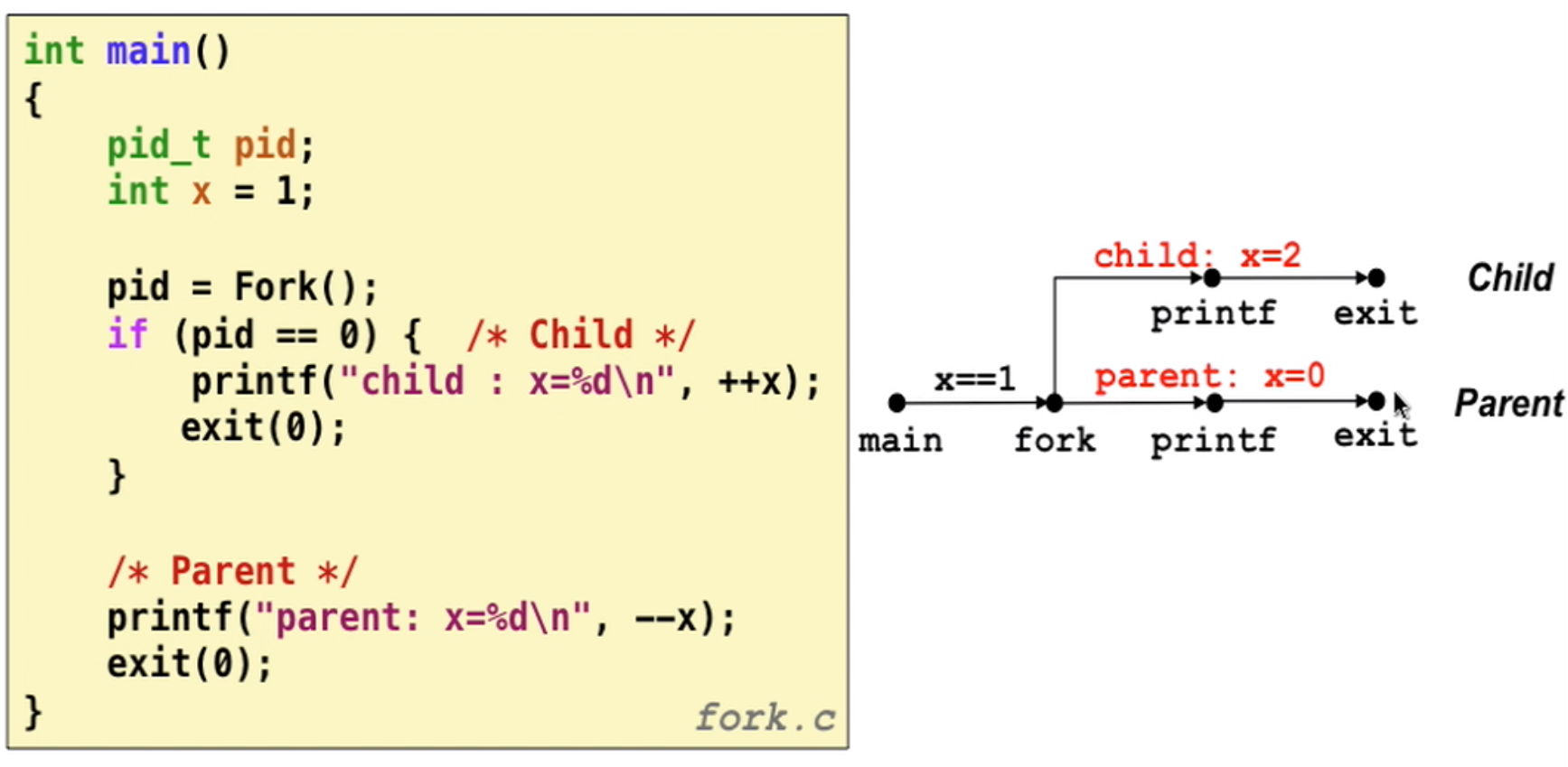
Note that fork() calls once, but return twice (one in parent, one in child)
reap child process
- When process terminates, it still consumes system resources (
zombie process) - parent terminate child (
wait/waitpid) and kernel delete zombie process - if parent does nothing, init process(pid=1) will reap the child.
- When process terminates, it still consumes system resources (
execve: loading and running programs- different from
process, it has different codes to run
- different from
8.4 Shells
linux process hierarchy
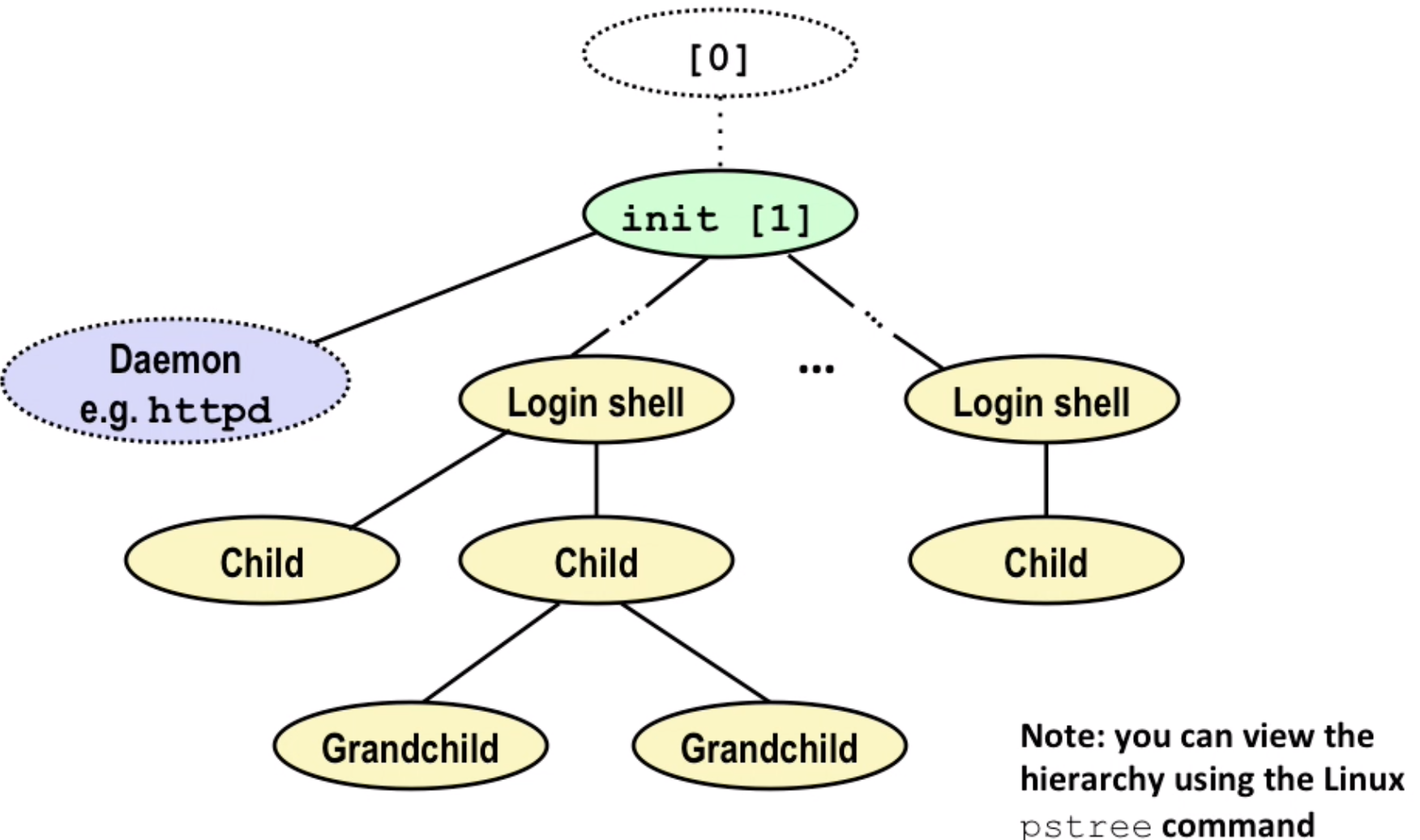
login shell: user interface, eg: ls
A shell is an application program (a process) that runs user programs
Note that waitpid is used when using background job
If no signals, the background job will become zombies
8.5 Signals
Basic introduction
A signal is a message that notifies a process that an event has occurred
Sending signals: kernel sends/delivers a signal to a destination process
Receiving signals: destination process receives a signal when it is forced by the kernel to react to the delivery of the signal. Some possible ways to react:
- ignore
- terminate(optional
core dump–save the memory state or something to a file for debugging) - catch and do something by signal handler (then to an asynchronous interrupt)
Pending signal: a signal is pending if sent but not yet received. at most one pending signal since signals are not queued
Block signal: a process can block the receipt of certain signals
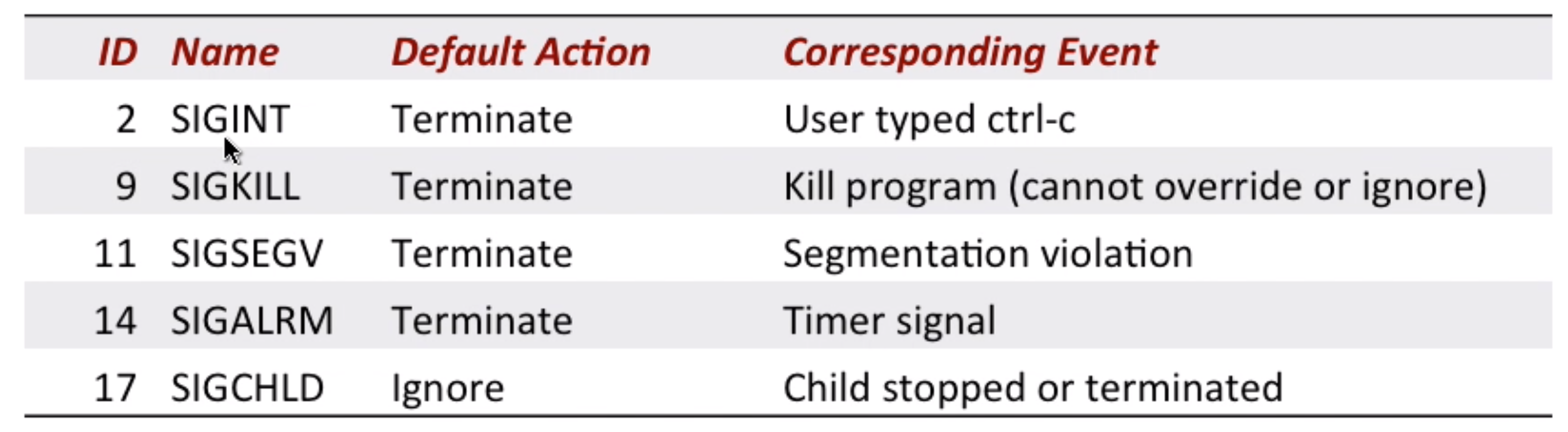
Process group:
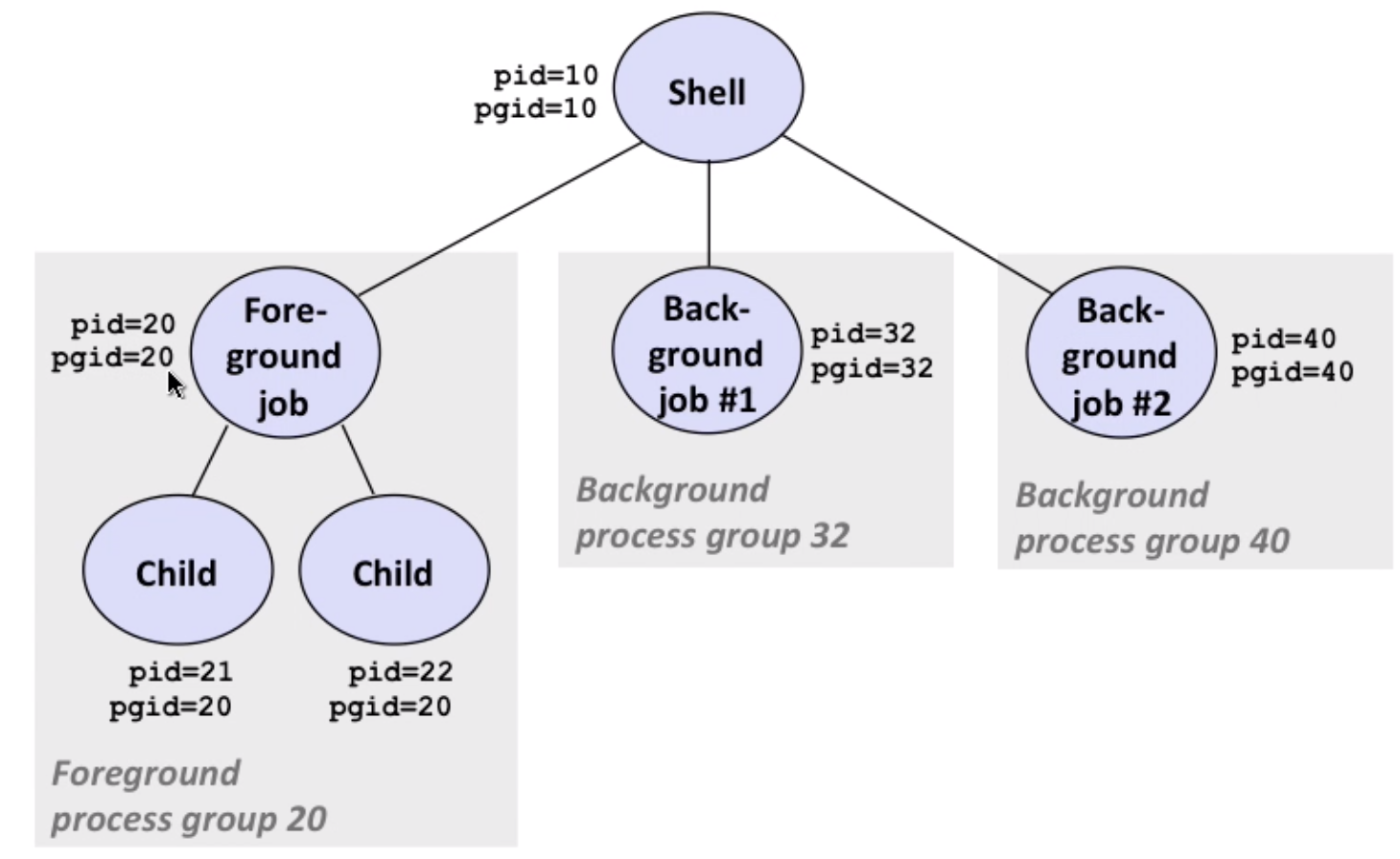
example of process group: bin/kill
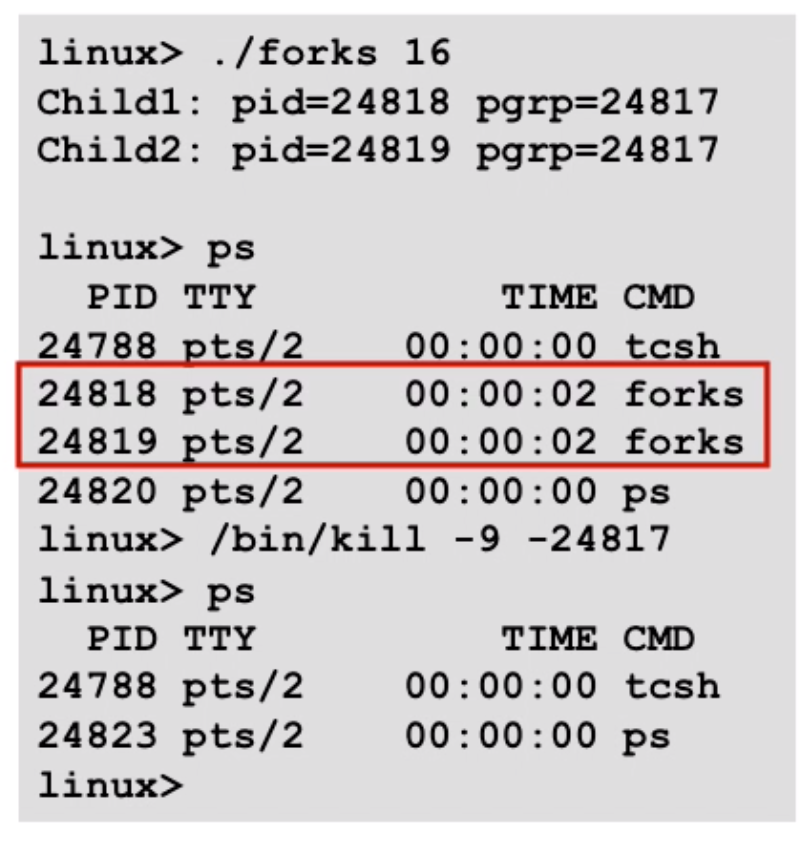
example of ctrl-c(SIGINT) and ctrl-z(suspend a process by sending SIGTSTP, putting the process into background and stop running):
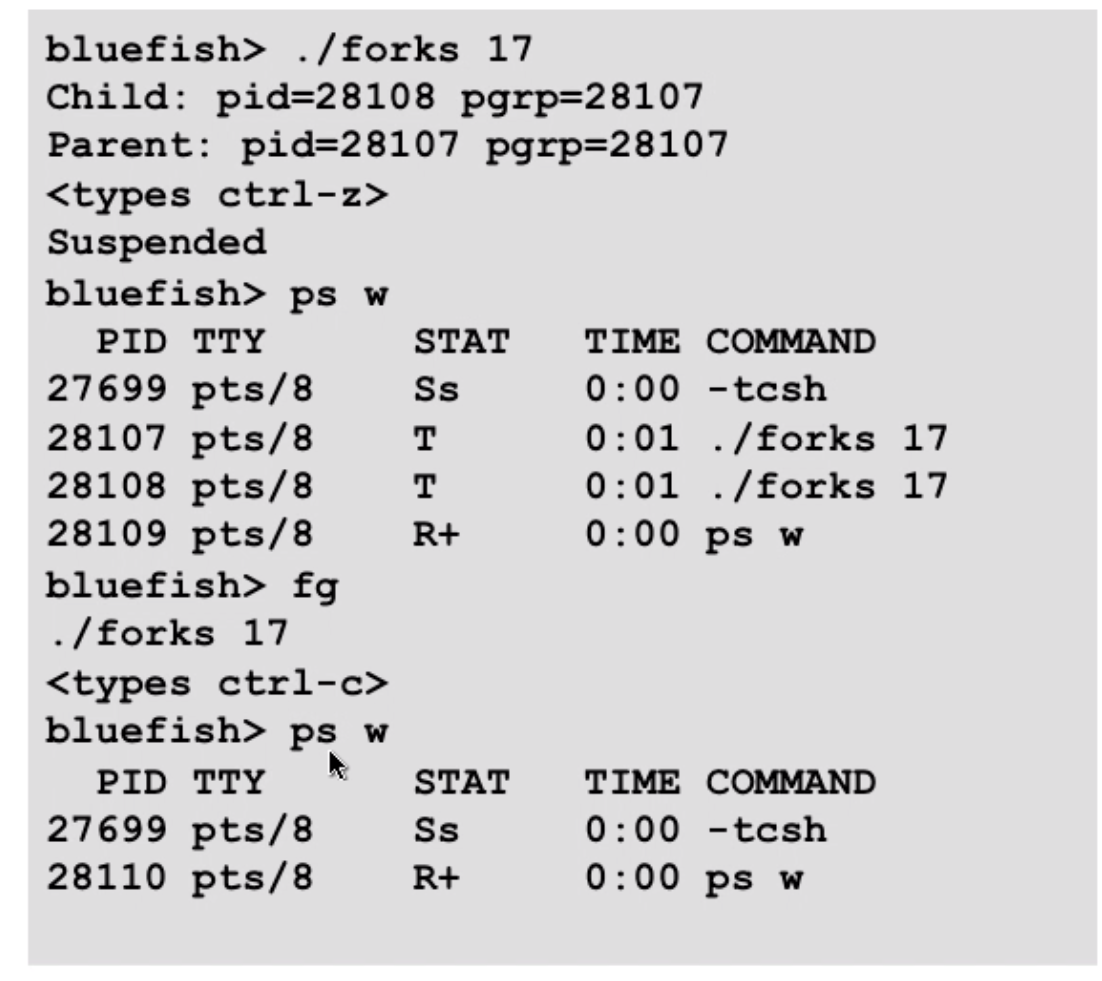
STAT:
- first letter:
S: sleeping,T: stopped,R: running,Z: zombie - second letter:
s: session leader,+: foreground process group
signal handling example:
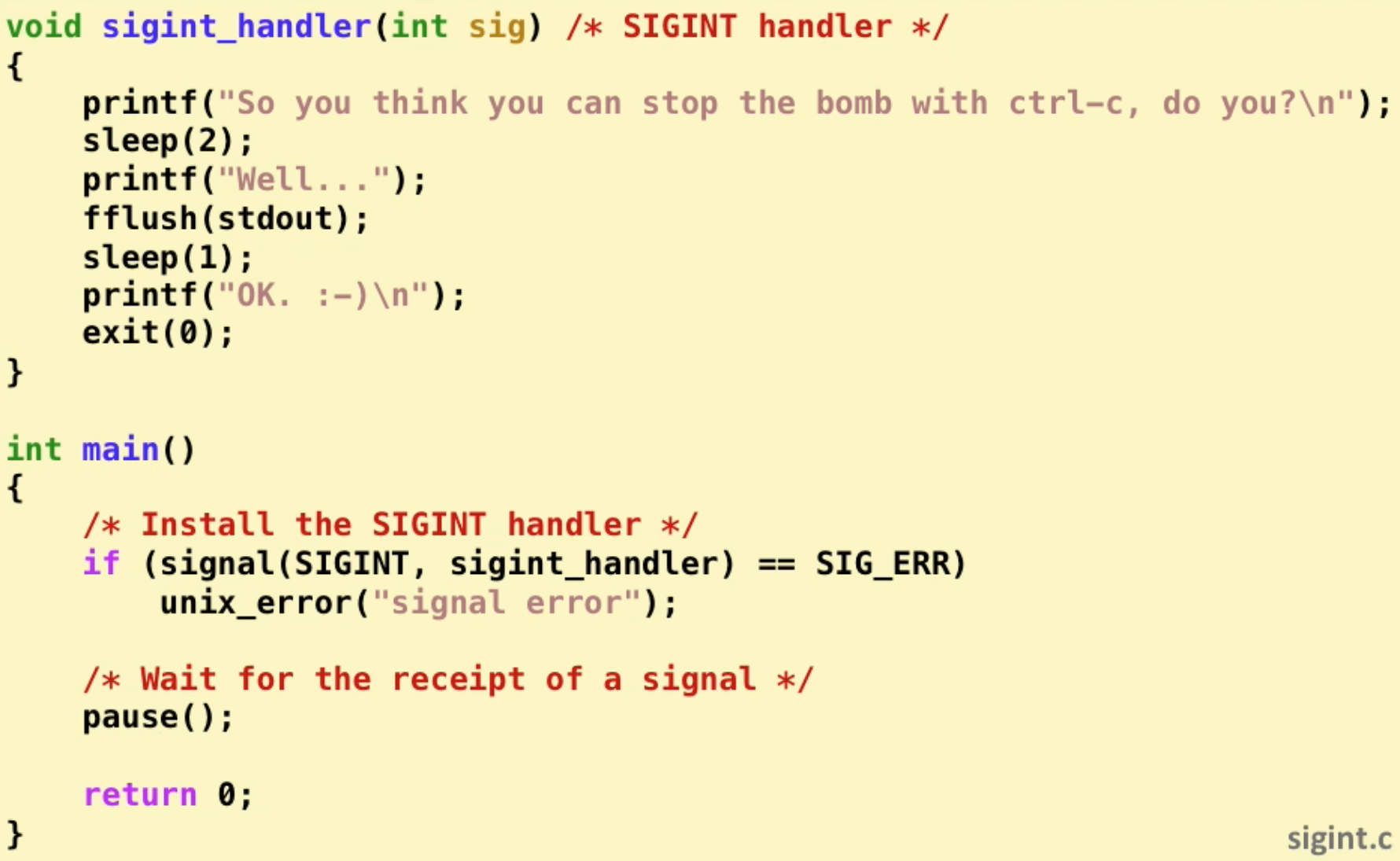
signal handler as concurrent flow:
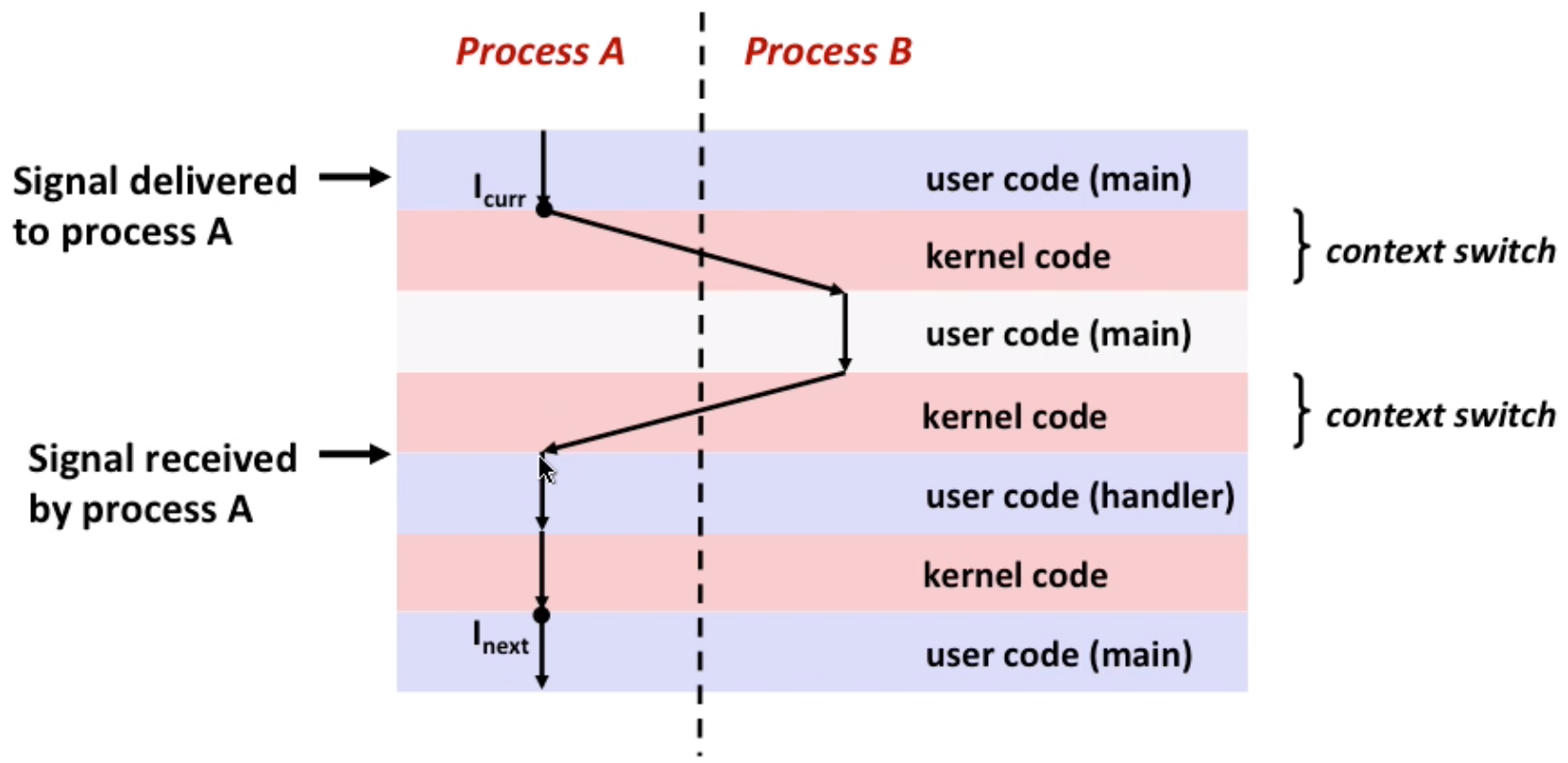
and handler can be interrupted by other handlers(nested handlers):
