CSAPP Class Notes(2)
5. Program Optimization
Generally Useful Optimizations
- Code motion/pre-computation
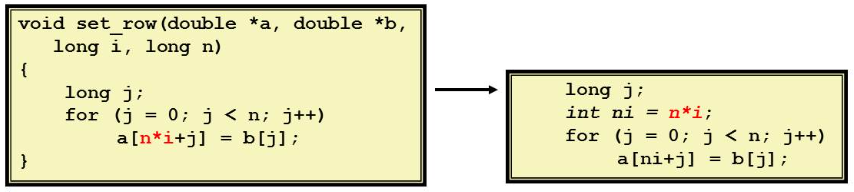
- strength reduction
Core: replace costly operation with simpler one (eg. 16 * x -> x «4)
- sharing of common sub-expressions
eg: f = func(param), then use f directly, instead of a = func(param) + 2, b = func(param)*3 ...
- removing unnecessary procedure calls

Why compiler doesn’t optimize this? Remember compiler always considers the procedure as black box. (It doesn’t know whether the procedure will change the pointer or global variable, etc.)
Note: in python, len(str) is a O(1) func, so it doesn’t really matter.
- Remove memory accessing

As you can see the b[i] has to read from memory each time
It’s better using a local variable to cal the sum
Why compiler can’t optimize it? Memory Aliasing

Exploiting instruction-level parallelism
CPE (cycles per element (OP like
add) )modern cpu design
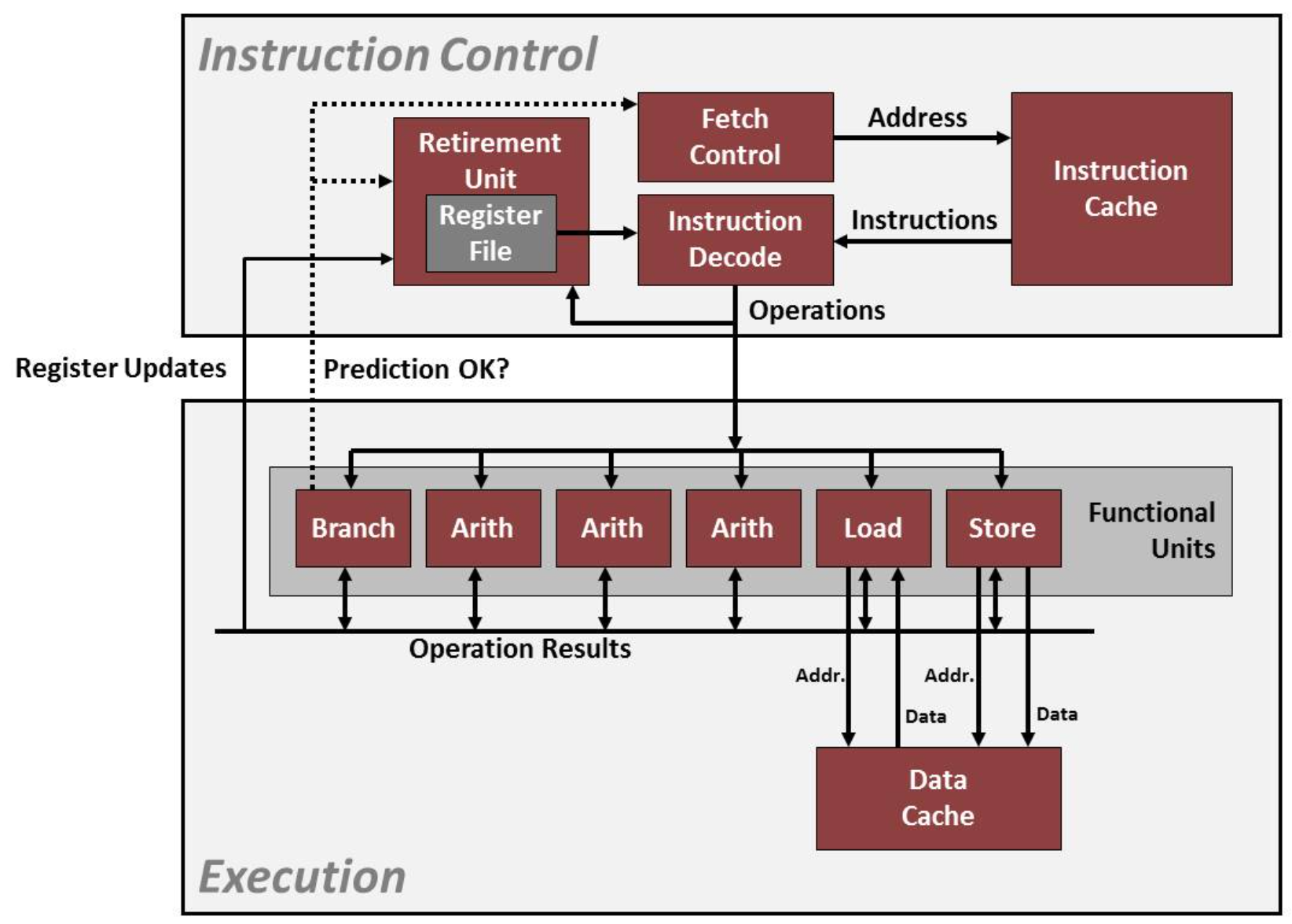
- ideas of pipeline
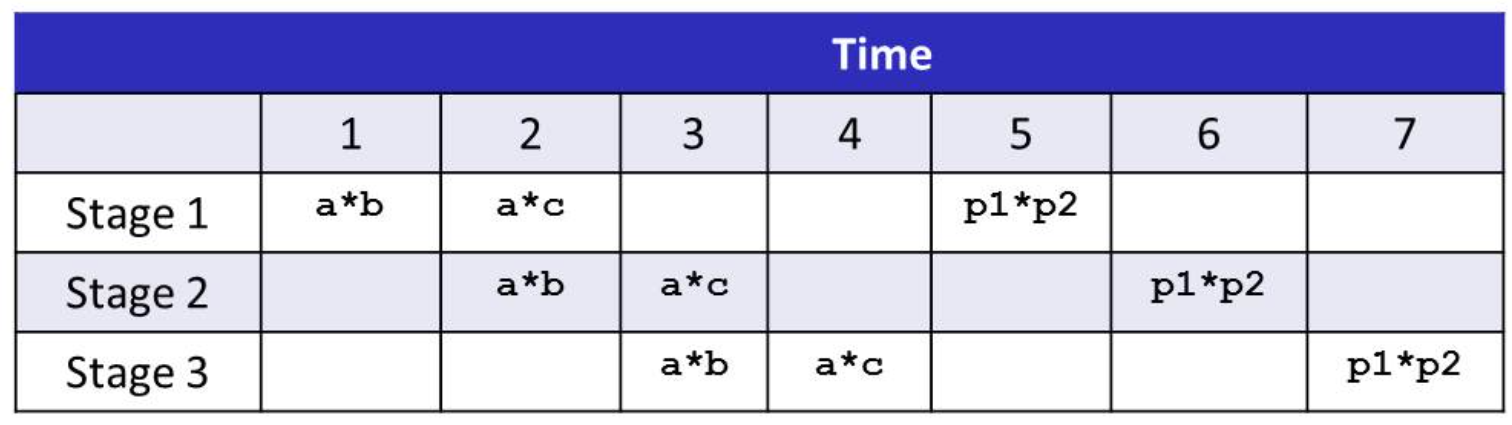
(p1 = a*b, dependency)
- Loop Unrolling
For making use of multi-core processor
for (i = 0; i < limit; i += 2){
// x = x + array[i] + array[i+1];
x = x + (array[i] + array[i+1]); // can break the sequential dependency