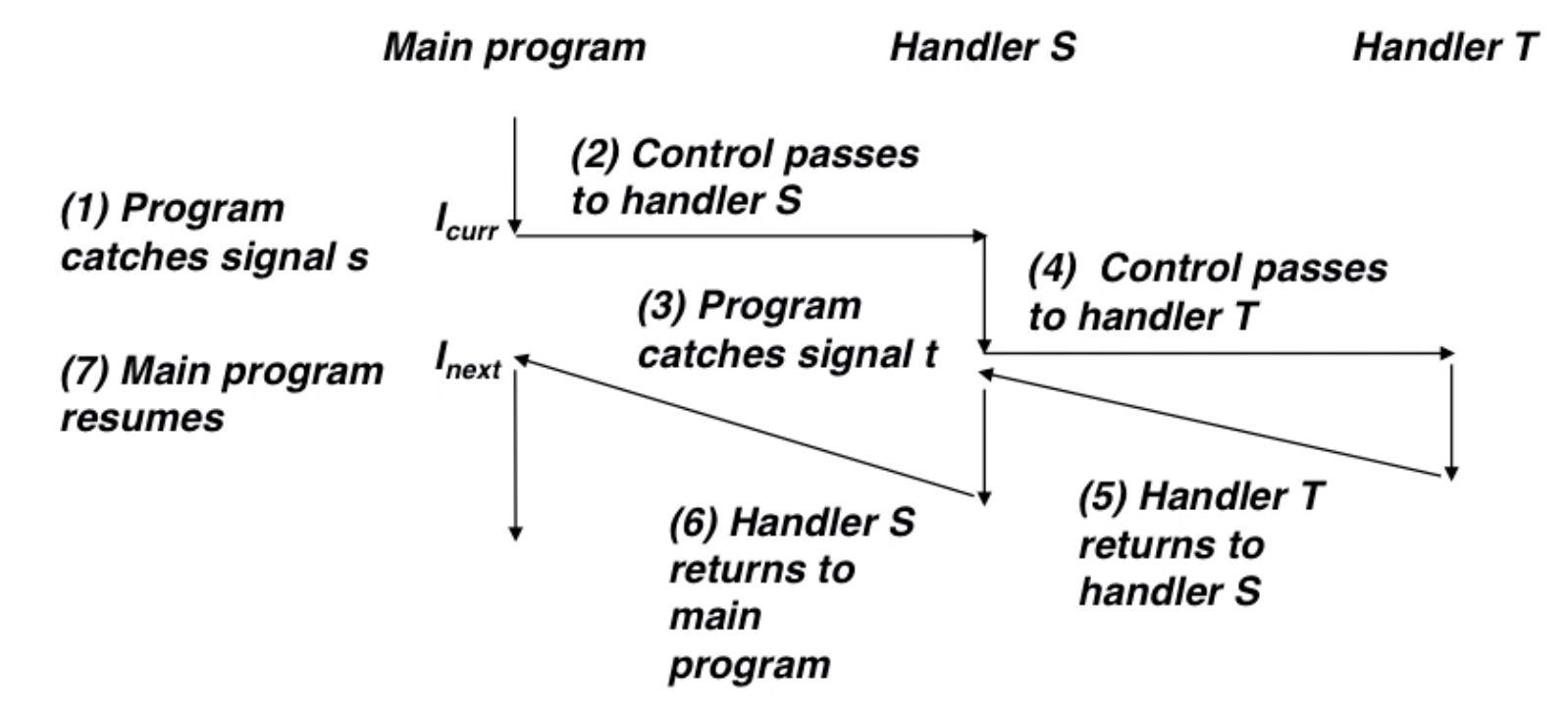
The ways to temporarily block signal: Sigprocmask
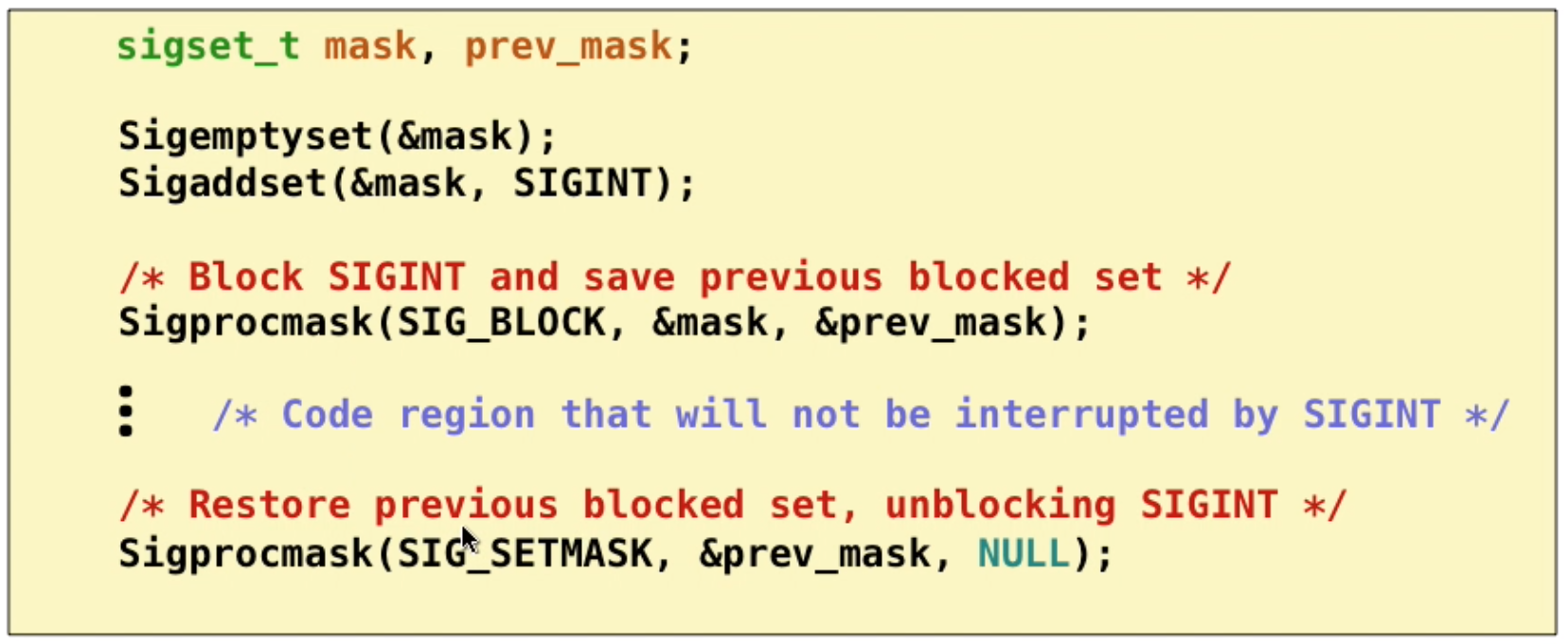
Write safe handlers
async-signal-safe: reentrant(eg: all variables stored on stack) or non-interruptible by signals.
- keep your handlers as simple as possible (eg: set flag and return)
- call only async-signal-safe functions in your handler(
printf,malloc,exitare not safe!) - save and restore
errnoon entry and exit (so other handlers don’t overwrite) - protect access to shared data structure(so avoid concurrent issue)
- declare global variables as volatile(to prevent compiler from storing them in register, only in memory)
- declare global flag as
volatile sig_atomic_t(sig_atomic_tis a safe type)
why is printf unsafe? It has a lock, if one thread requires a lock, and before release it, it’s interrupted and the handler wants to printf again — dead lock.
you can’t use signals to count events, since pending signals are not queued (at most one pending signal of any type)
pause() can be dangerous: parent sets pid=0, if pid is 0 and the signal comes between while and pause(), the pause() may wait forever.

so here we can use Sigsuspend
Nonlocal jumps
jump(return) from one function directly to another function without calling it by using setjmp, longjmp.
9. System-Level I/O
9.1 Unix I/O
regular file
- text files: ASCII or Unicode
- Binary files: .jpg image or object files… everything else
directories
- consists of an array of links
- tree hierarchy
Note: Do not call system call (
read,write) too many times because of the cost of context switch unless you have to. Try read more bytes at one time
9.2 RIO(robust I/O) package
A robust wrapper for basic I/O.
9.3 Metadata, sharing and redirection
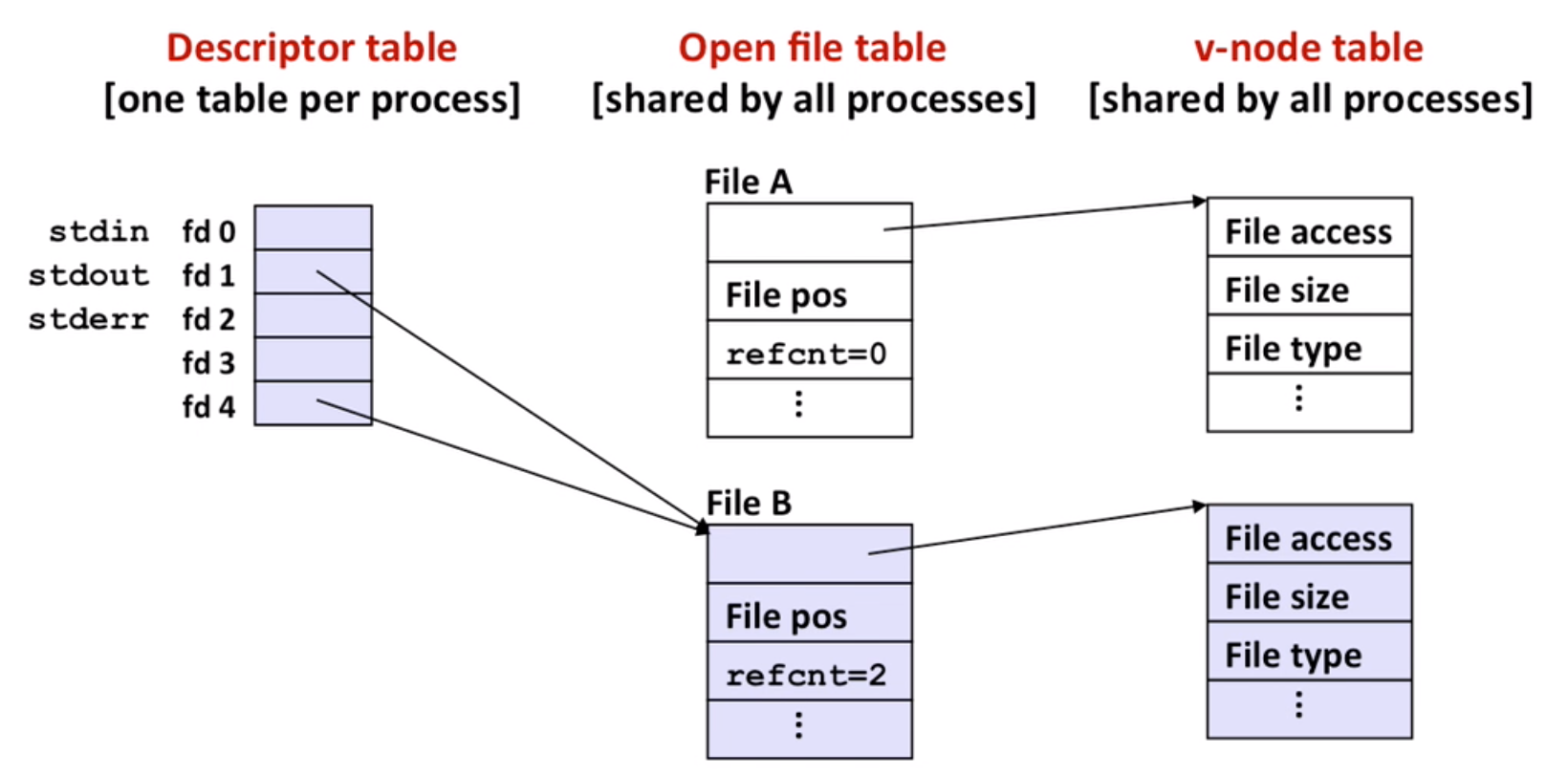
Metadata: maintained by kernel, accessed by stat and fstat
How unix kernel represents open files:
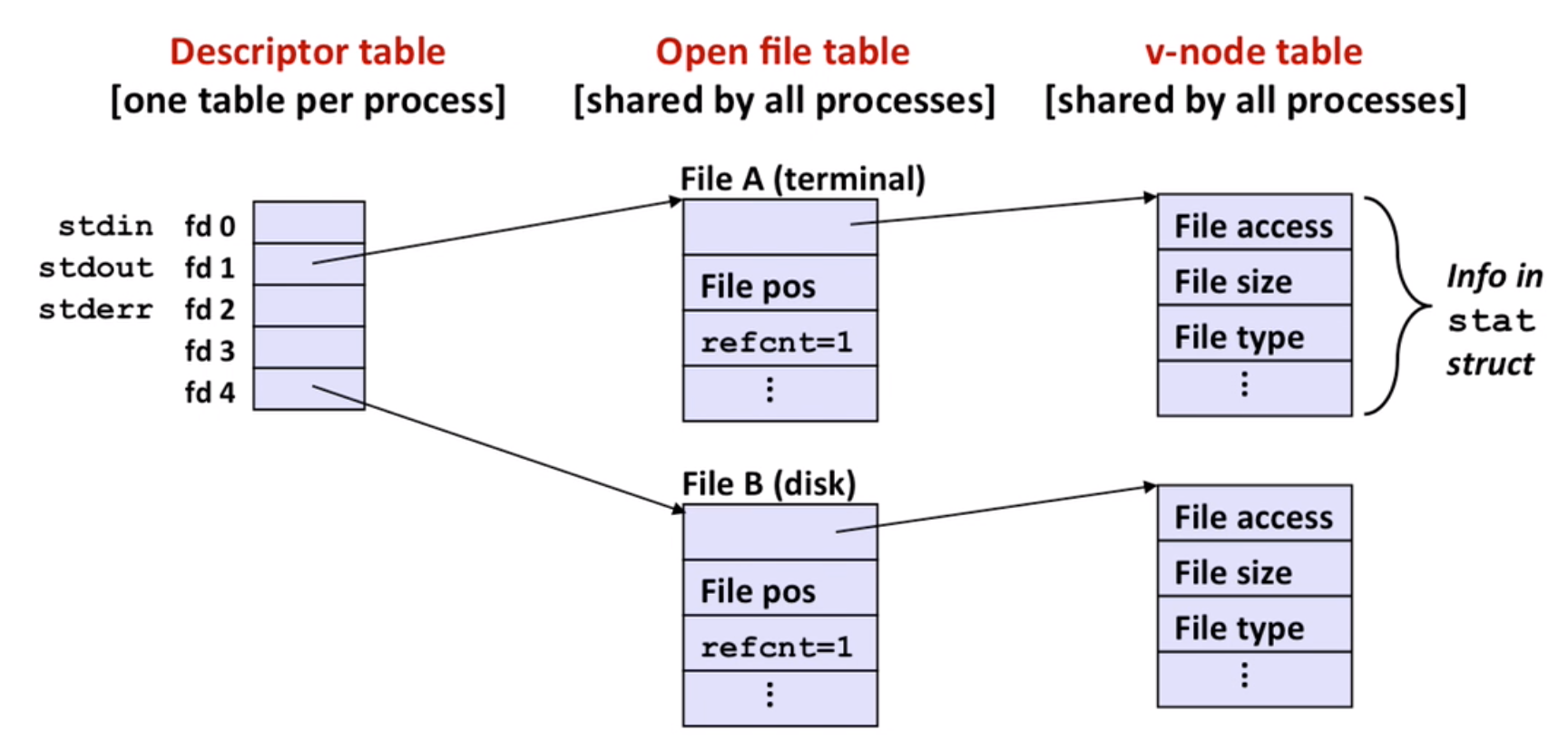
So file sharing makes sense:
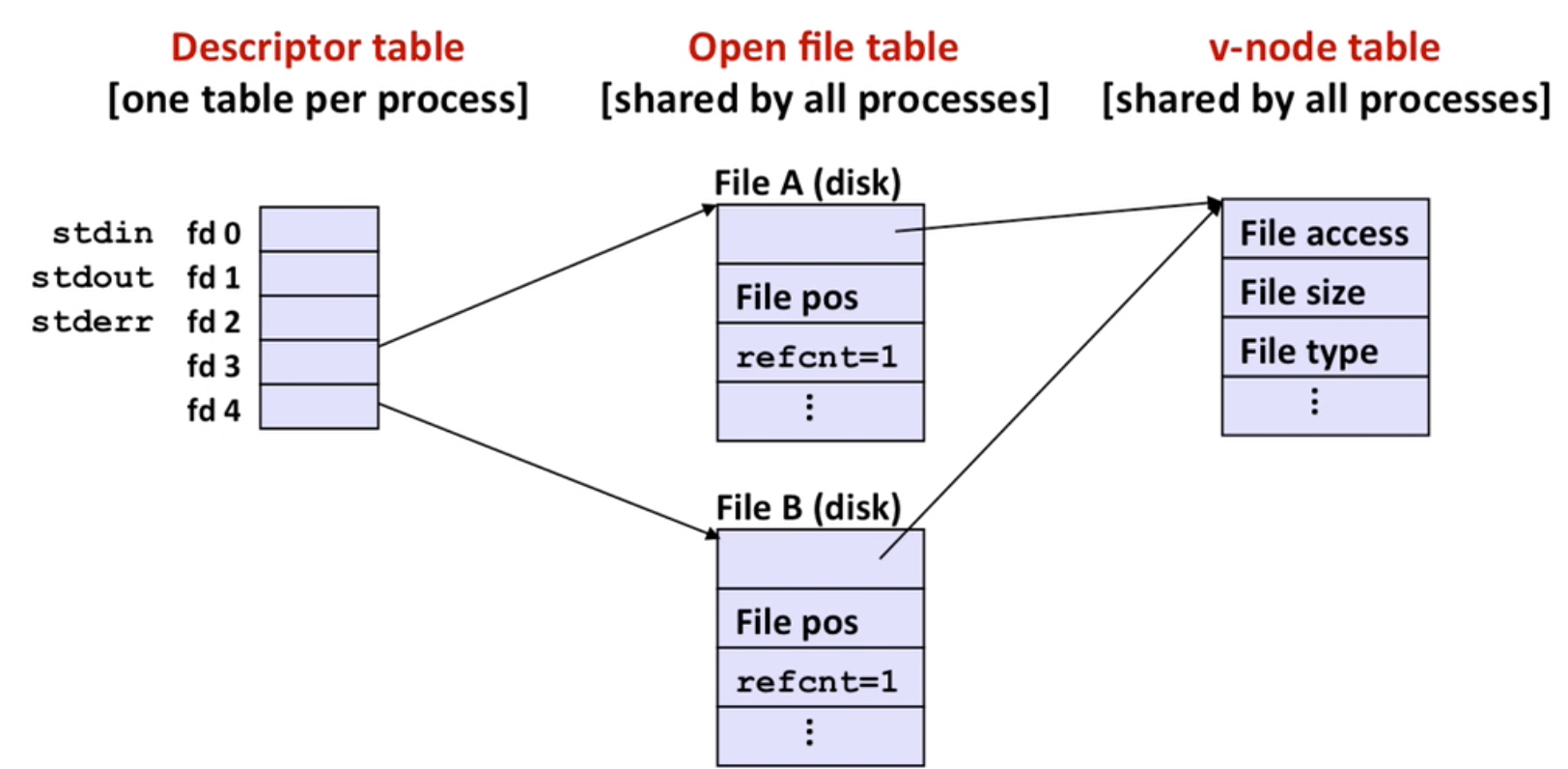
Note: fork, a child inherits its parent’s open files
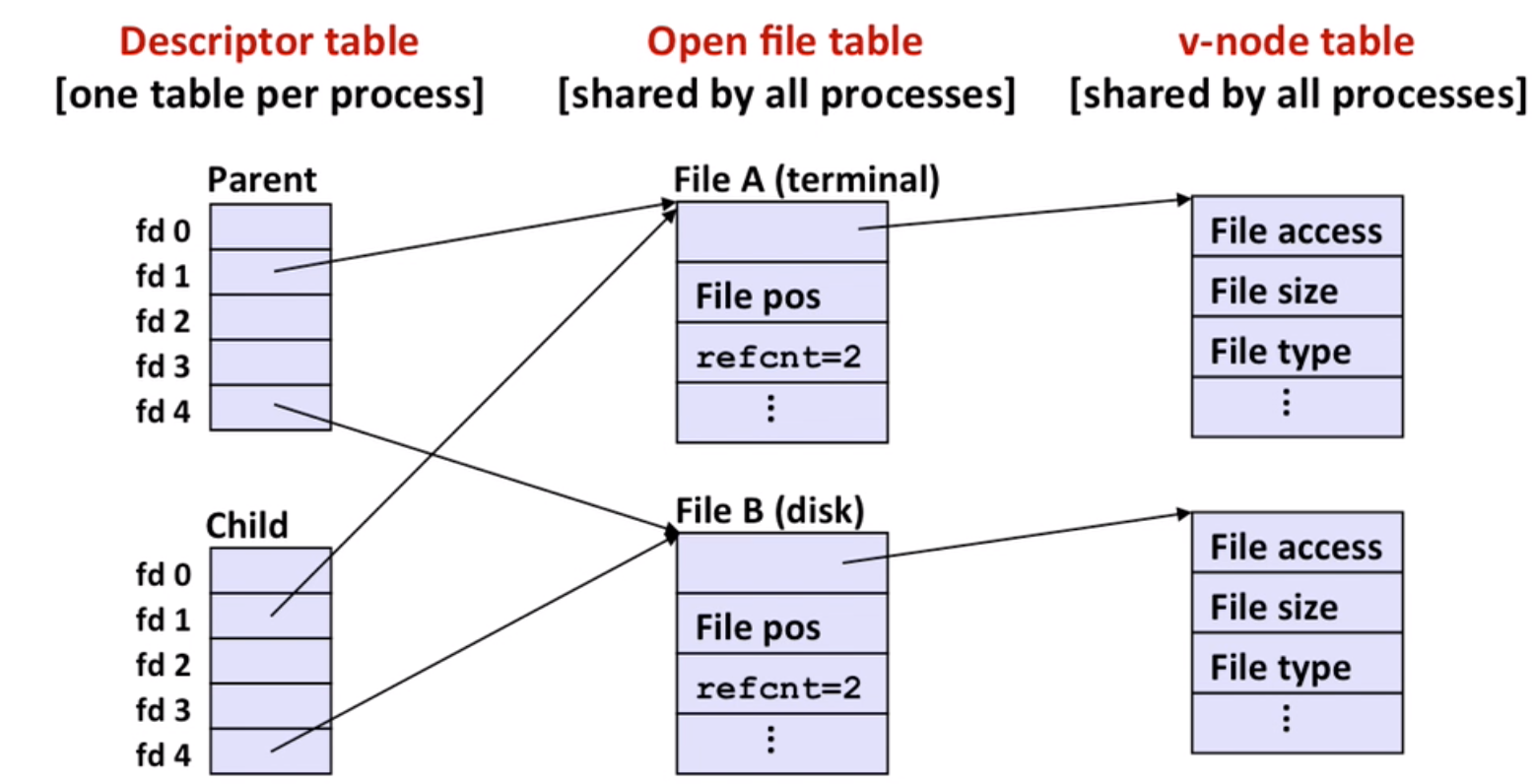
Remember to call close() both in parent and child codes.
I/O redirection by using dup2:
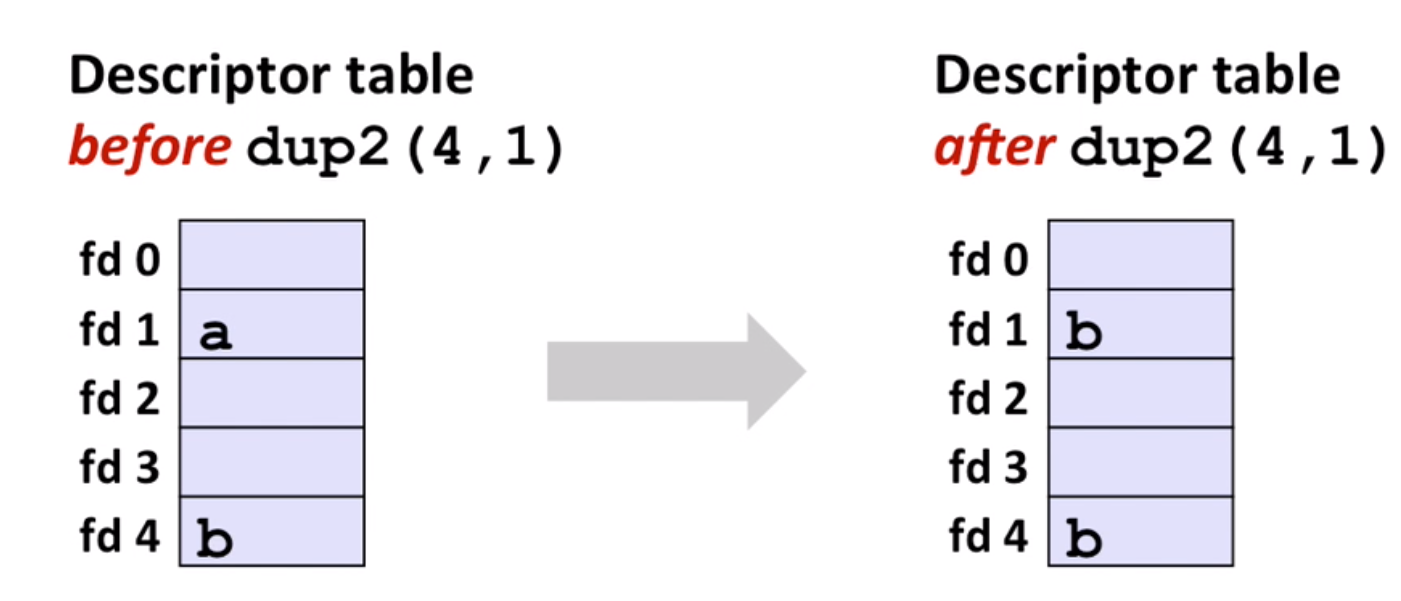
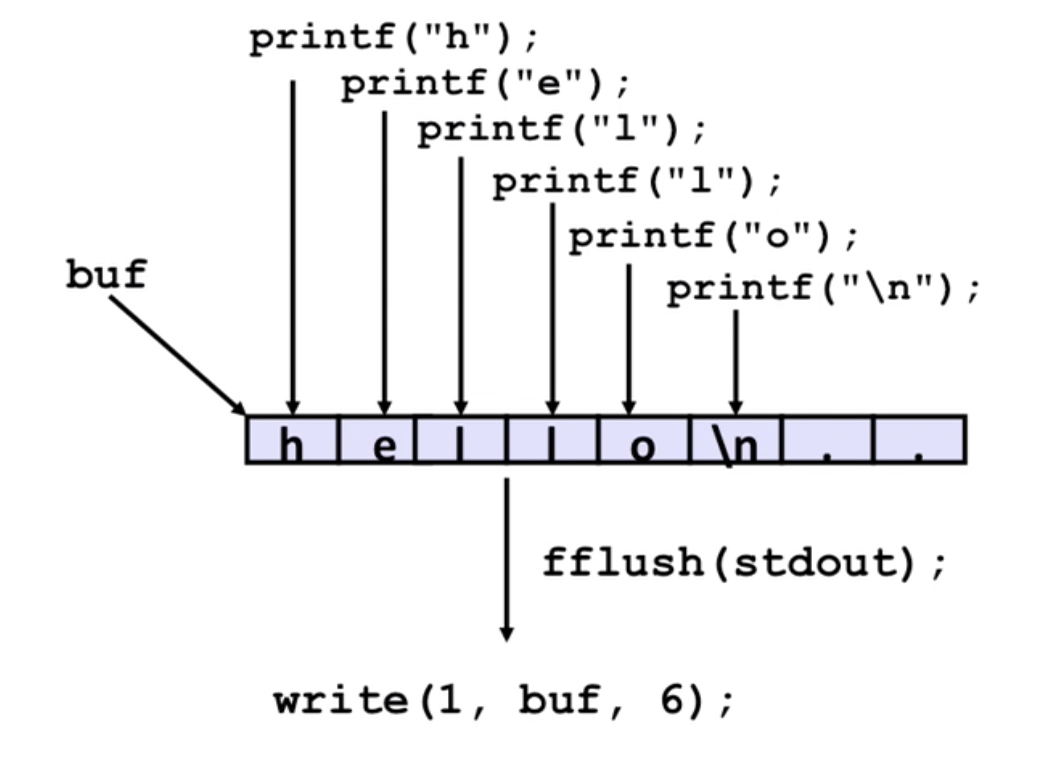
9.4 Standard I/O
fopen, fead, fflush etc.
Note: there is a buffer in standard IO to reduce multiple system calls
9.5 Closing remarks
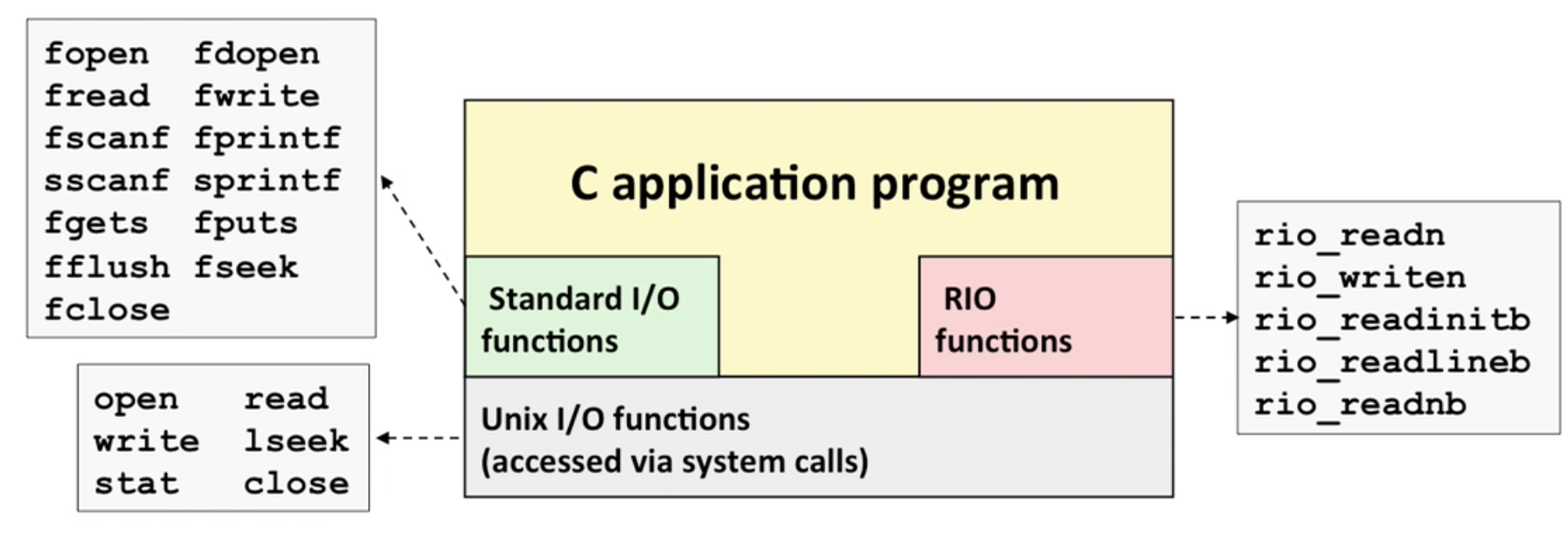 \
\
- standard IO is not suitable for network sockets(not designed for it)
- standard IO functions are not async-signal-safe (unix IO functions are), and not appropriate for signal handlers
- standard IO can help you decrease the number of system calls and handle short counts(
a = read() < 0)
10. Virtual Memory
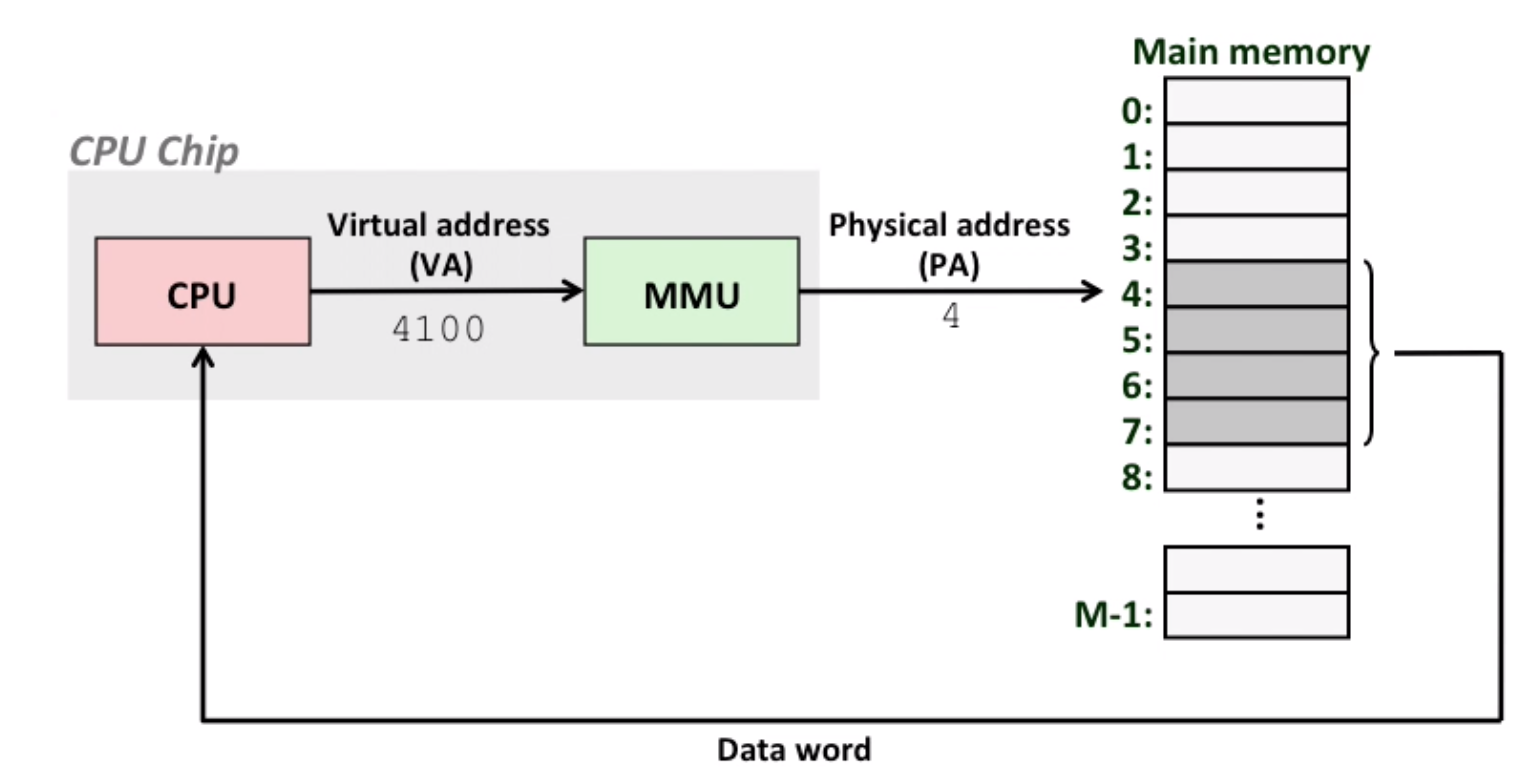
MMU: Memory Management Unit, does address translation
VM can help:
- use main memory efficiently(cache)
- simplify memory management
- isolate address space(to protect privileged kernel and code)
10.1 VM as a tool for caching
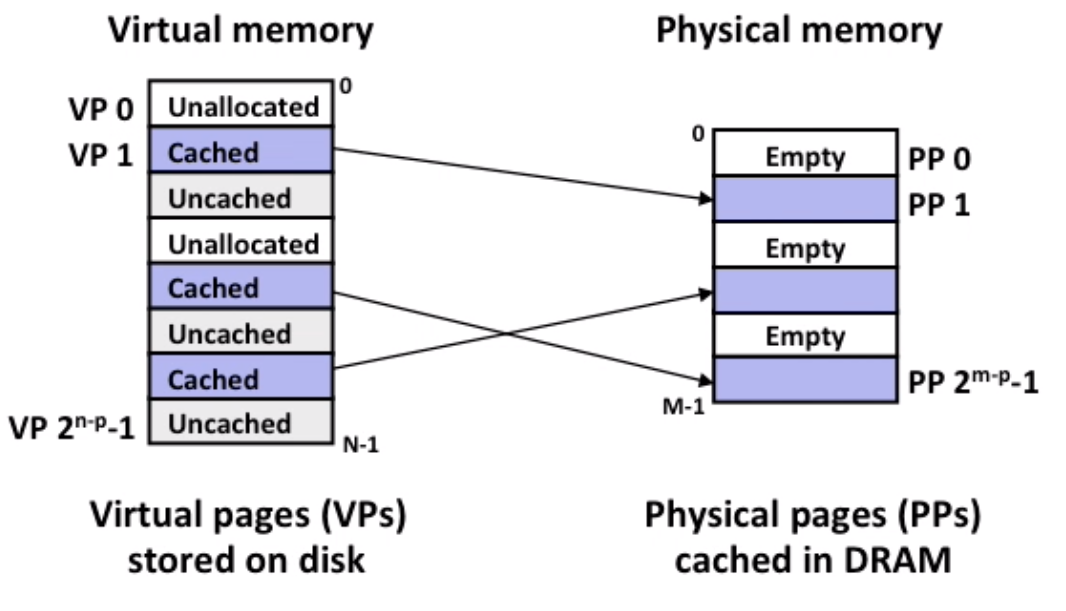
Virtual memory is an array of N contiguous bytes, the content of the array on disk are cached in physical memory(DRAM Cache)
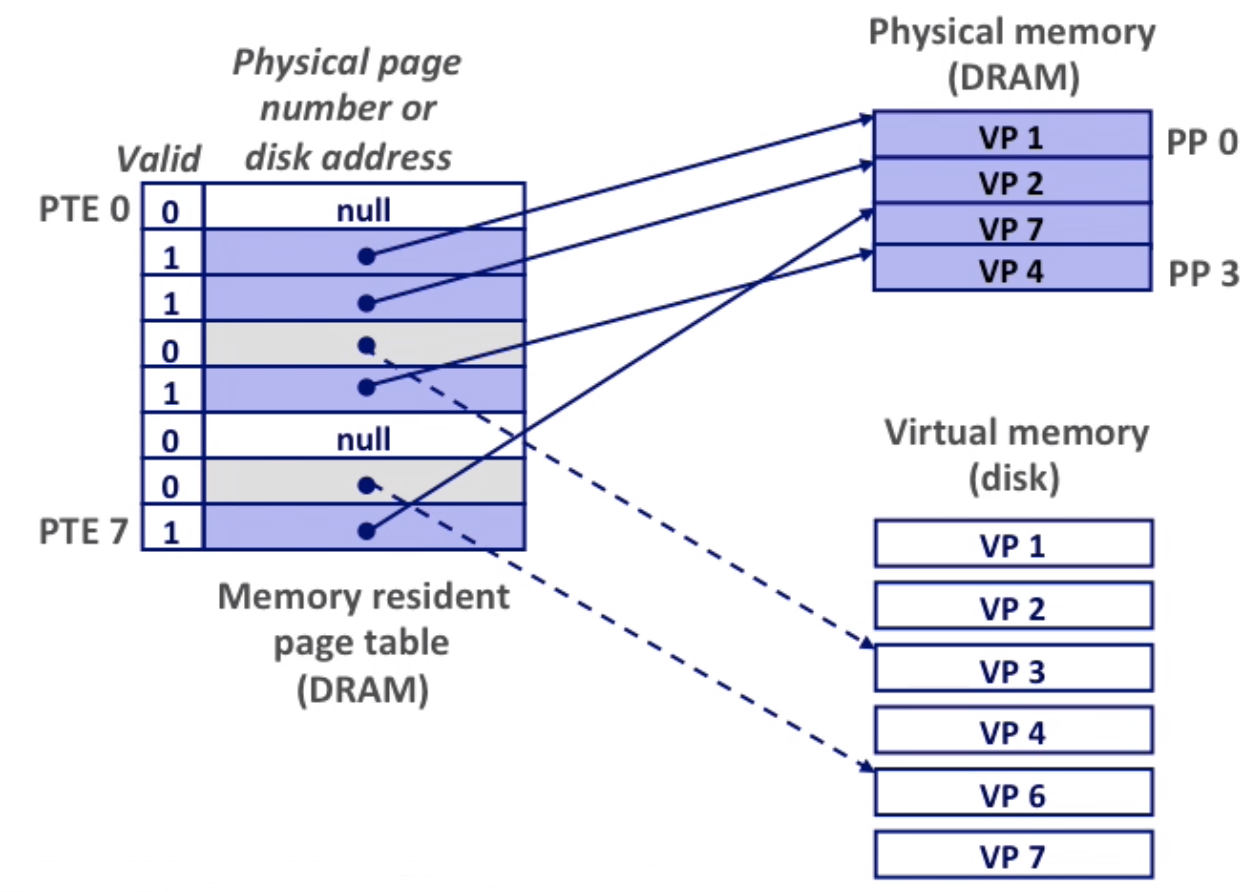
Page table is an array of PTEs(page table entries) that maps virtual pages to physical pages.