// another idea
// x0 = x0 + array[i];
// x1 = x1 + array[i+1];
}Note: Not always useful, based on the processor
- SIMD operations
Based on wide registers:
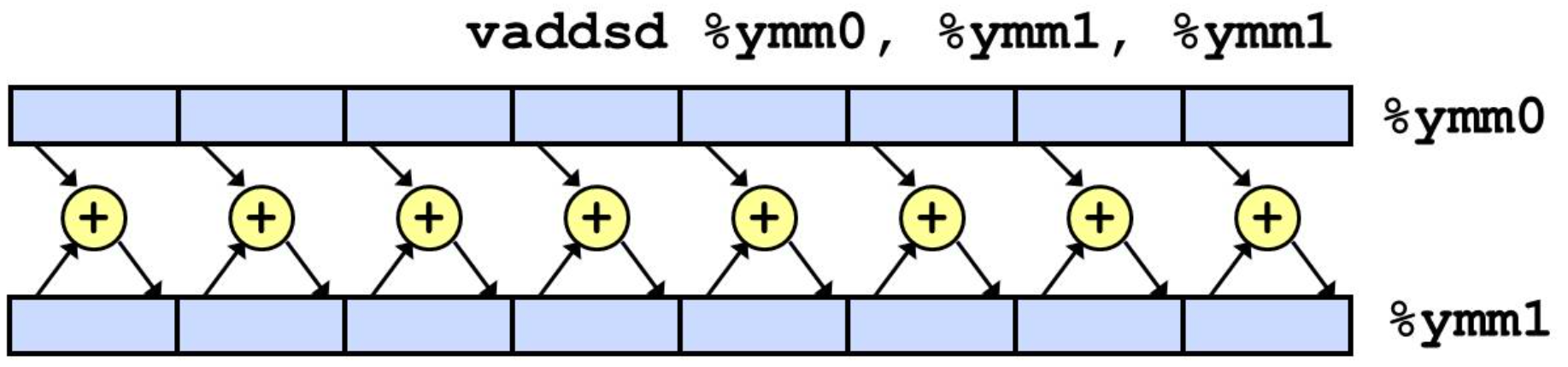
Also called AVX instructions
Dealing with Conditionals
In order to making instructions run smoothly. We introduce the branch predict
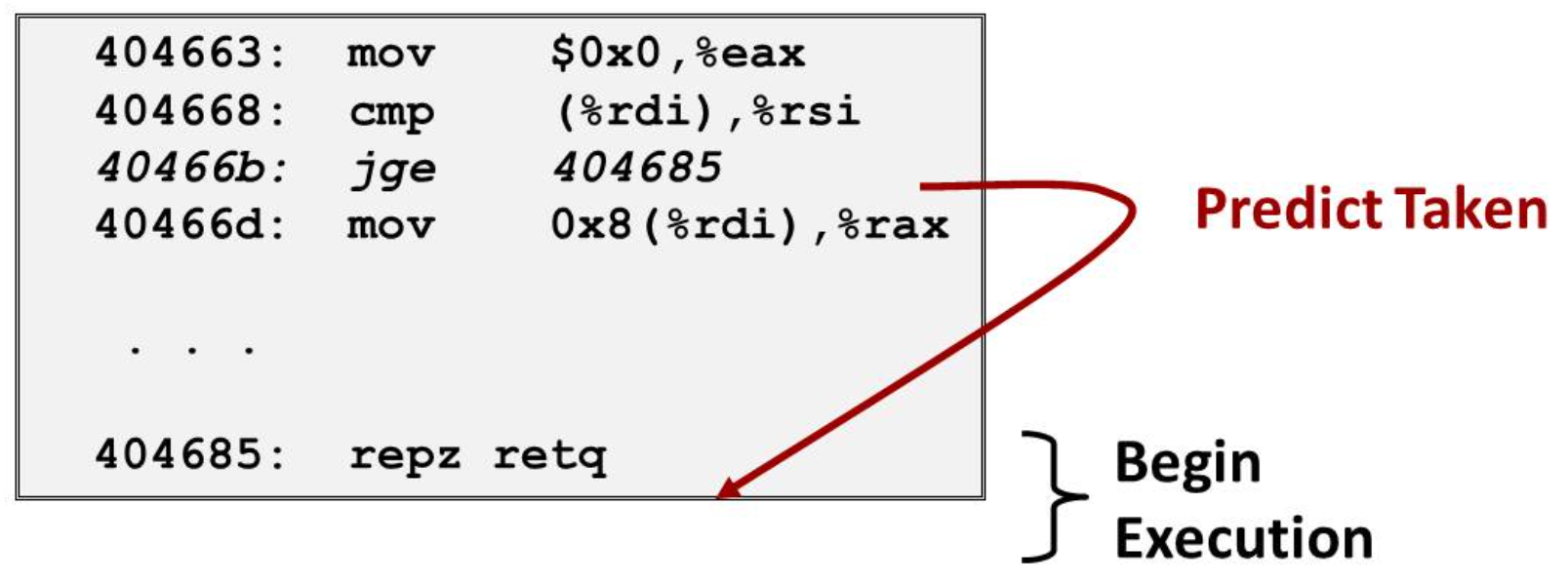
- Simply guess the branch to go
- Begin executing instructions at predicted position
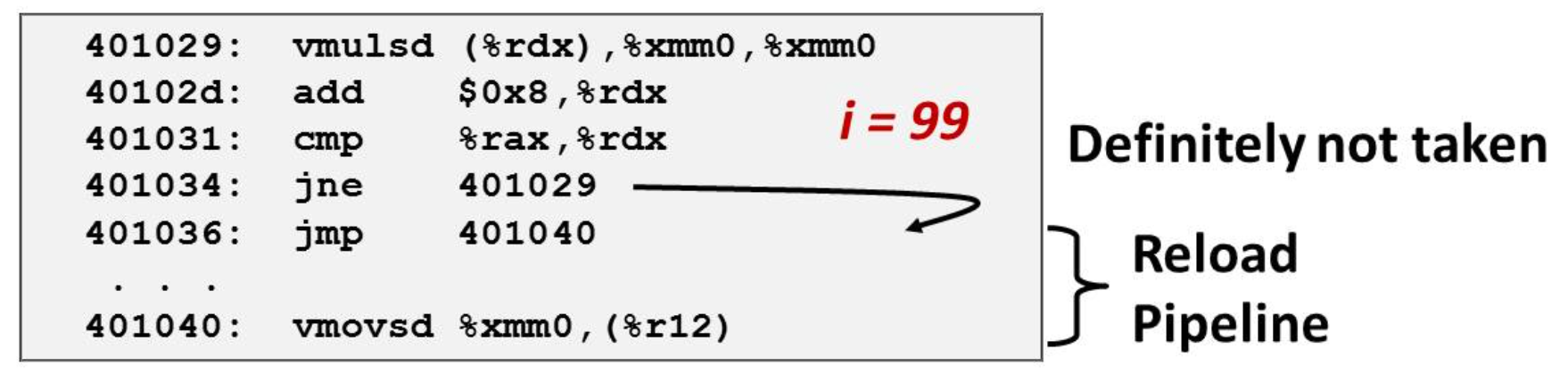
- It can recover when mis-prediction, causing huge performance cost
C Review
- Be careful when
unsigned u > -1:-1is the biggest when unsigned - Initialize array with exact value
- Remember there is a
\0at the end of string - When
sizeof(xx), make sure xx is not a pointer - Remember to