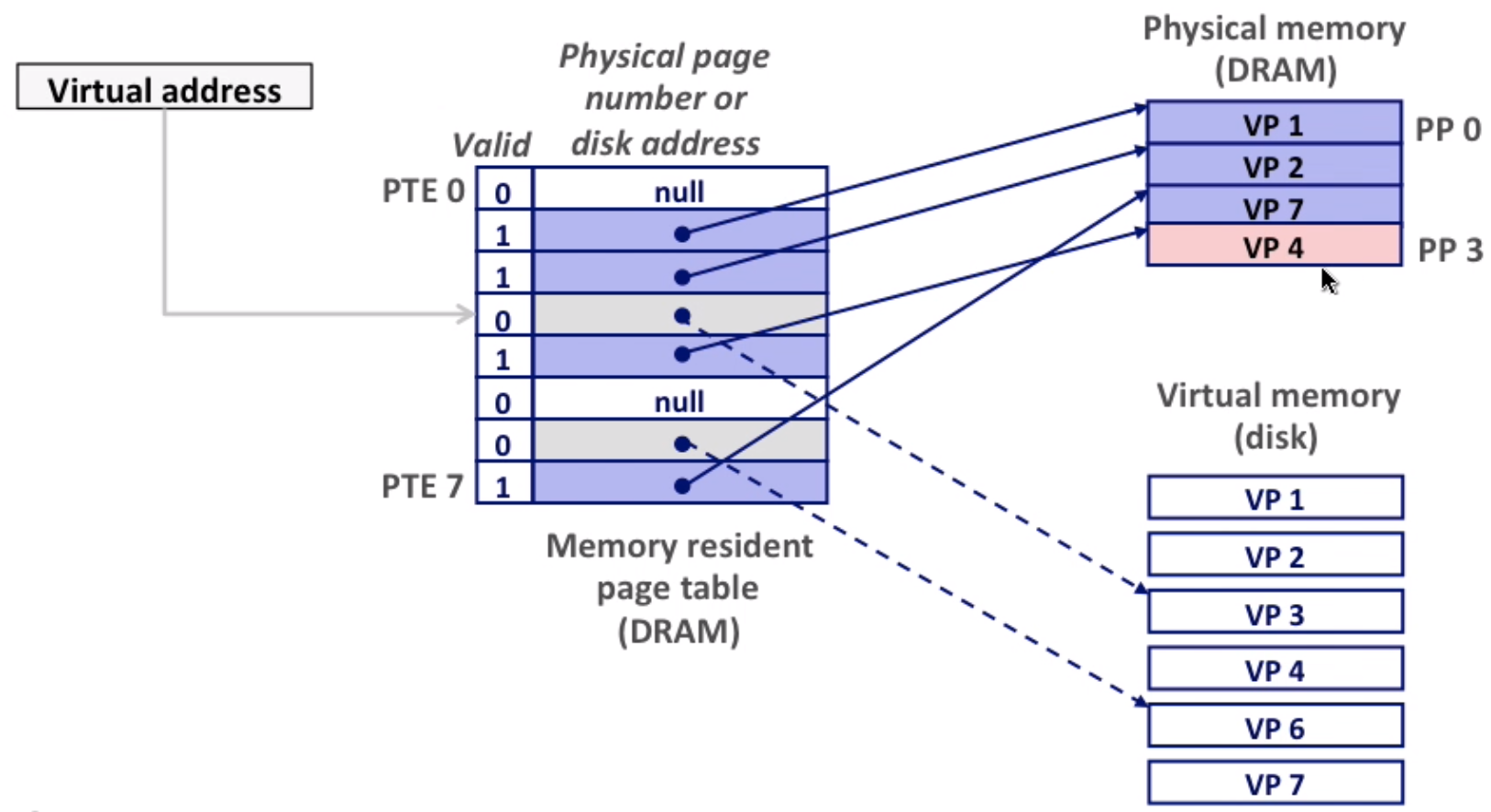
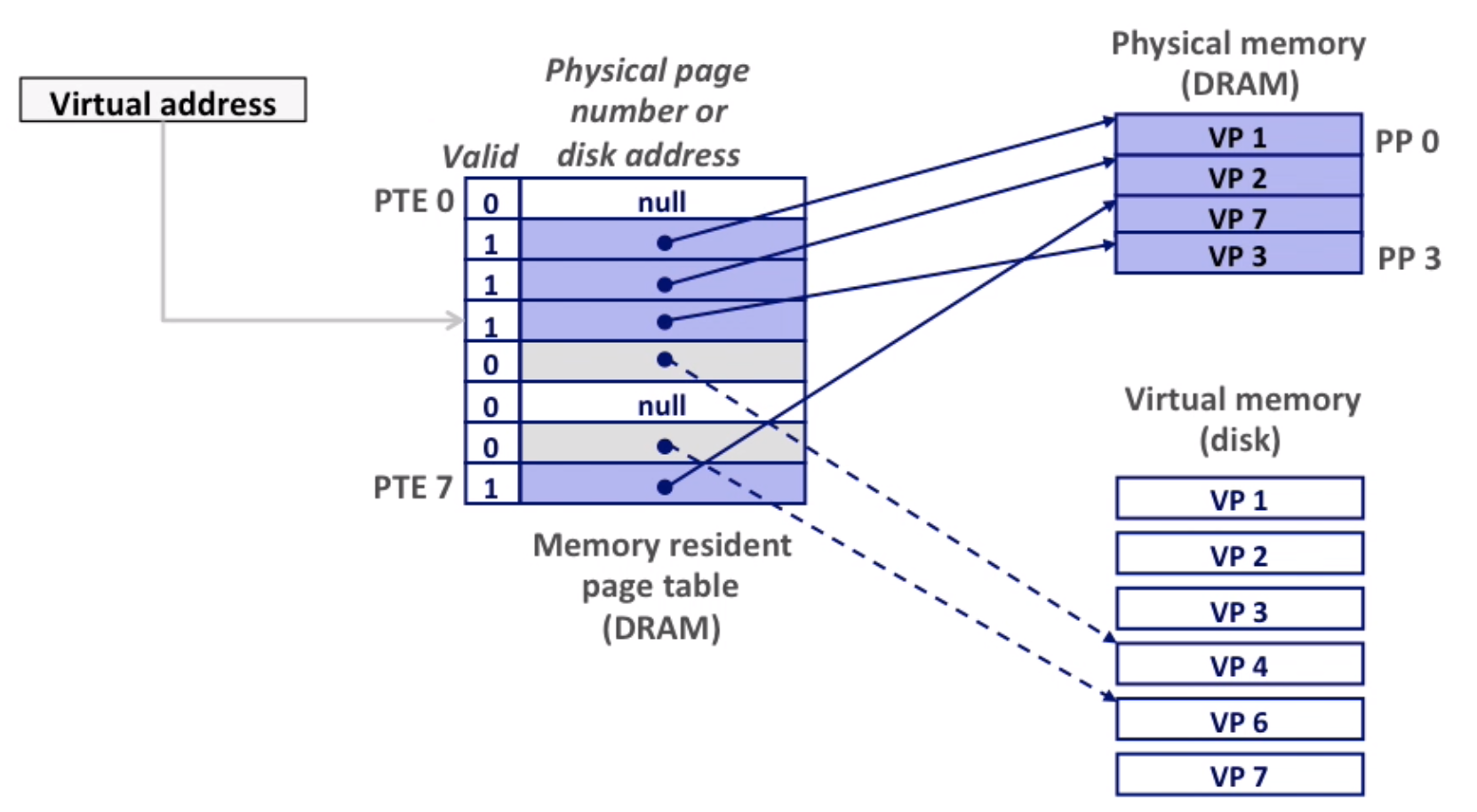
page miss causes page fault(an exception), page fault handler selects a victim to be evicted(here VP4), then put VP3 to the place of VP4
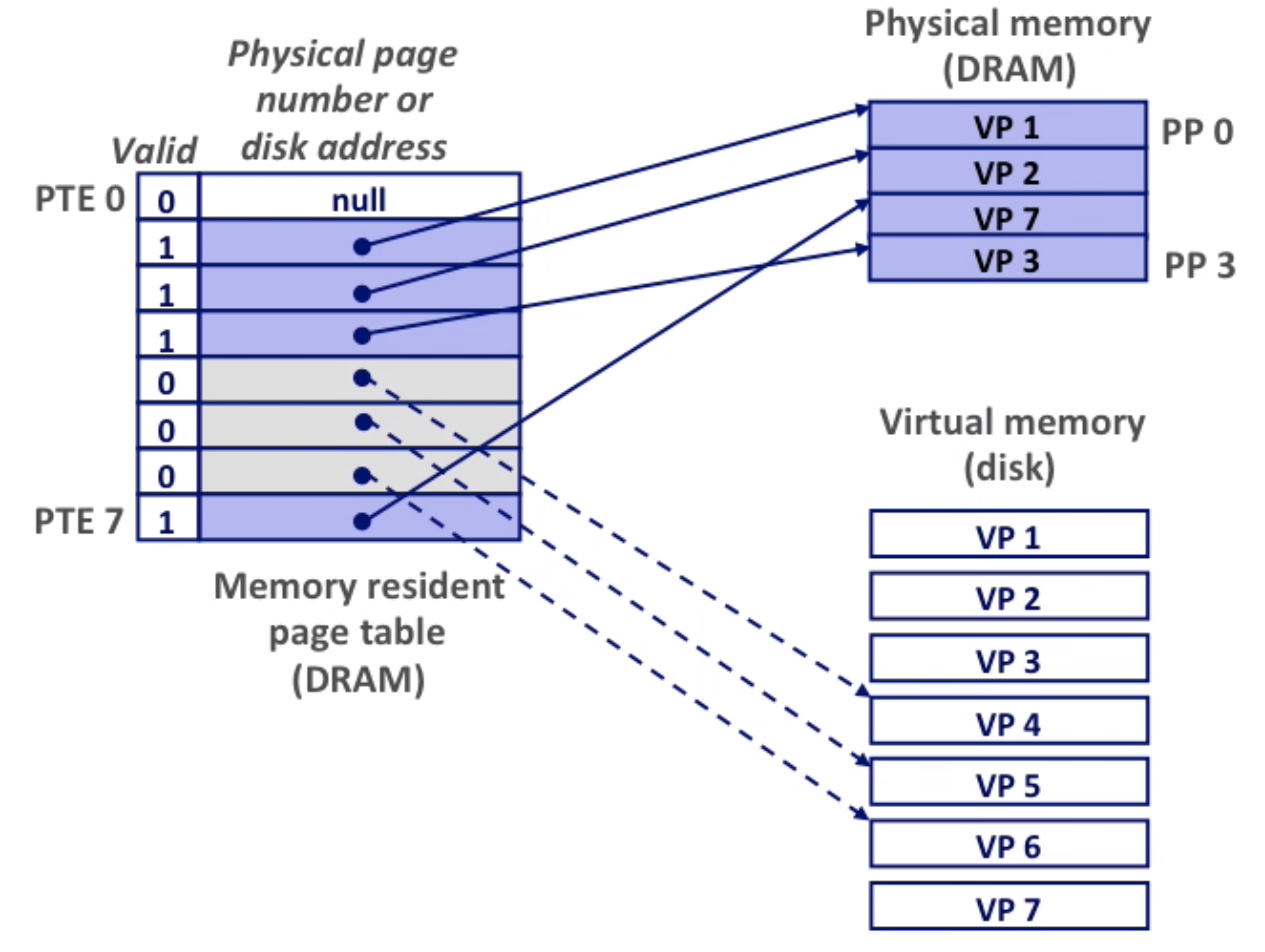
Here we allocate a new page(VP5).
The virtual memory here seems inefficient, but it works because of locality. If **working set(the active pages program tend to access)** < main memory size, good performance. Otherwise, since we need to swap pages, performance are down.
10.2 VM as a tool for memory management
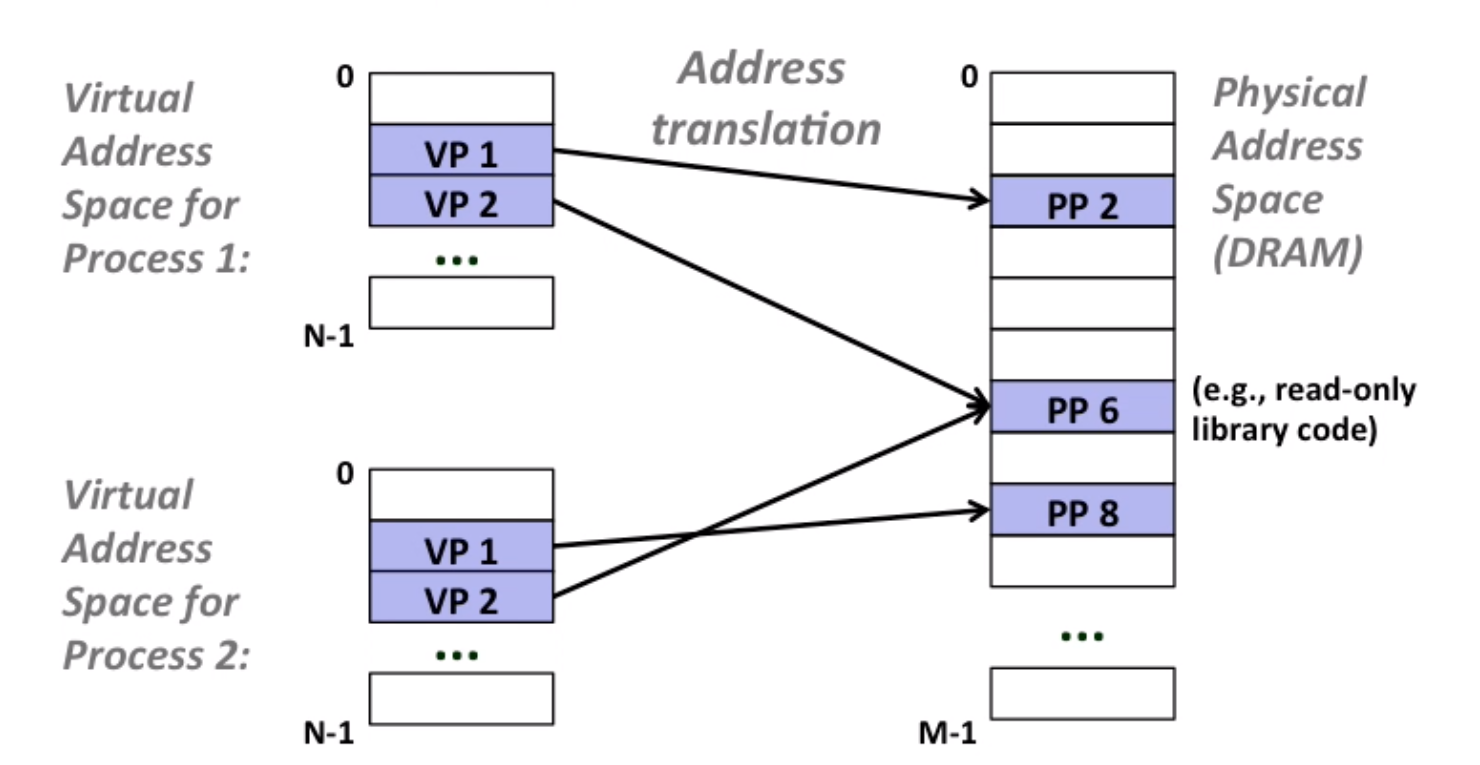
Key idea: each process has its own virtual address space
they can also share code and data(read-only)
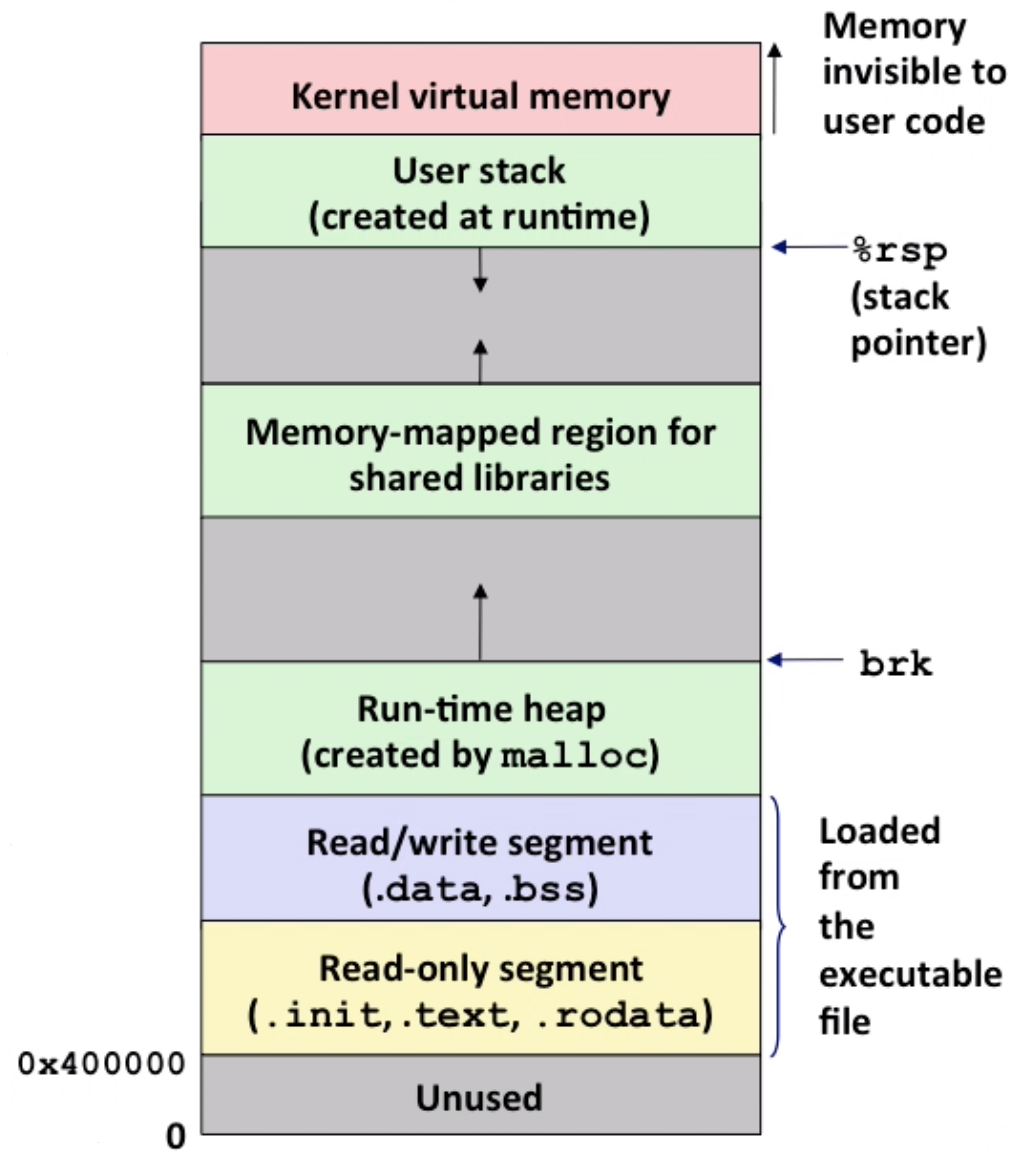
It can also simplify linking and loading:
- each program has similar virtual address space. Code, data and heap always start at the same address.
10.3 VM as a tool for memory protection
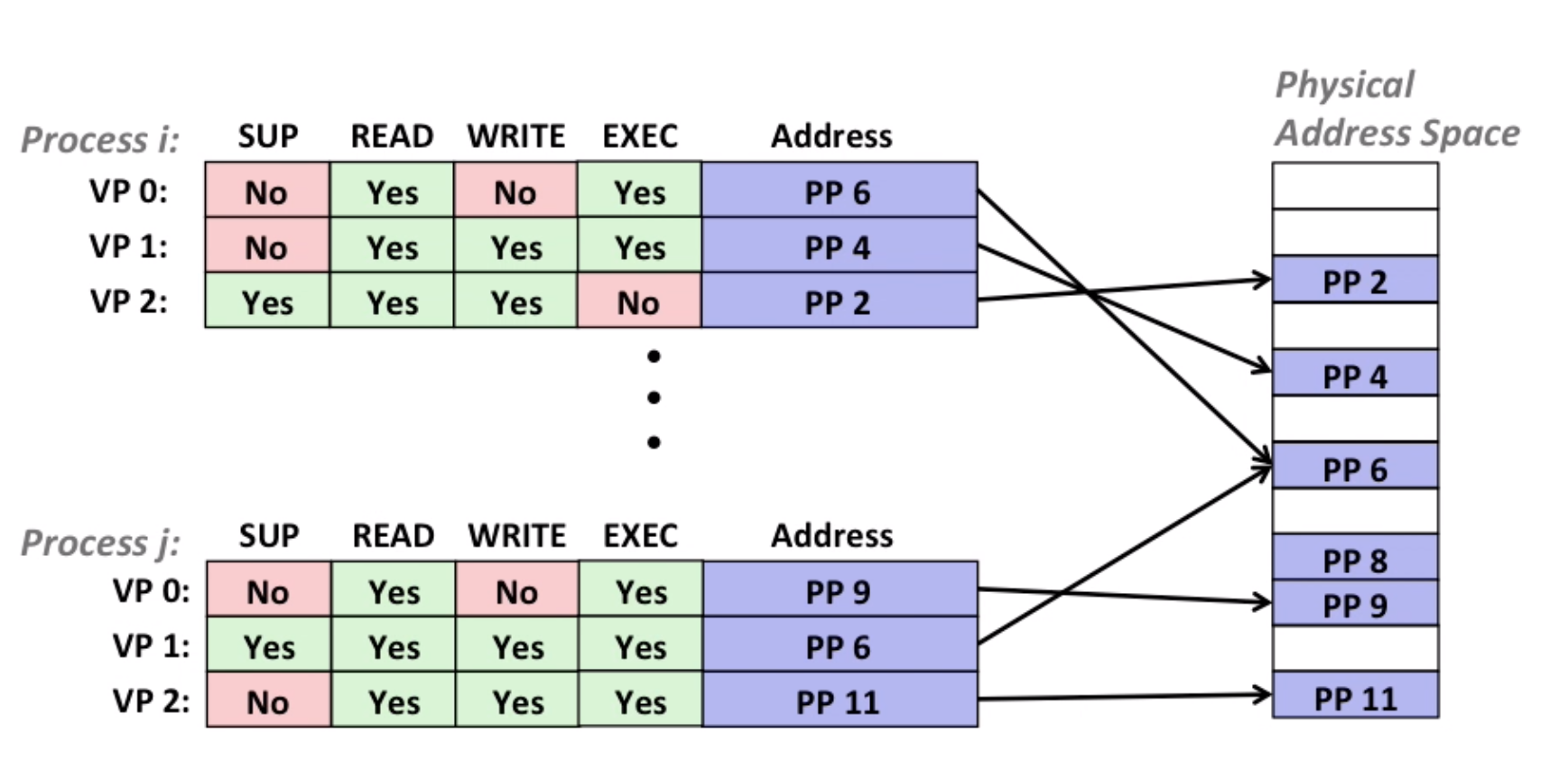
Extend PTEs with permission bits, MMU checks these bits on each access.