freeaftermalloc - Don’t return a pointer pointing at a local variable
int *a;whena + 1, address of a actually addsizeof(int) * 1 = 4
6. Memory
Storage technologies and trends
Random-Access Memory(RAM)
- SRAM(static, expensive, cache, volatile: lose information when power off)
- DRAM(dynamic, main memory, volatile)
Read-only memory(ROM)
- nonvolatile: keep information when power off
- BIOS, firmware programs saved in ROM
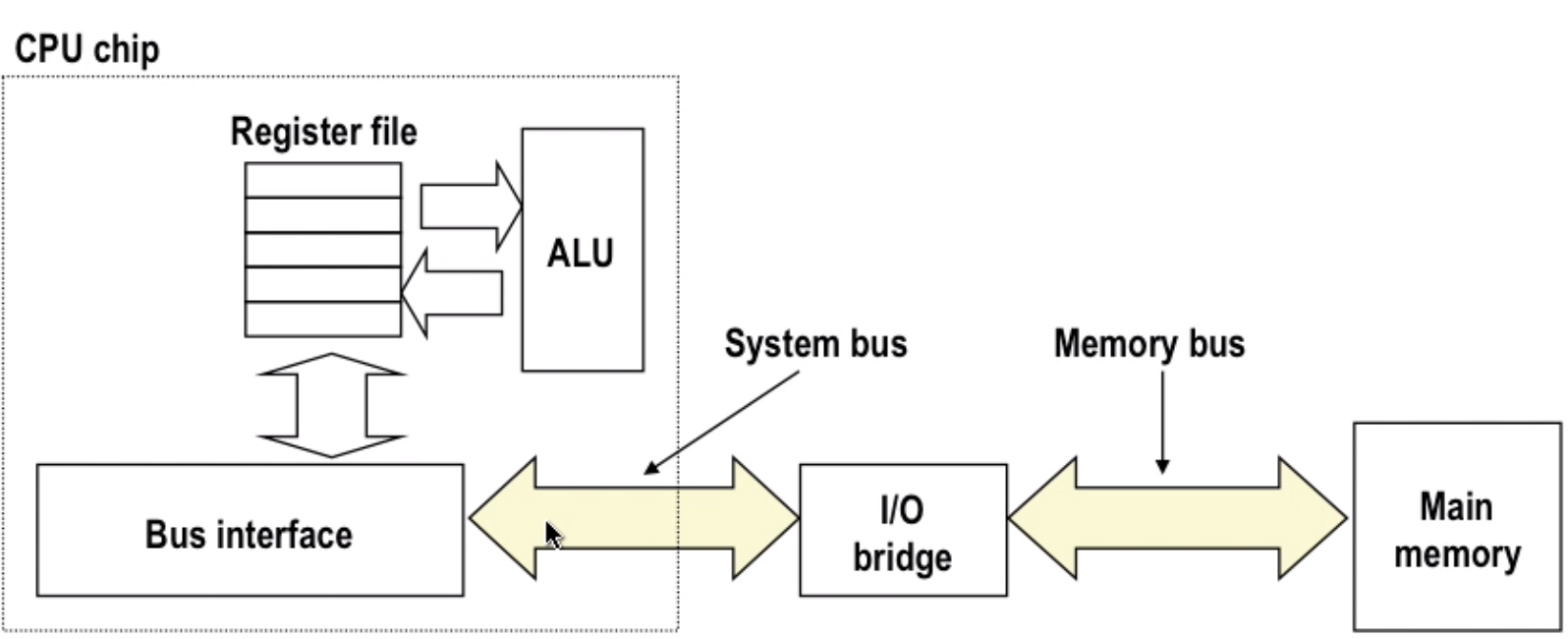
Bus(collection of parallel wires) structure
- Disk
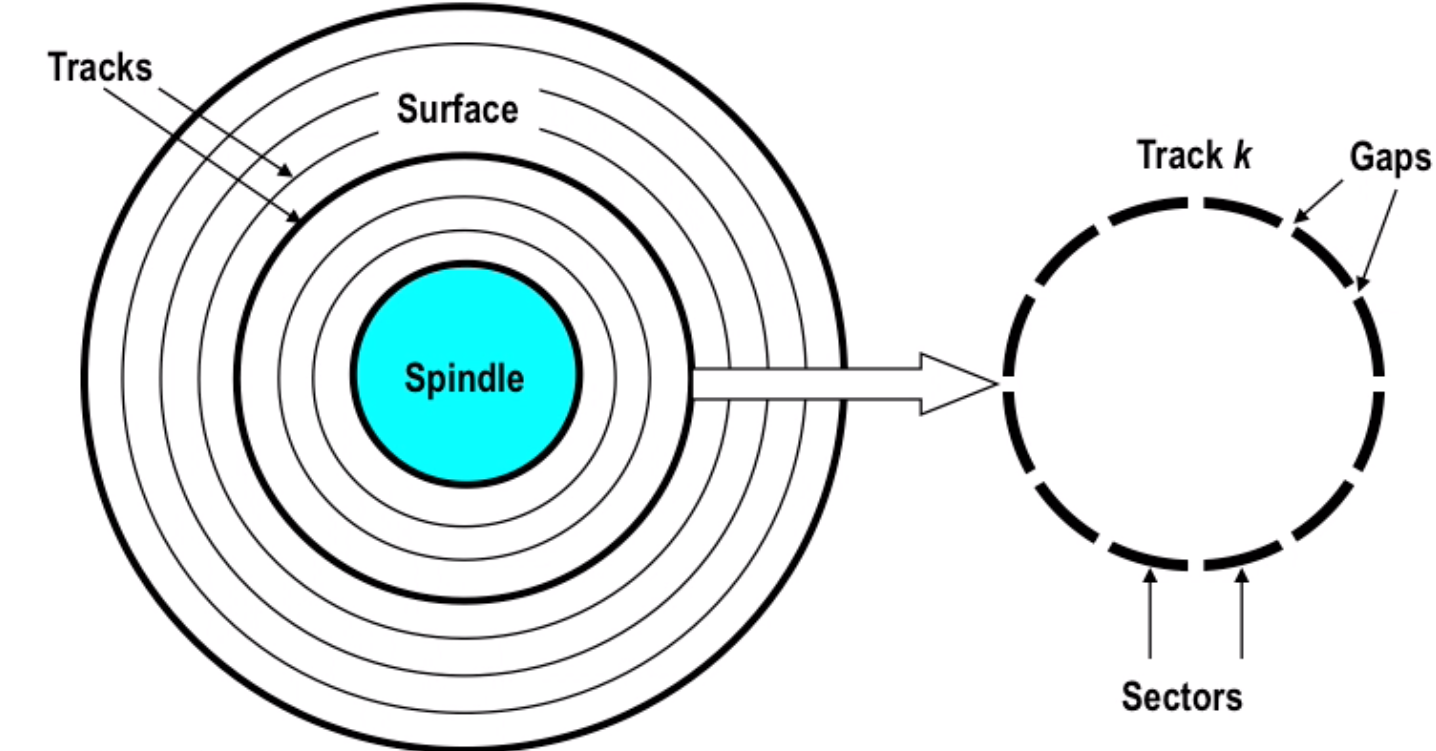
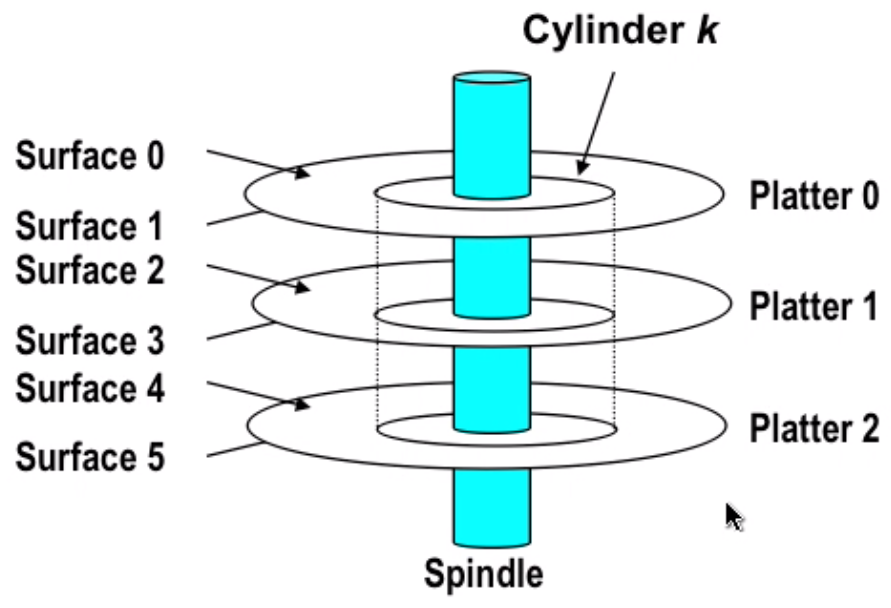
capacity: 512 bytes/sector * 300 sectors/track(on average) * 20000 tracks/surface * 2 surfaces/platter * 5 platters/ disk = 30.72GB
disk access:
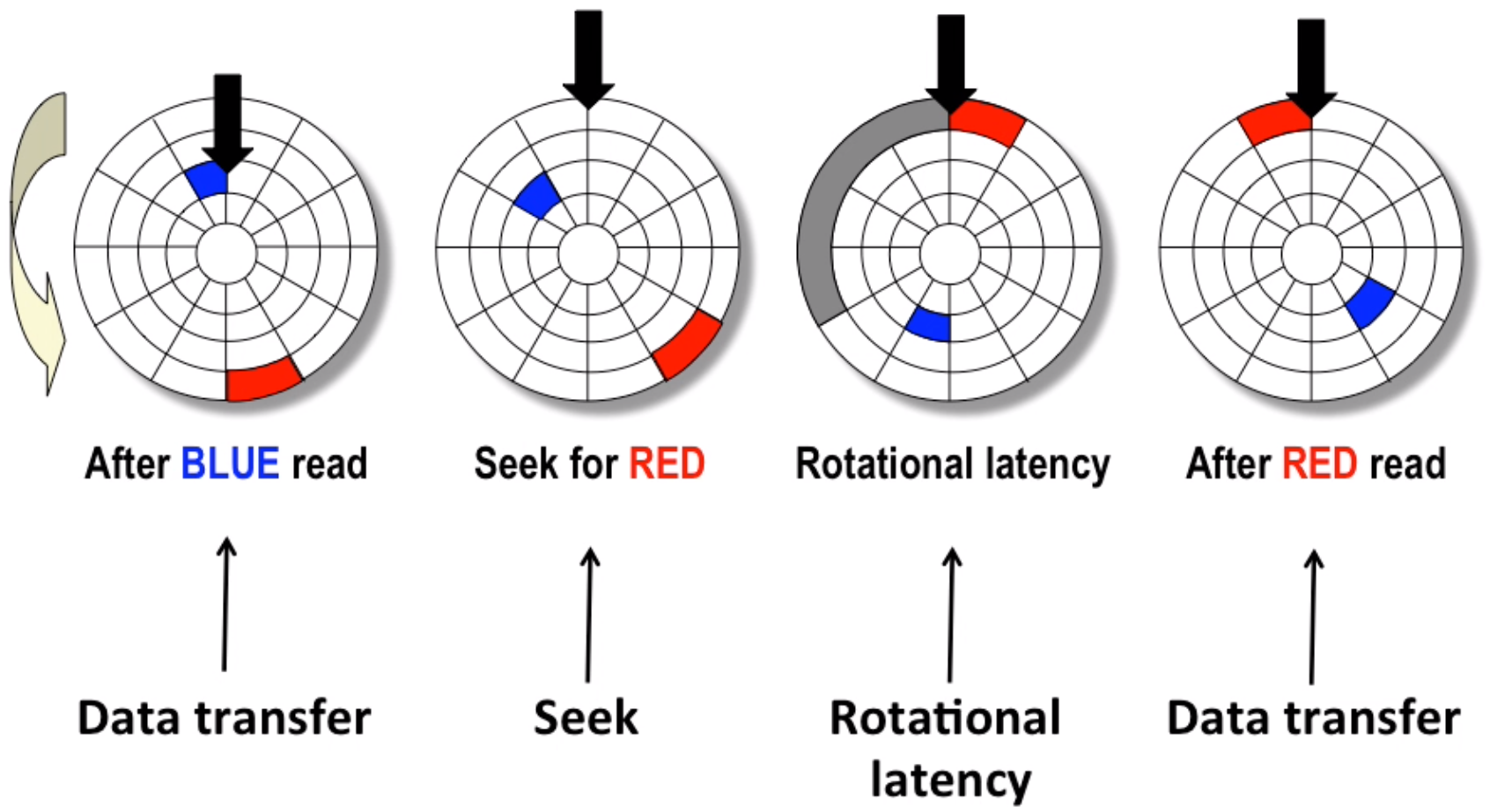