10.4 Address translation
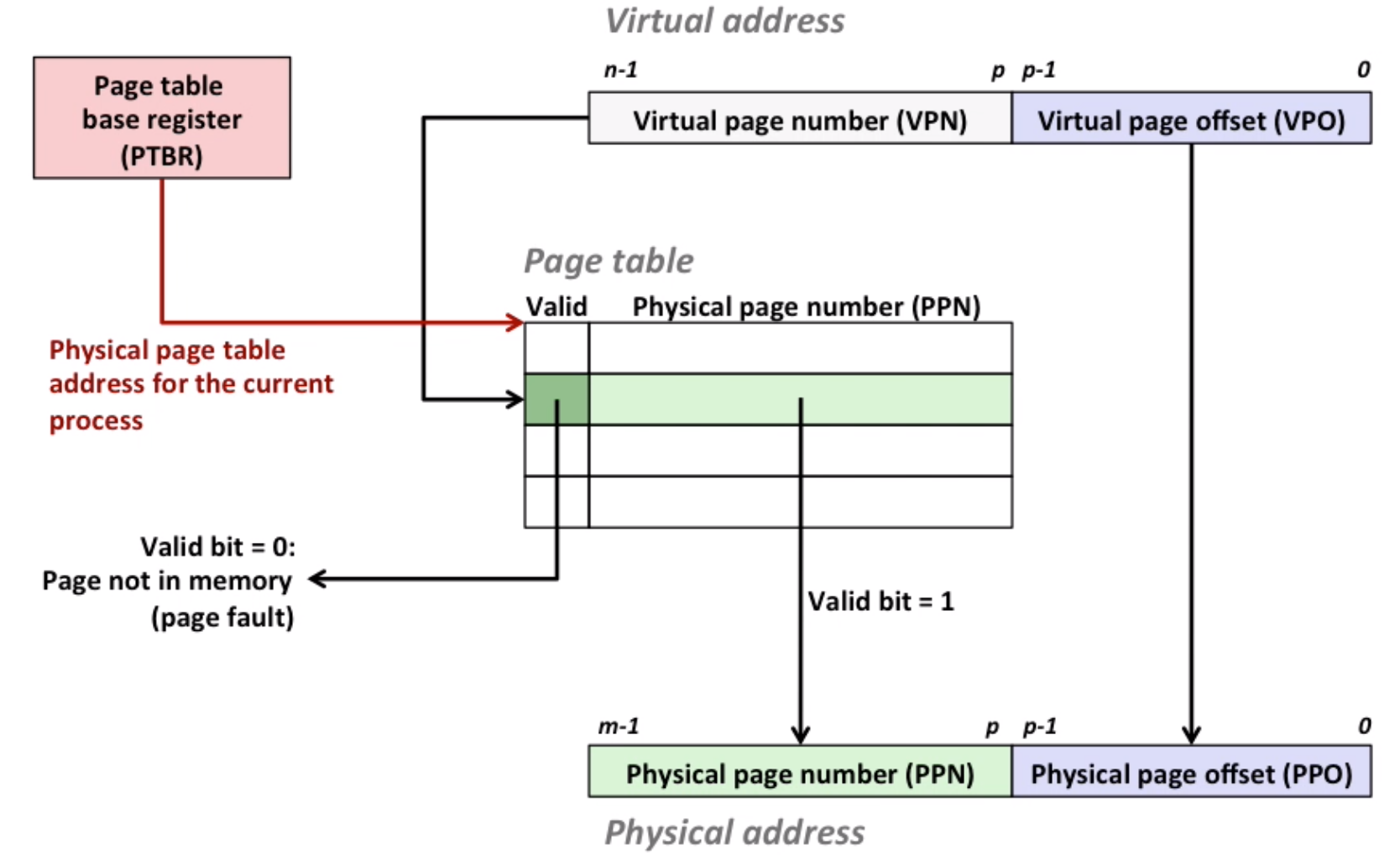
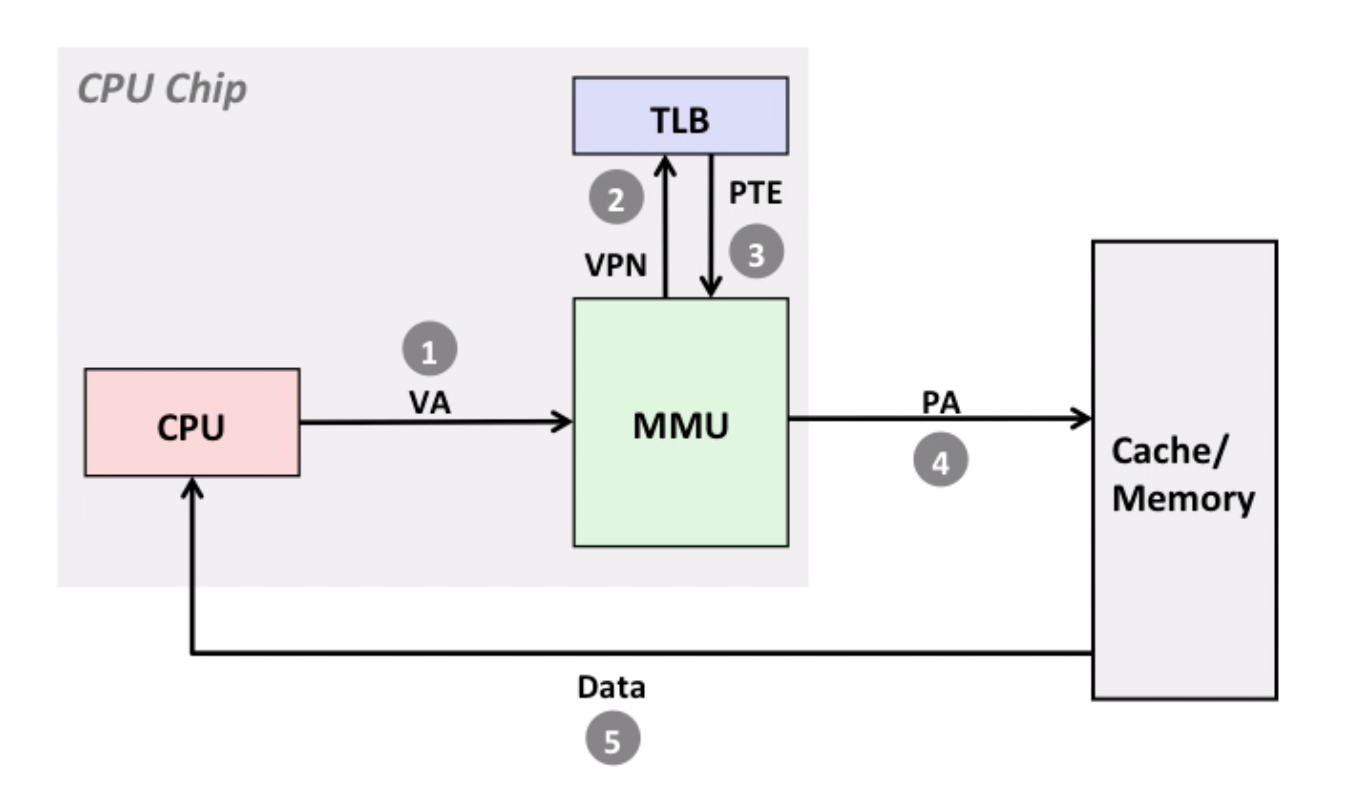
Just like a fully-associated cache system. Started by a virtual memory address, and finally get the physical memory address.
Note that offsets are the same.
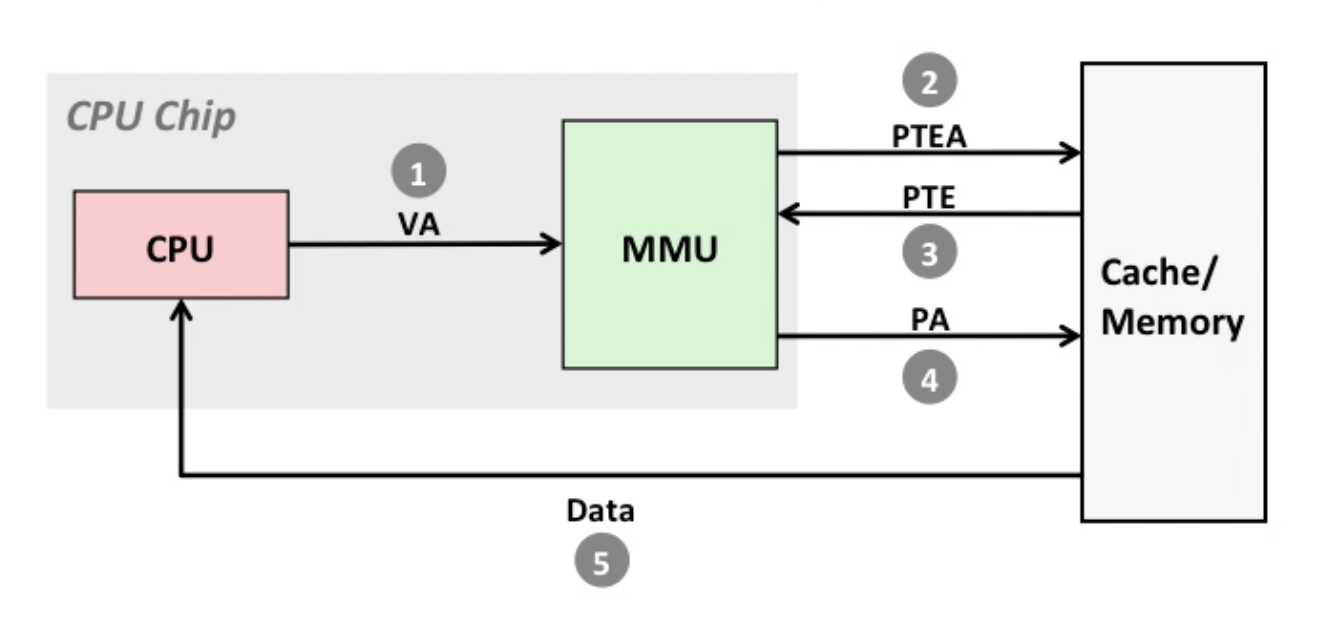
The process of page hit. Note for 2~3: MMU fetches PTE from page table in memory
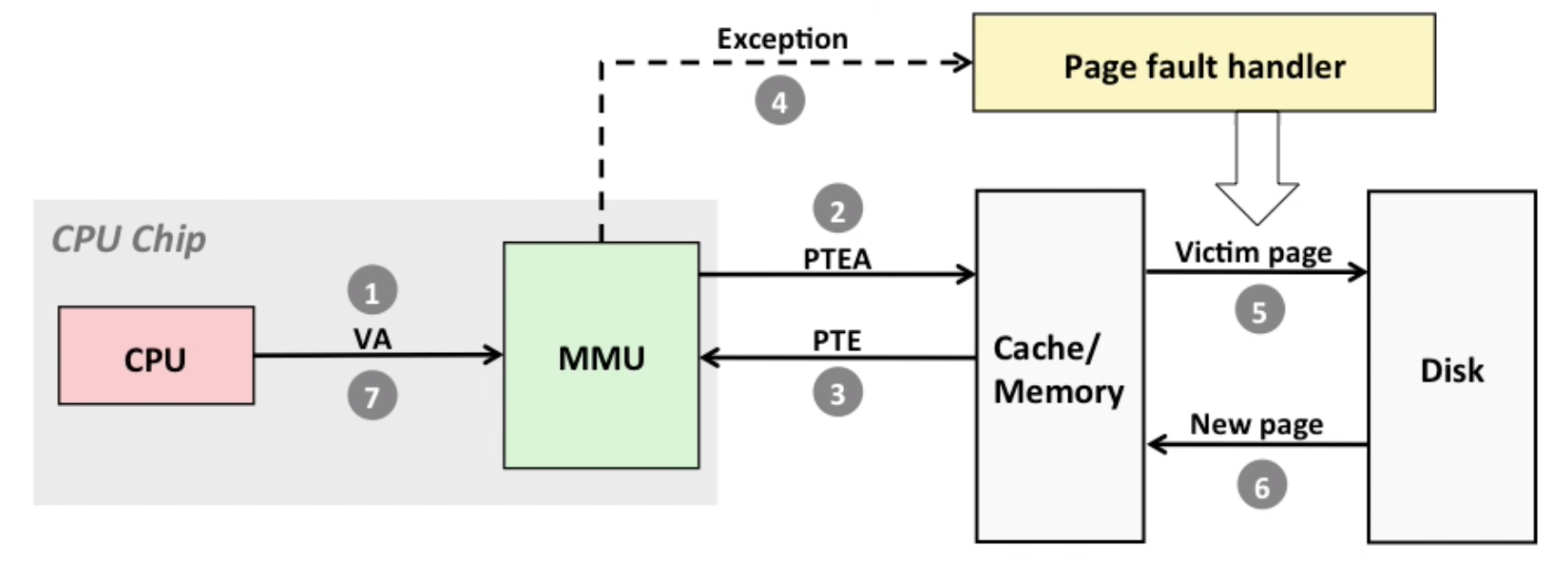
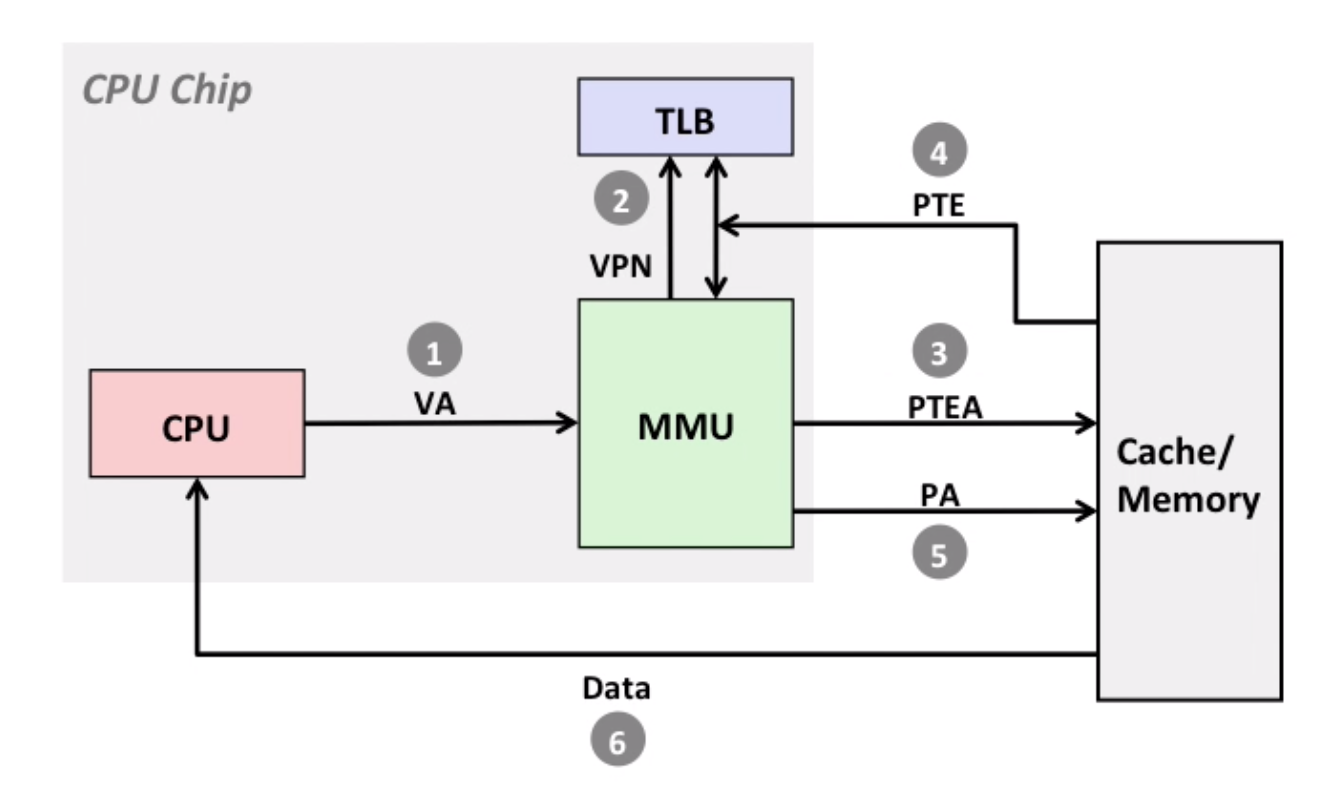
The process of page fault. Note for 7: Handler returns to original process, restarting faulting instruction.
10.5 Speeding up Translation by TLB
Basic concepts
Translation Lookaside buffer(TLB): a small set-associative hardware cache in MMU, contains complete page table entries for small number of pages.
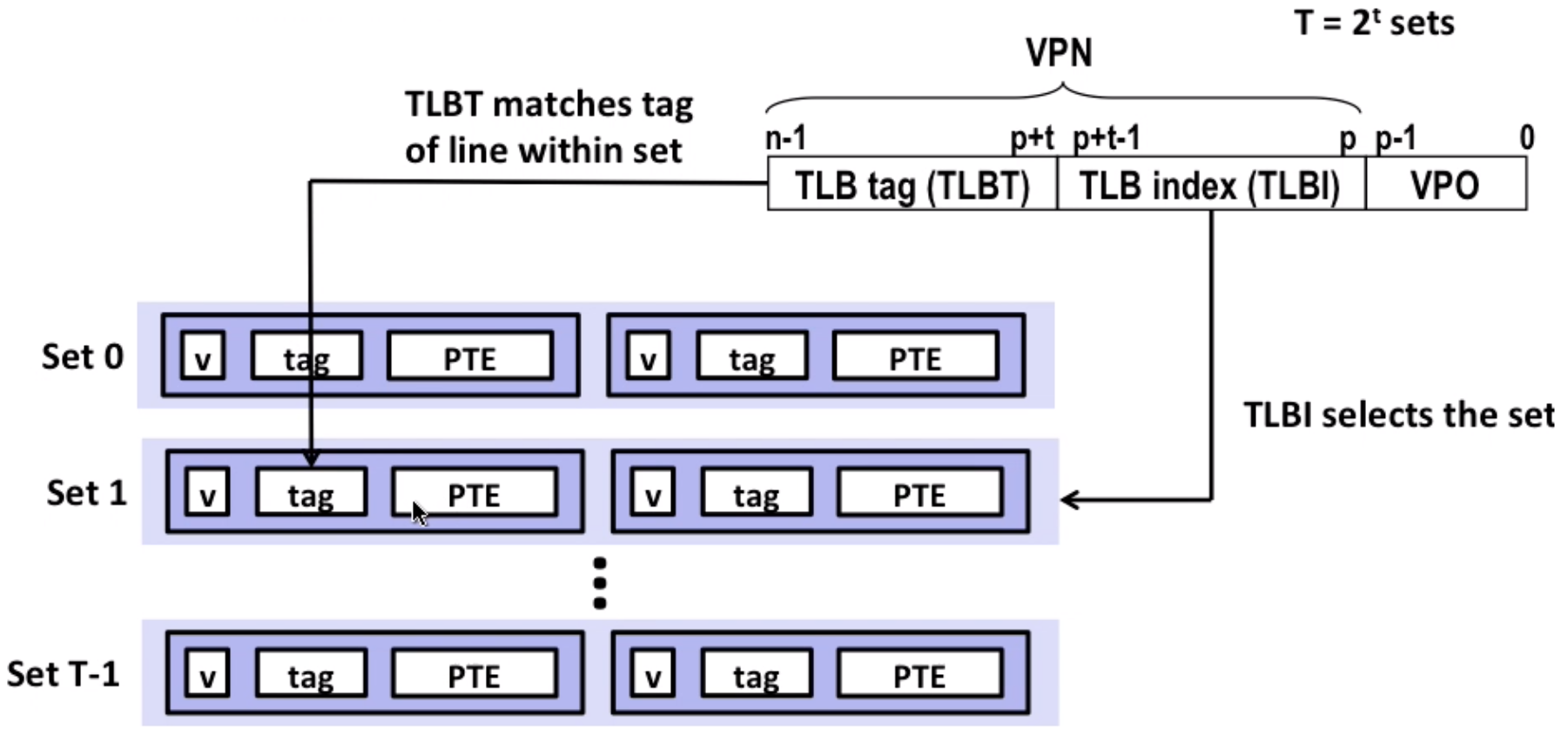
TLB-hit:
TLB-miss:
Example for TLB
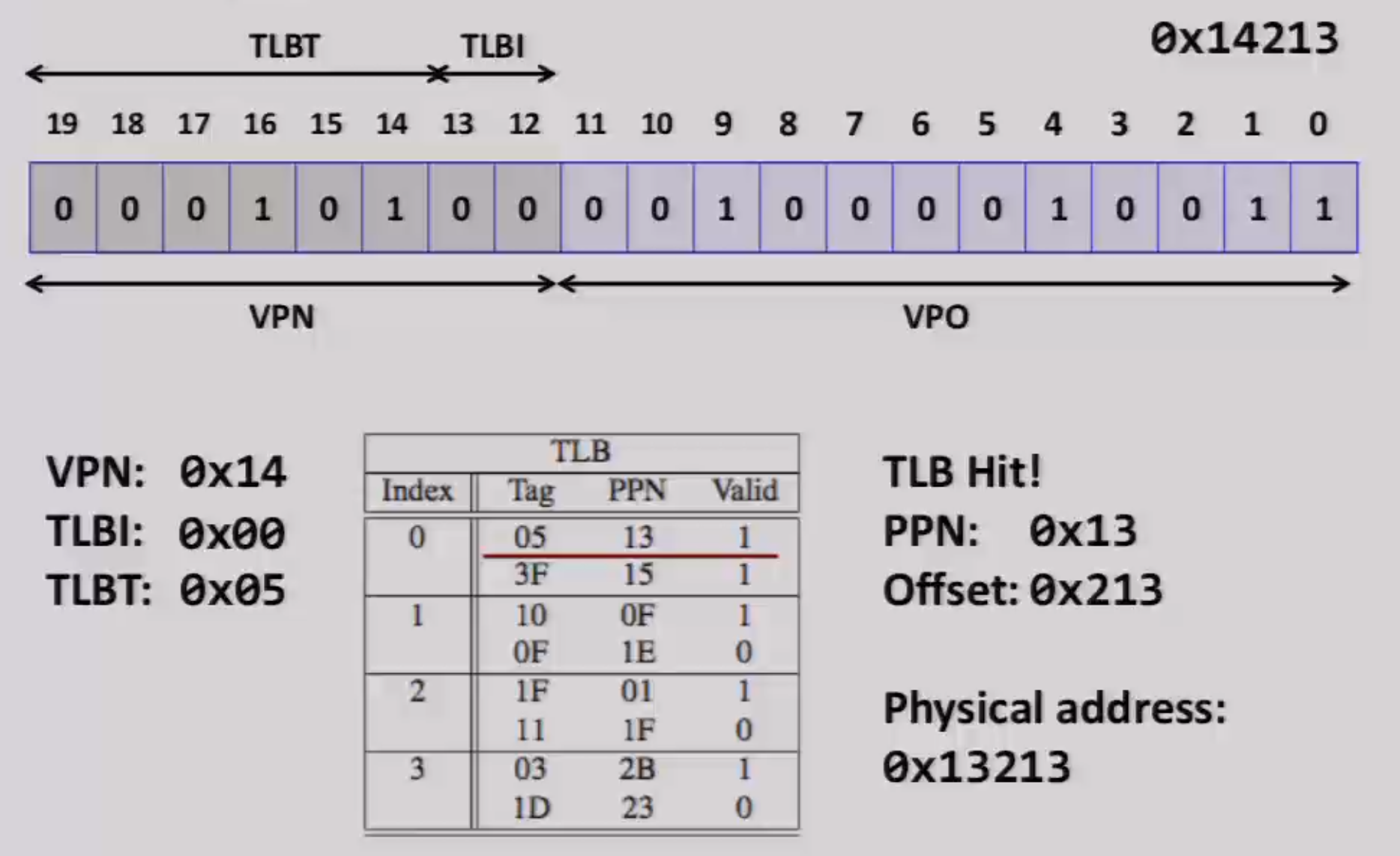
1MB of virtual memory, 4KB page size, 256KB of physical memory, TLB: 8 entries, 2-way set associative
- How many bits are needed to represent virtual address space? 20 (
2^20 = 1MB) - How many bits are needed to represent physical address space? 18
- How many bits are needed to represent offset? 12 (
2^12 = 4KB) - How many bits are needed to represent VPN(virtual page number)? 8
- How many bits are in the TLB index? 2 (since we have four sets totally)
- How many bits are in the TLB Tag? 6 (just the rest)
Another example:
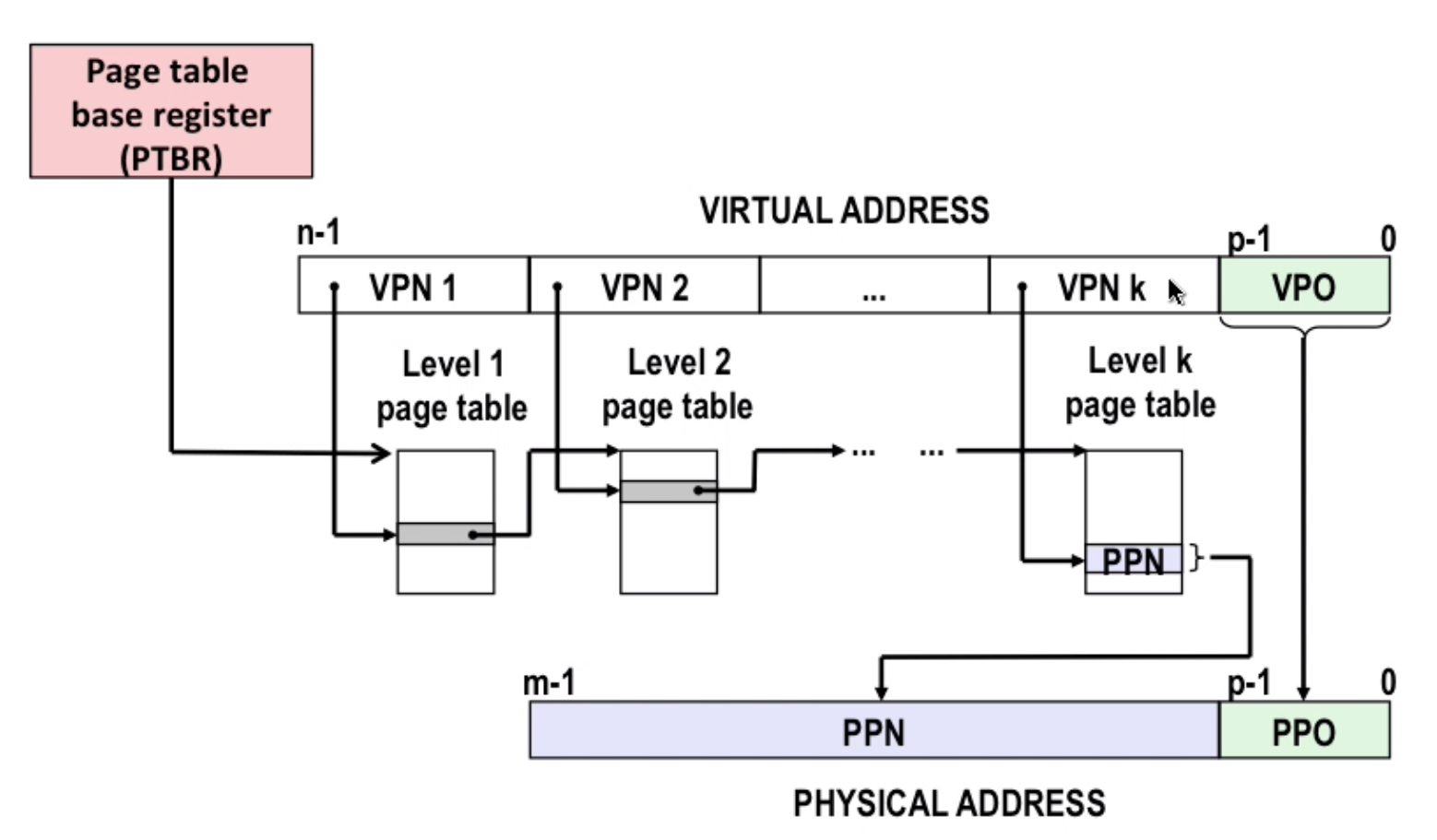
10.6 Multi-Level Page Table
One-Level page table can take up a lot of space.
Eg: 32 bit-environment, 4 KB(2^12) page size, we should have 2^32 * 2^-12 = 2^20 pages, 4-byte PTE, totally 2^22 bytes = 4MB for one process. 1000 process = 4GB
Eg2: 64 bit-environment, 4KB page size, 48-bit address space(24 bits reserved), we should have 2^36 pages, 8-byte PTE, totally 2^39 bytes = 512GB page table!
Note: page size means dividing physical memory into several blocks, the size of block is page size. PTE is for offset in a page(and some privileged bits).
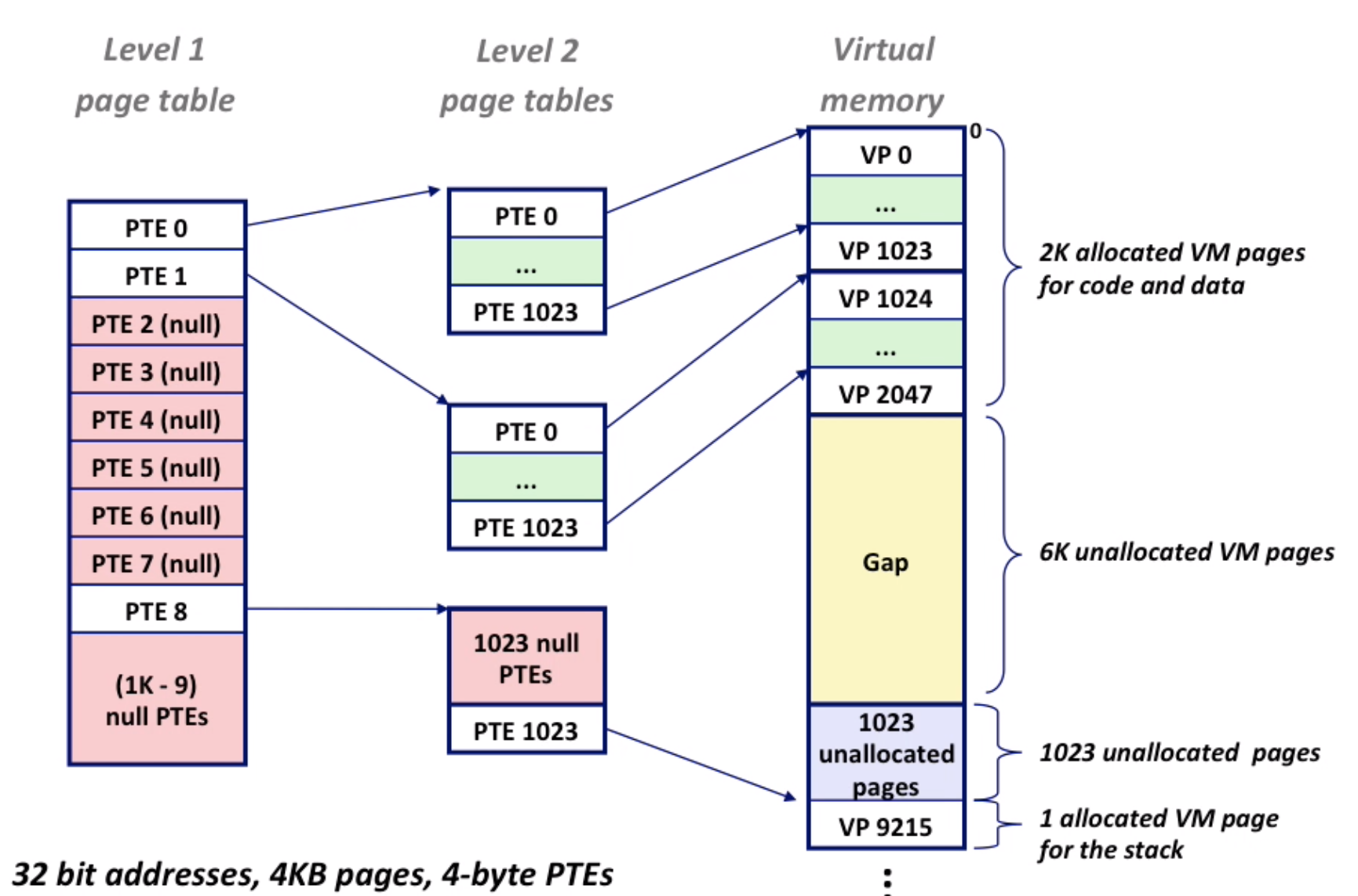
The way to translate multi-level-page-table:
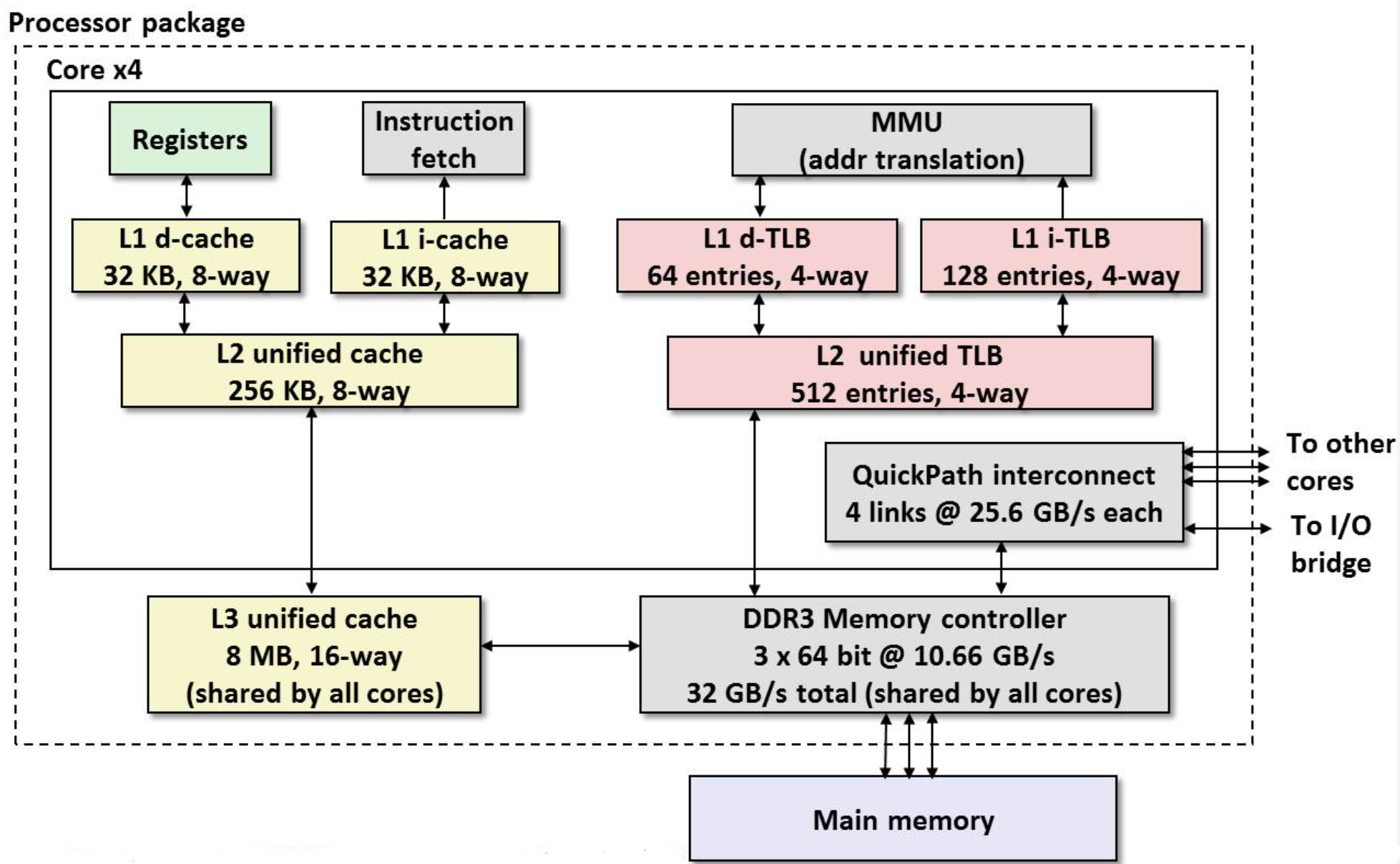
10.7 Intel Core i7 Memory System
10.8 Memory Mapping
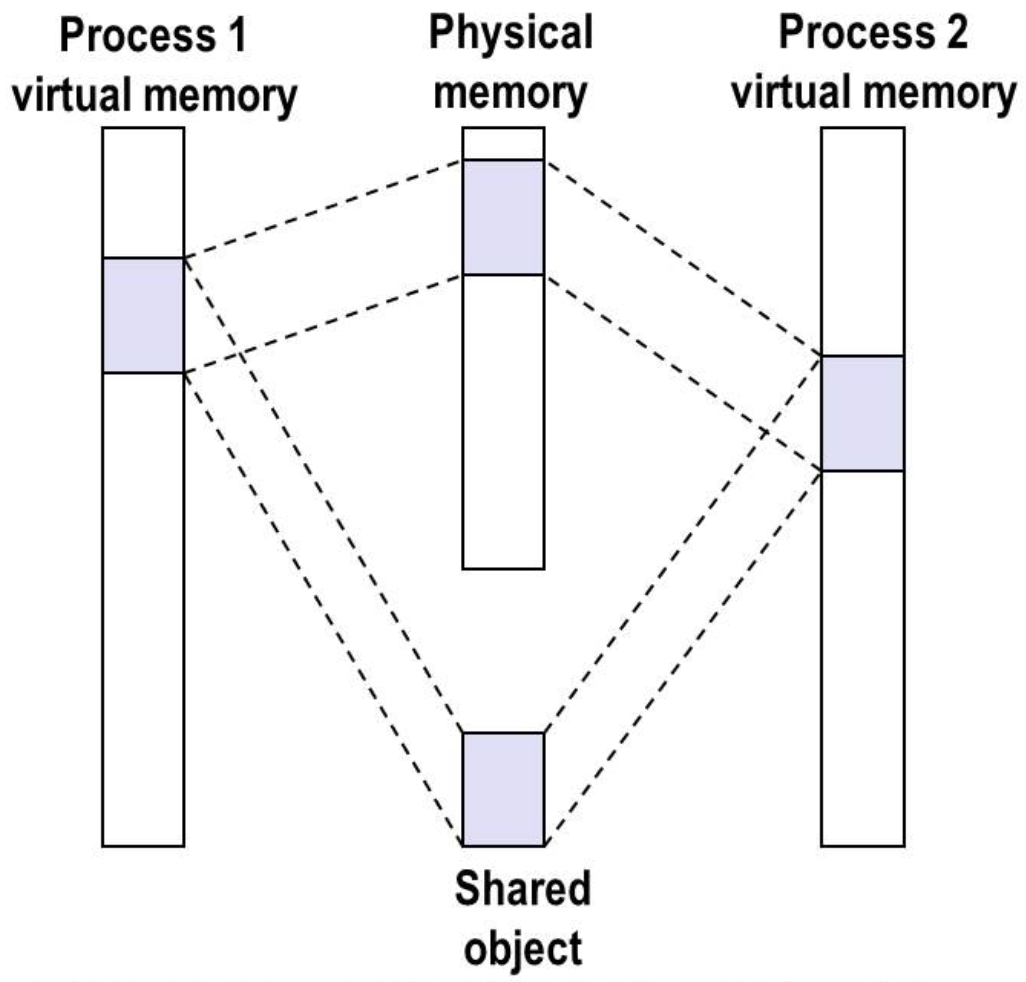
Mapping memory to file.
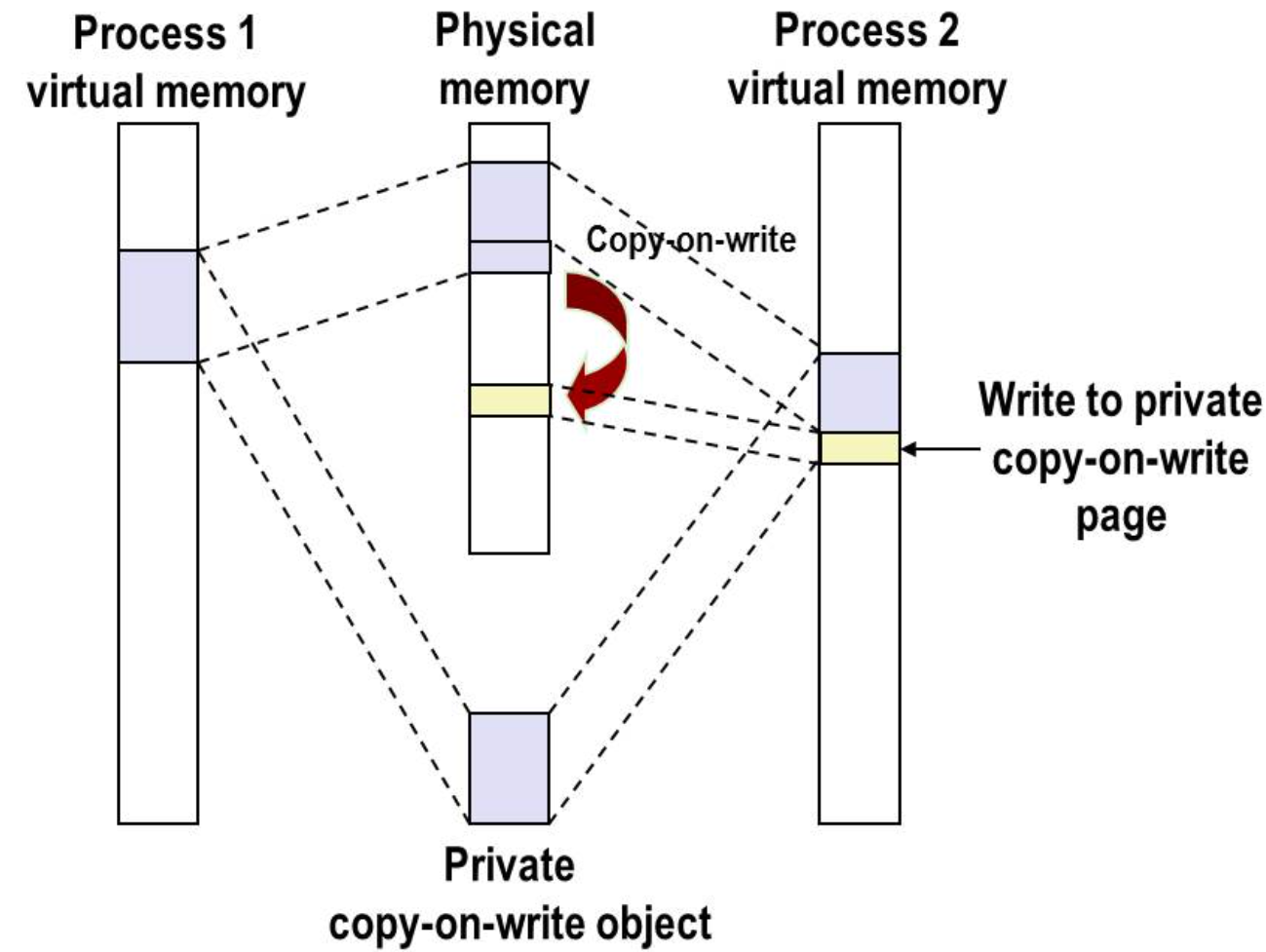
Private Copy-on-write(COW) objects.
And Note that this is why fork can be efficient. It doesn’t really copy data that can be shared by two processes.
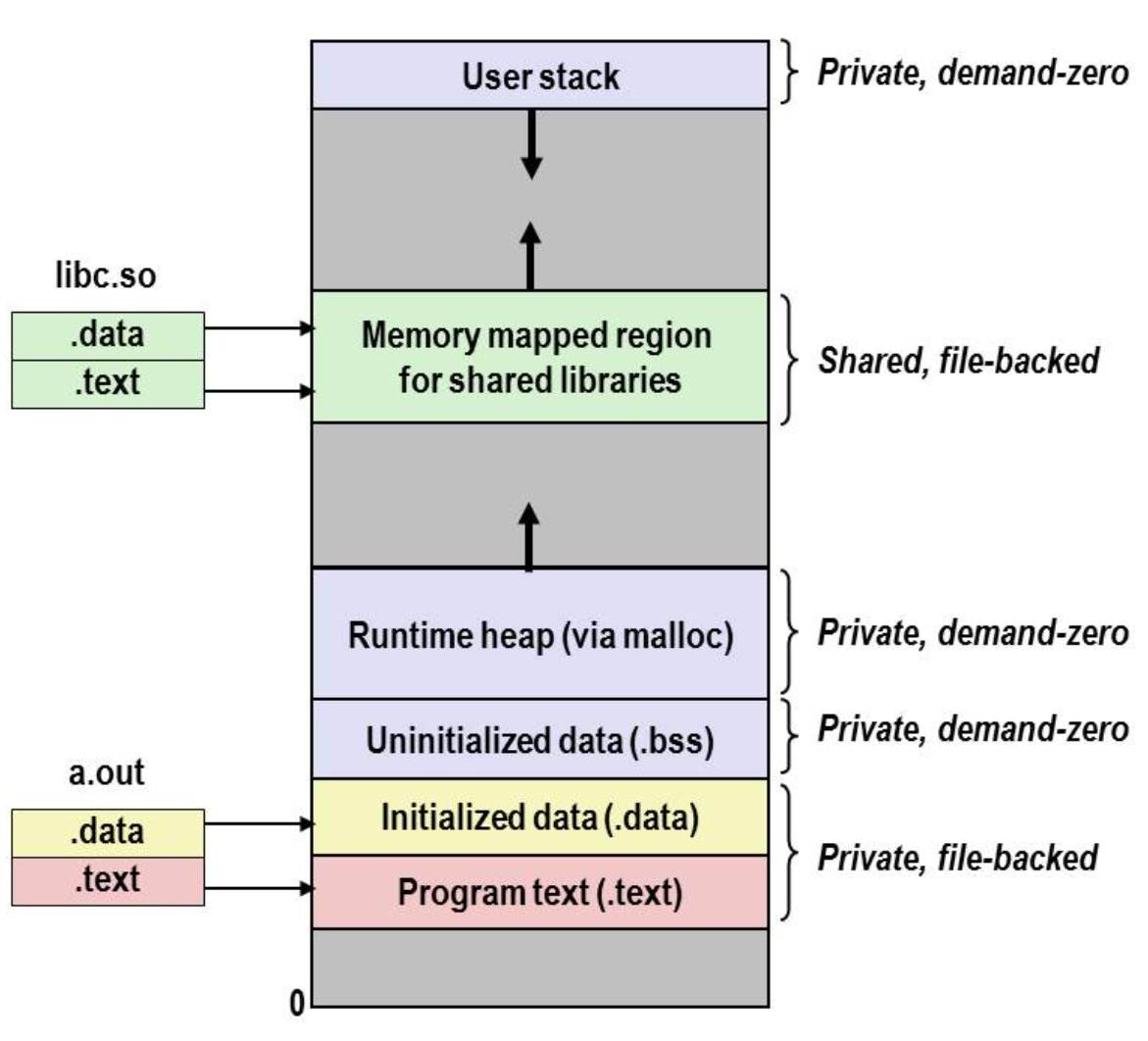
The process of execve(load and run a new program in the current process):
- free
vm_areaand page table for old areas - create
vm_areaand page table for new areas - set PC to entry point in
.text
Using memory mapping a lot here.
mmap: allows you to do memory mapping like kernel does.
11. Dynamic Memory Allocation
11.1 Basic concepts
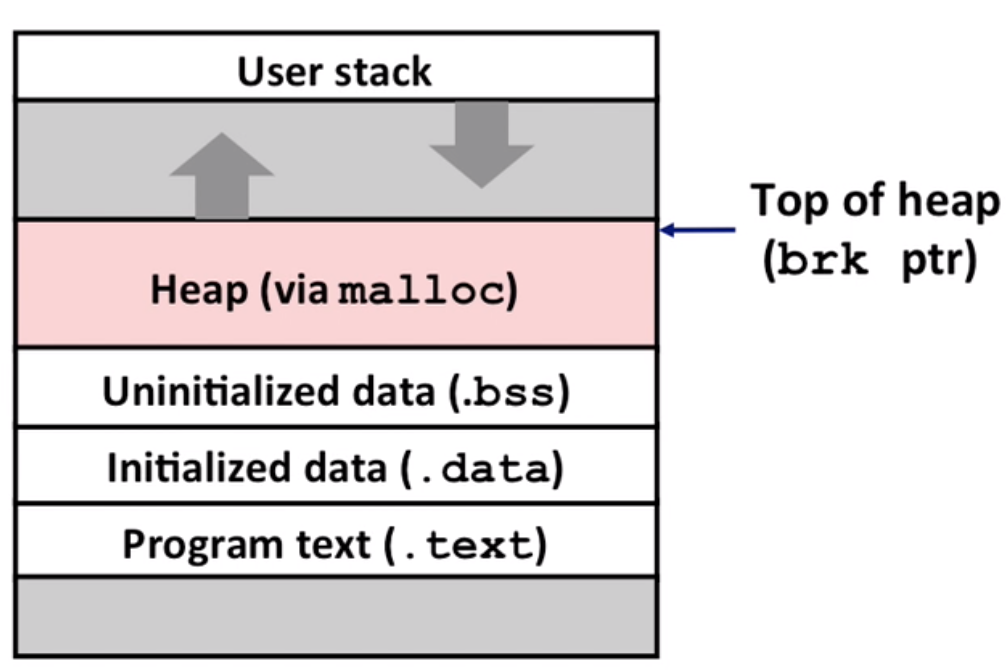
Require virtual memory by using ways such as malloc(to Heap, maintained by blocks).
Allocators:
- explicit allocator: C
mallocandfree - implicit allocator: java allocates memory but do not need free (garbage collection)
Note: in this lecture, the unit of malloc is word(4 bytes)
Example:
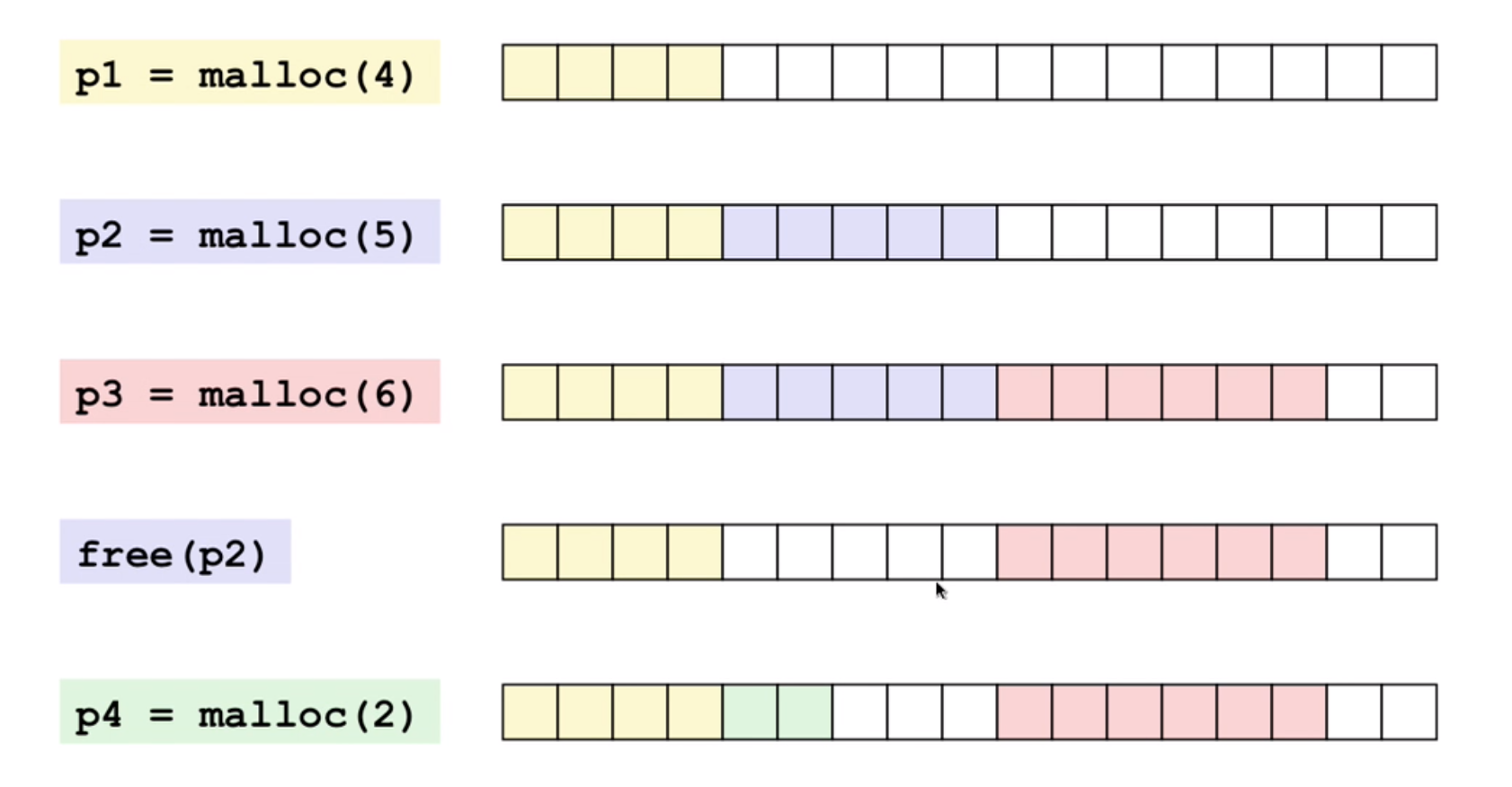
Fragmentation:
- Internal fragmentation: Blocks have to be aligned, when payload is smaller than one single block, this happens.
- External fragmentation: As the picture shows above, the fragmentation appears.
Q: How much to free? (since we only have a pointer passed to the free function?)
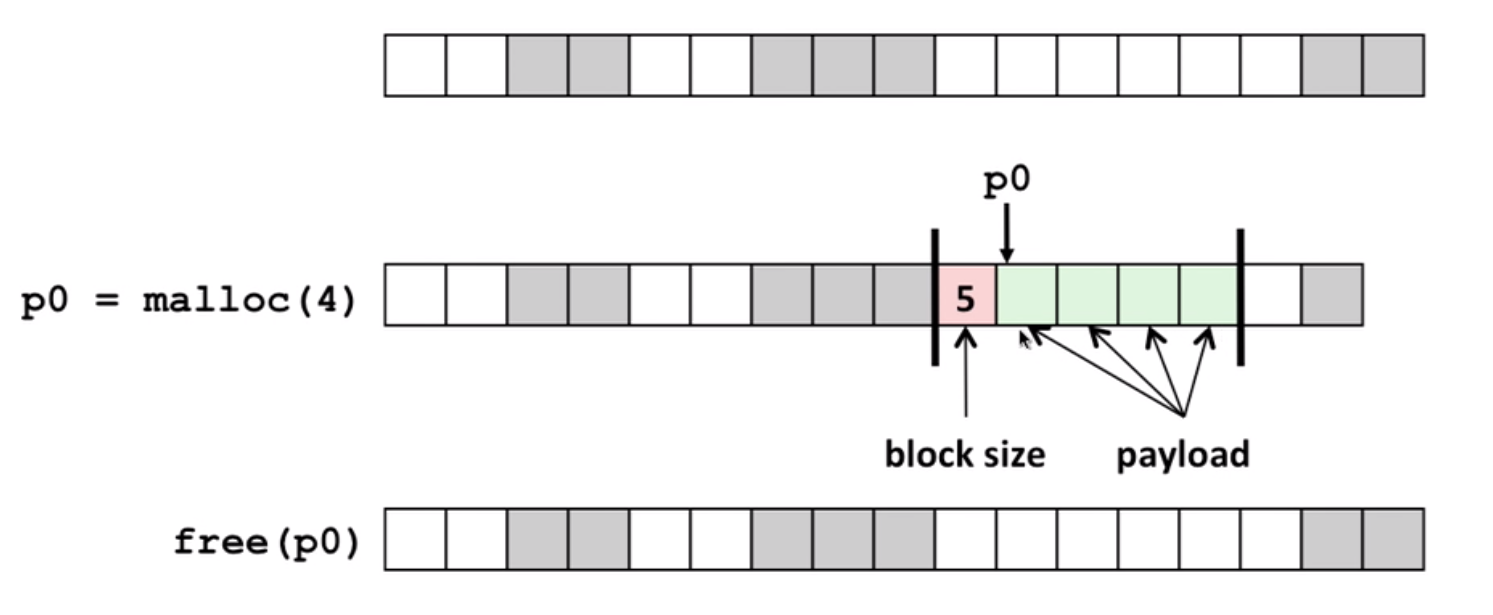
A: by using a header
11.2 Implicit list
Q: How to keep track of free blocks?
A: Implicit list to links all of (headers of) the blocks. Additional bit for allocation status. Trick: if blocks are aligned, some low-order bits are always zero(4 bytes, 1000…)
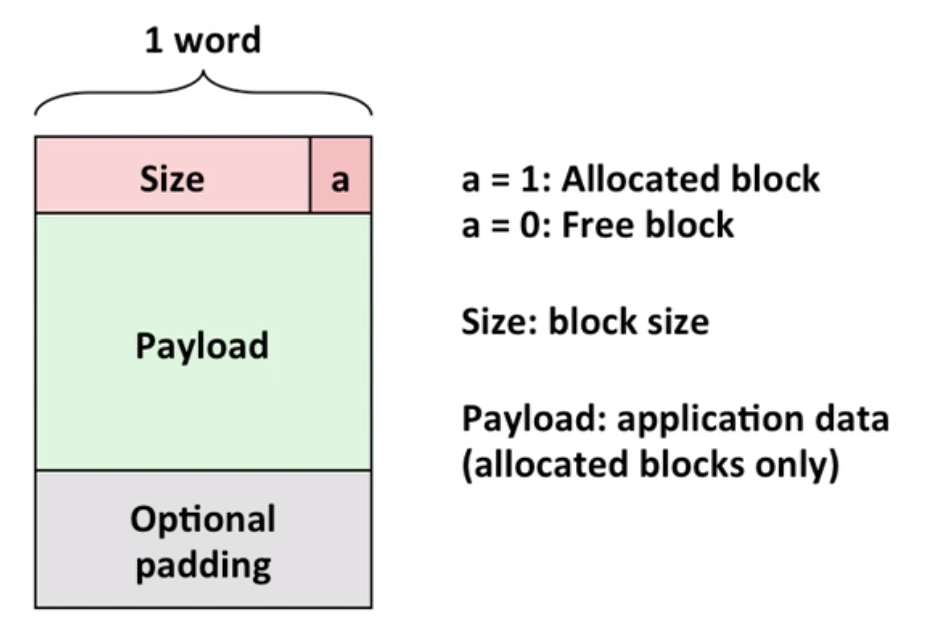
example:
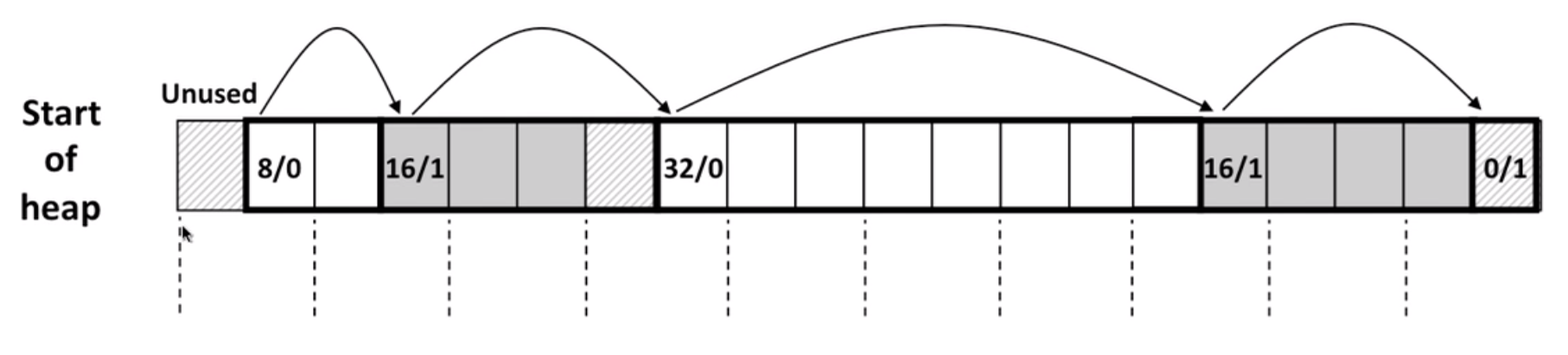
final block(size 0 / status 1) to be the end of search.
Q: ways to use implicit list?(placement policy)
A:
- first fit: scan from the beginning
- next fit: scan starts from the last malloc(fast but maybe more fragments)
- best fit: search all of the list and find the best malloc to reduce fragments
Q: How to free by using implicit list?
A: Coalescing
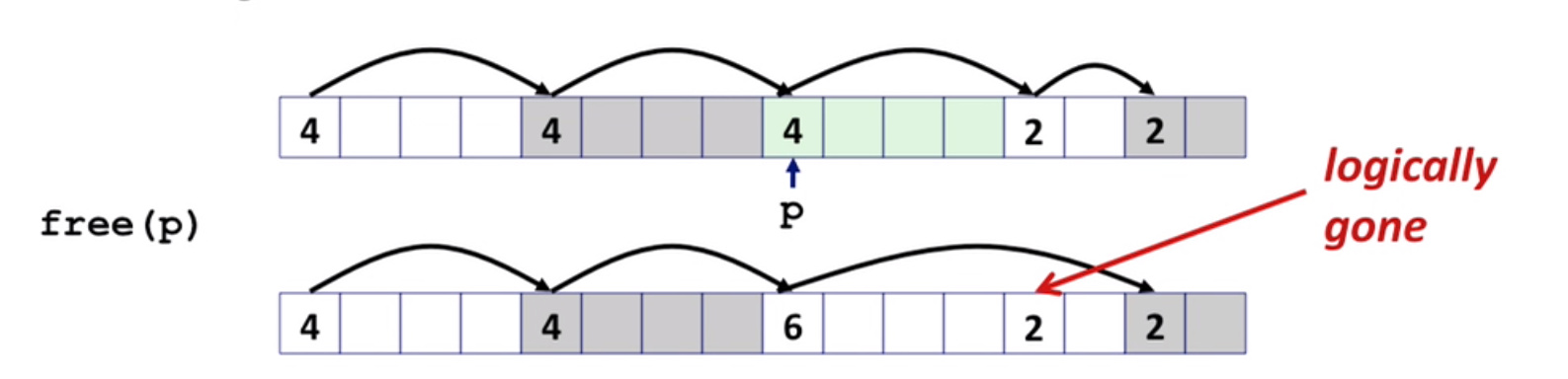
But in this way we couldn’t coalesce the block we used before.
So we can use boundary tags(constant free even with coalescing):
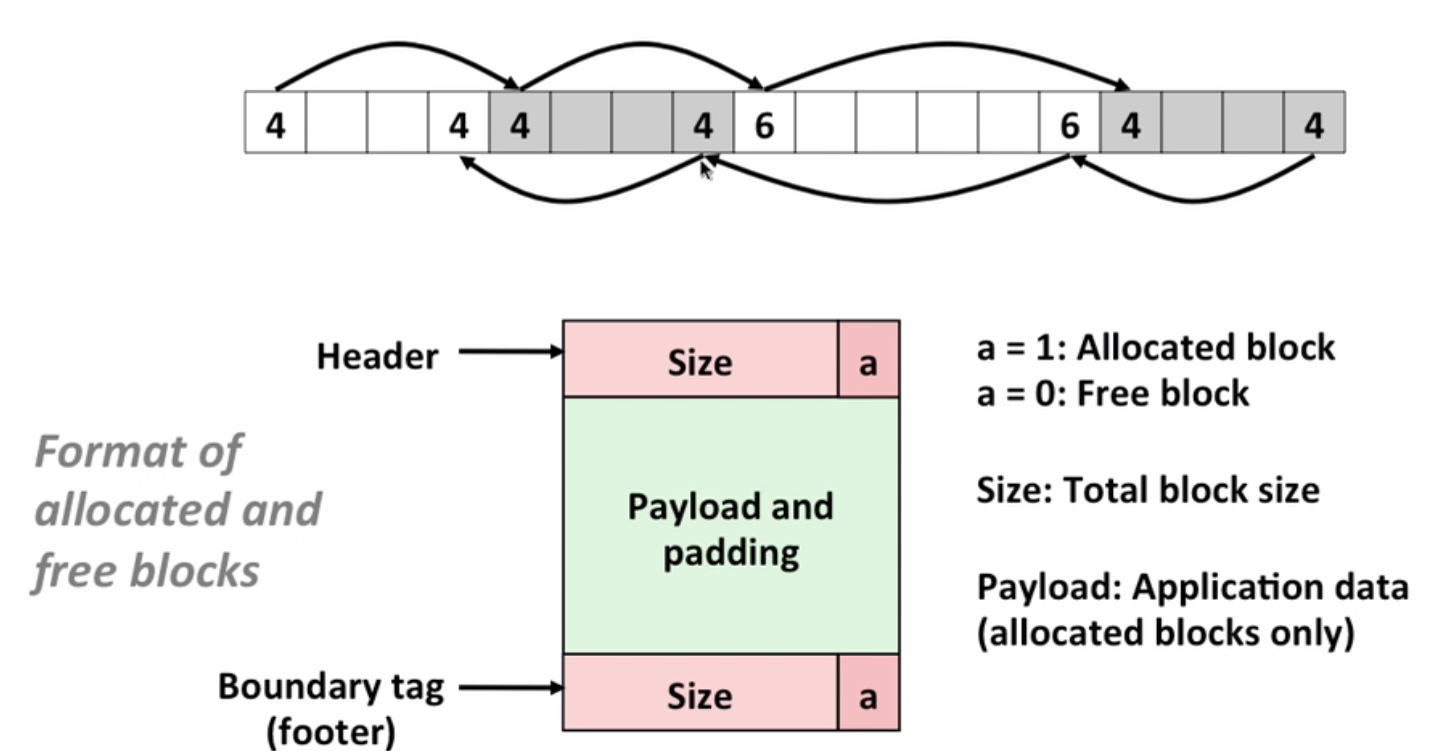
Note: boundary tags can be also optimized. For example, we can add additional status bit to represent whether the previous block needs to coalesce.
Coalescing policy:
- immediate coalescing: coalesce each time
freeis called - deferred coalescing: coalesce as you scan the list for
mallocor external fragmentation reaches some threshold.
11.3 Explicit free lists
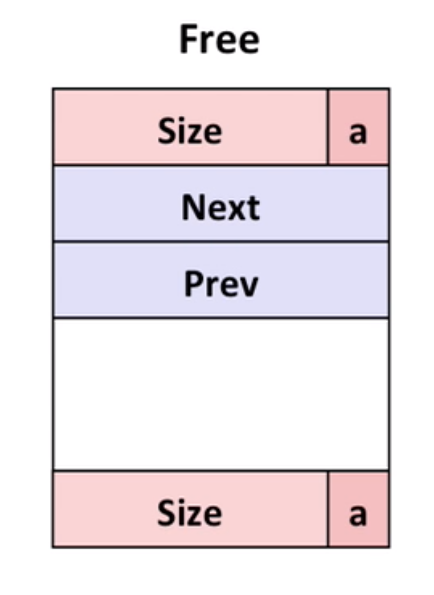
Maintain list of free blocks. That’s why we can use payload area.
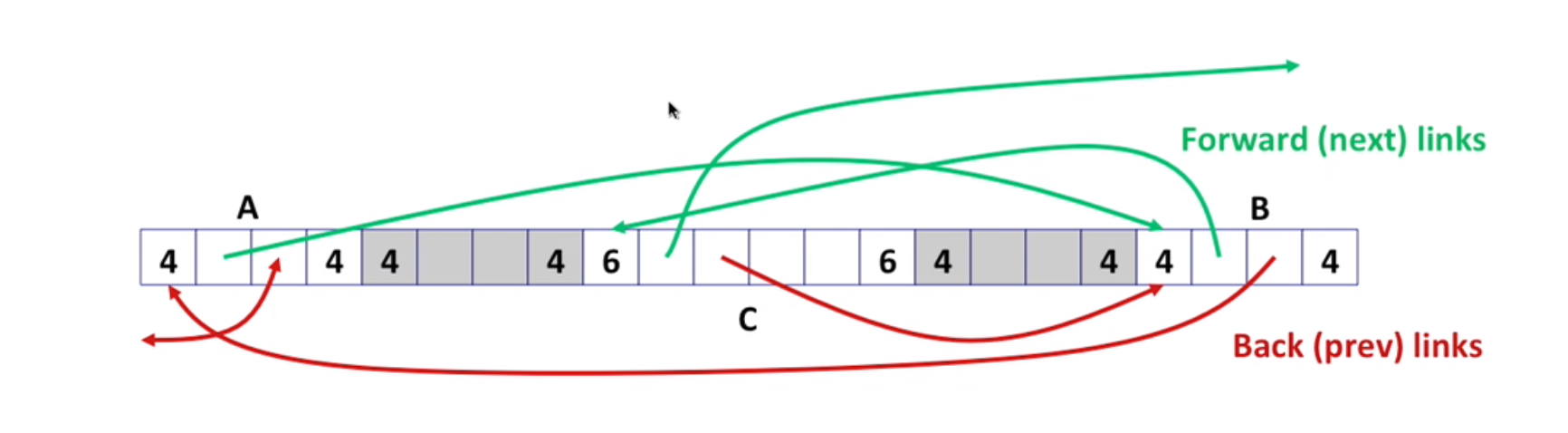
Note that blocks can be in any order.
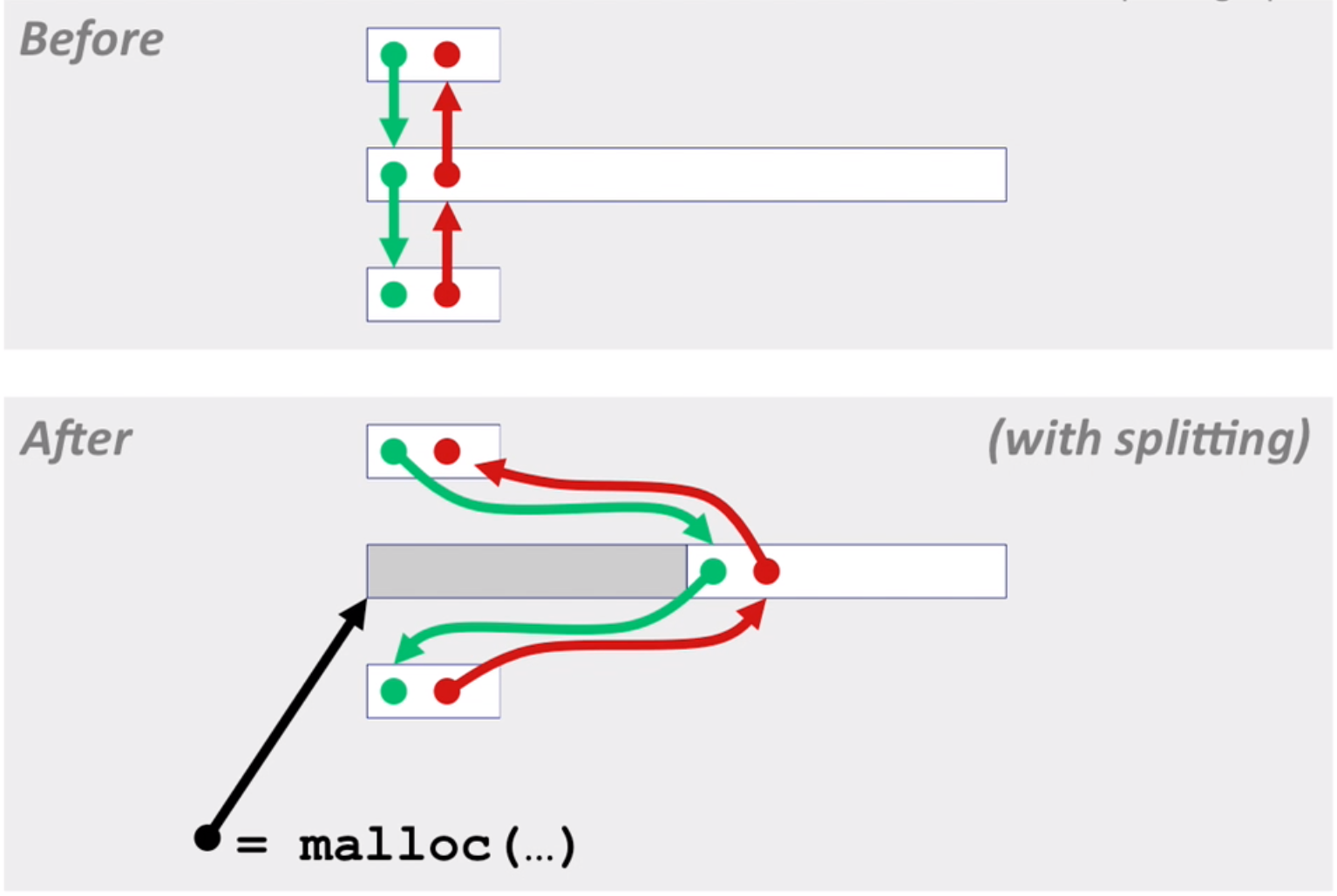
It’s easy to allocate now.
For free, tow policies:
LIFO(last-in-first-out)
- insert freed block at the beginning of the list
- simple and constant time, more fragmentation
Address-ordered policy
- make sure
addr(prev) < addr(curr) < addr(next) - requires search but less fragmentation.
- make sure
LIFO eg:
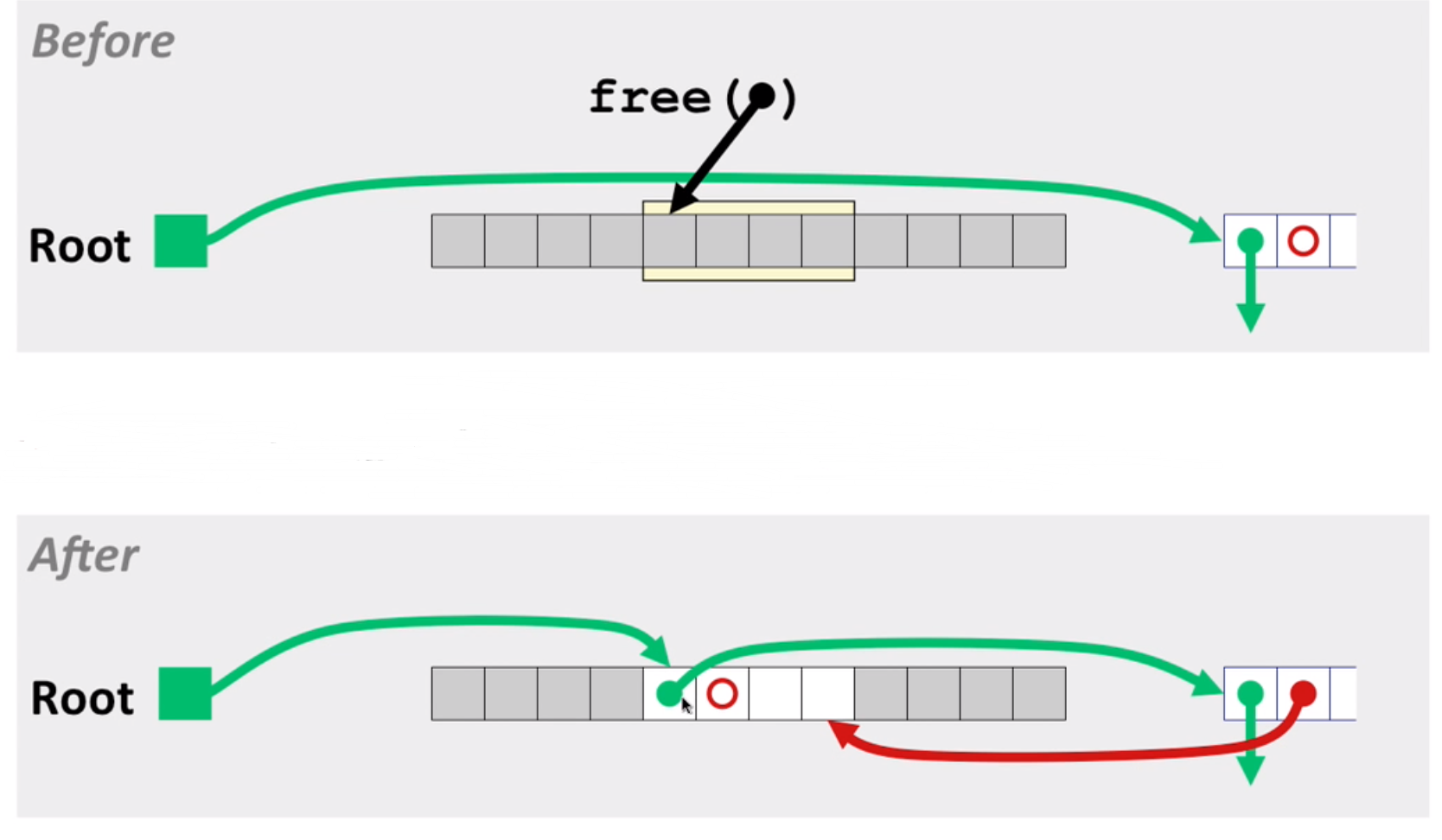
LIFO eg2: with coalesce(remember to use boundary tag)
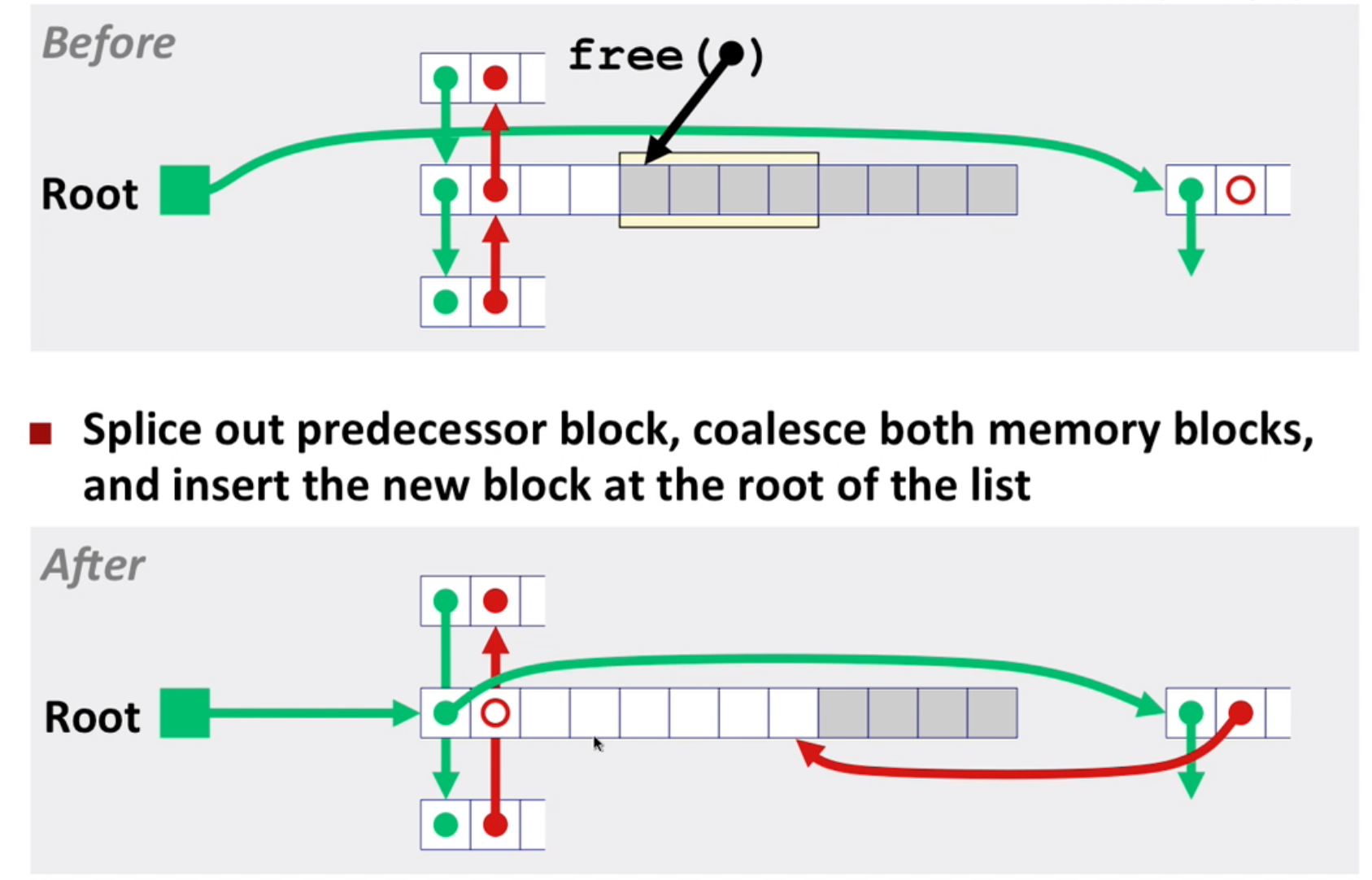
LIFO eg3: with coalesce
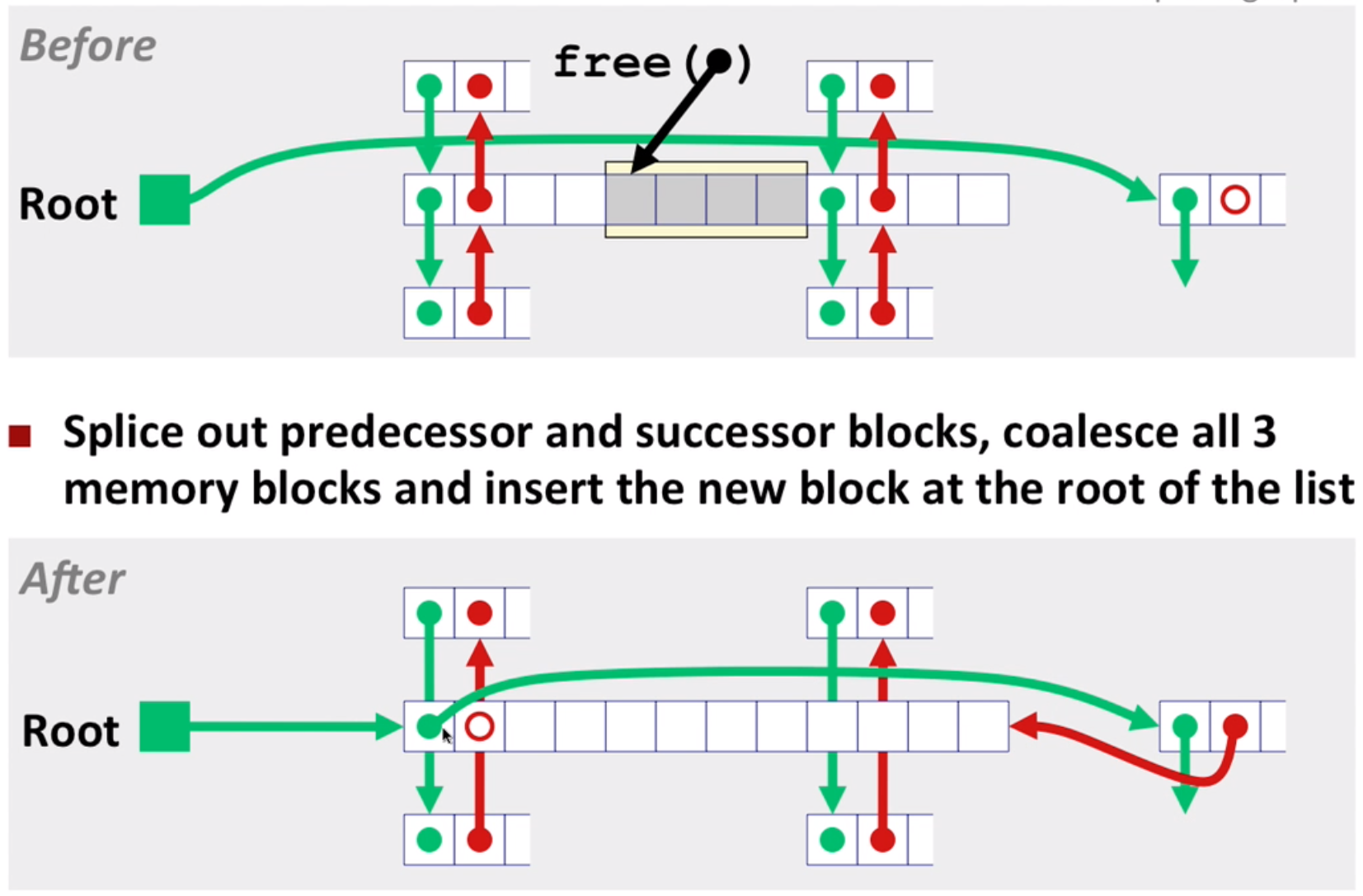
Explicit list only care for free blocks instead of all blocks, much faster when memory is nearly full.
11.4 Segregated free lists
Each size class of blocks has its own free list.
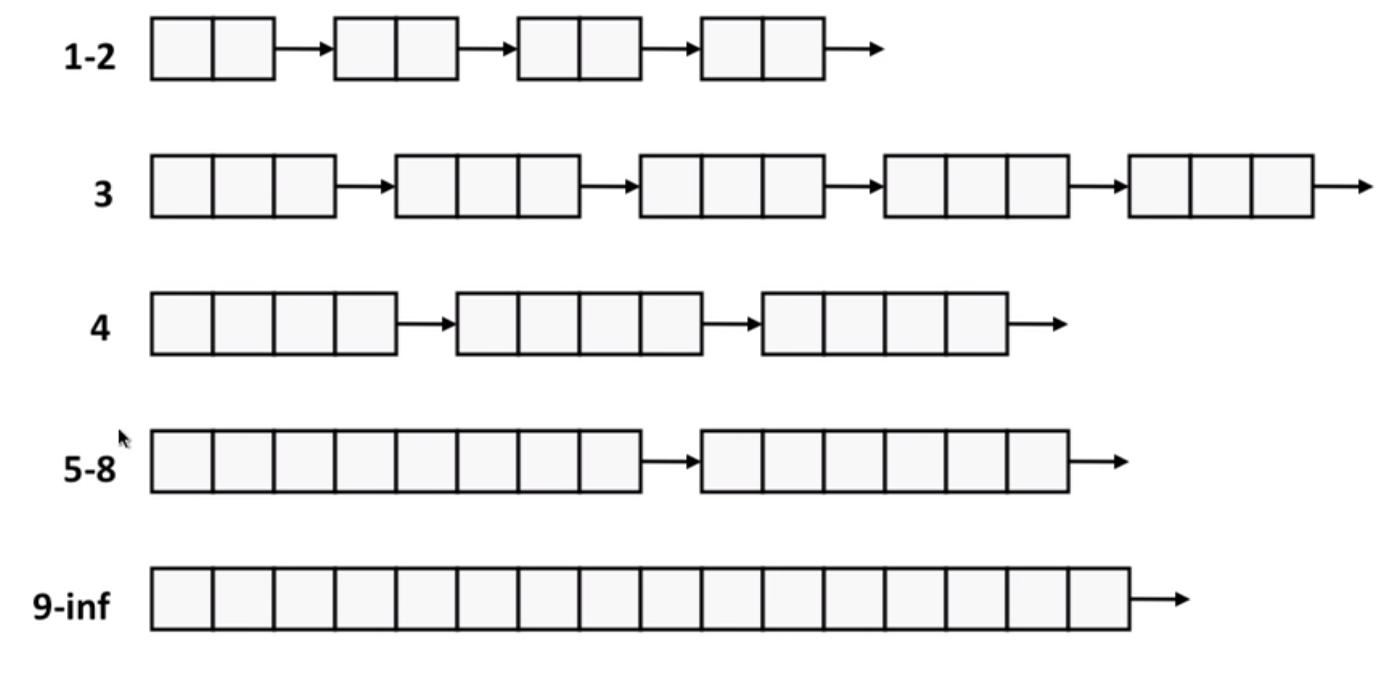
separate classes for small size; two-power size class for larger sizes.
- Higher throughput(log time for power-of-two size classes)
- Better memory utilization: approximates a best-fit search.
11.5 Garbage collection
Automatic garbage collection: application never has to free.
Classical GC algorithms
- Mark-and-sweep collection: introduce later
- Reference-counting: reference count to indicate whether an object can be freed.
- Copying collection: copy all of used object in A to B, then free A. Not used too much
- Generational Collectors: based on lifetimes
Mark-and-sweep:
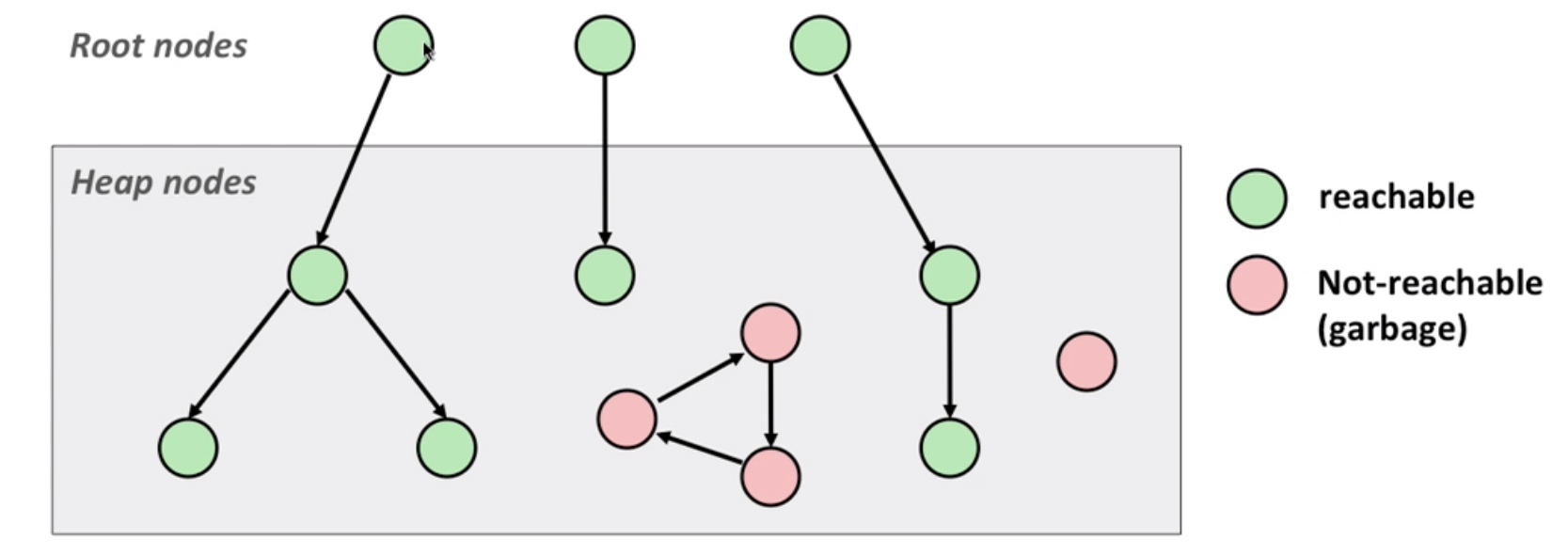
root: Locations not in the heap and contain pointers into the heap(e.g. registers, global variables) reachable: a path from root to node. garbage: non-reachable node.
When out of space:
- Mark: start at roots and set mark(extra mark bit) on reachable node recursively.
- Sweep: scan all blocks and free blocks that are not marked
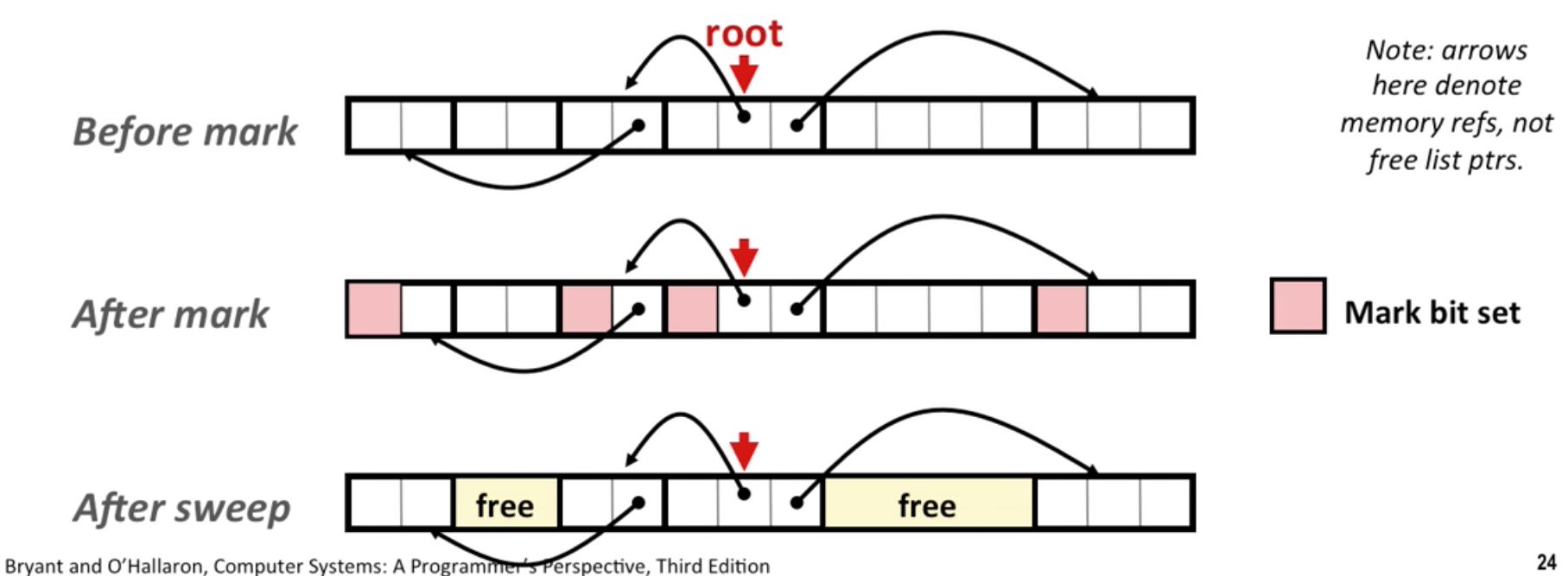
Note: mark-and-sweep in C is conservative, you don’t know a large number is a pointer or a long type. So we can use a balanced tree to keep track of all allocated blocks.
11.6 Recitation
Malloc Lab is out!
Using gprof is a good way to analyze efficiency.