Normally disk access time = seek time(4~9ms) + rotation(2~5ms) + transfer(0.02ms), much slower than RAM(ns)
- Bus structure expand
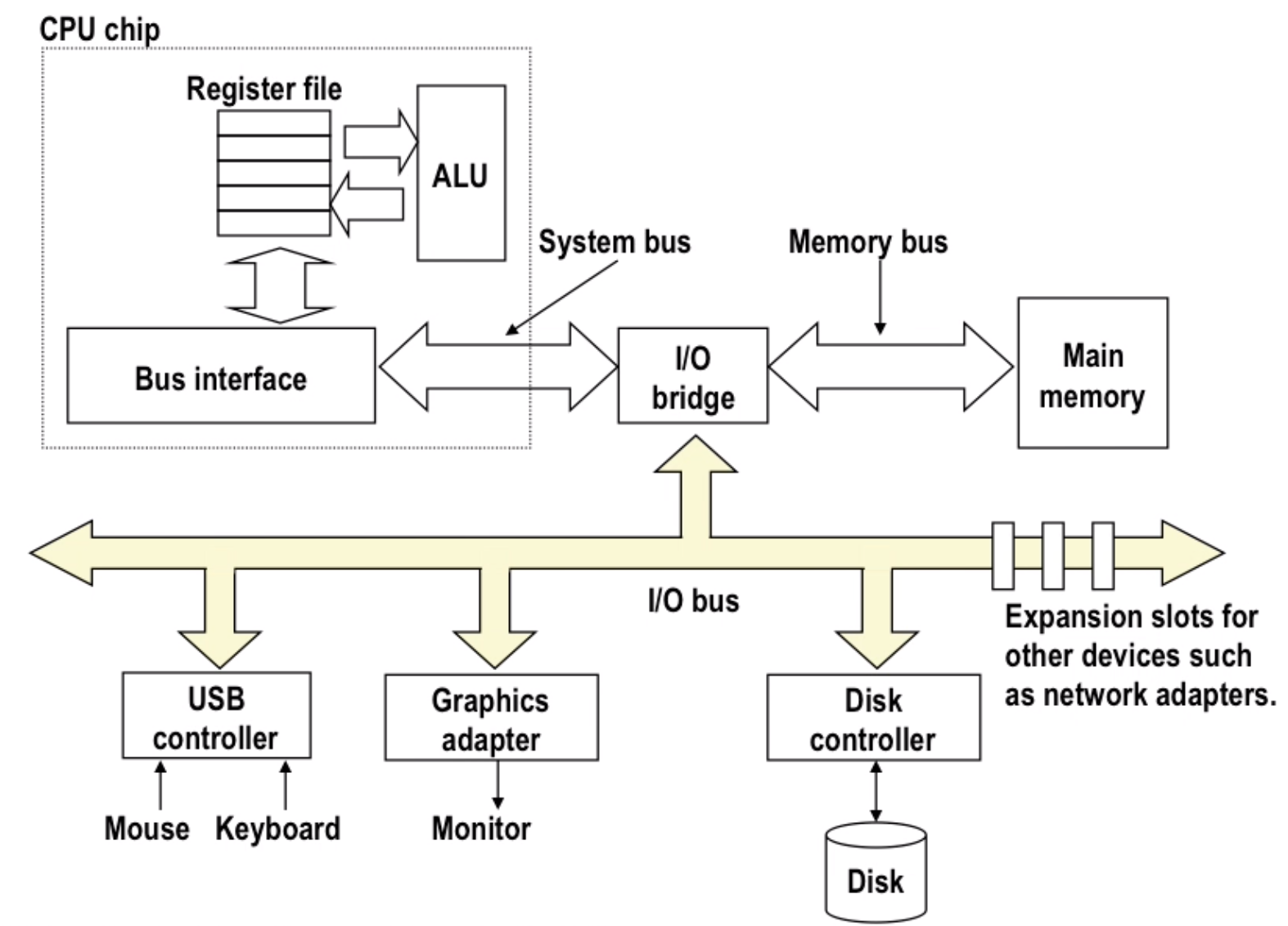
Note: this is not the modern design, which use point to point connection instead of a public wire
interrupt: cpu never waits for disk, when data is carried from disk to memory, it will notify cpu and let cpu continue to work on that data.
solid state disk(ssd): much faster than normal disk
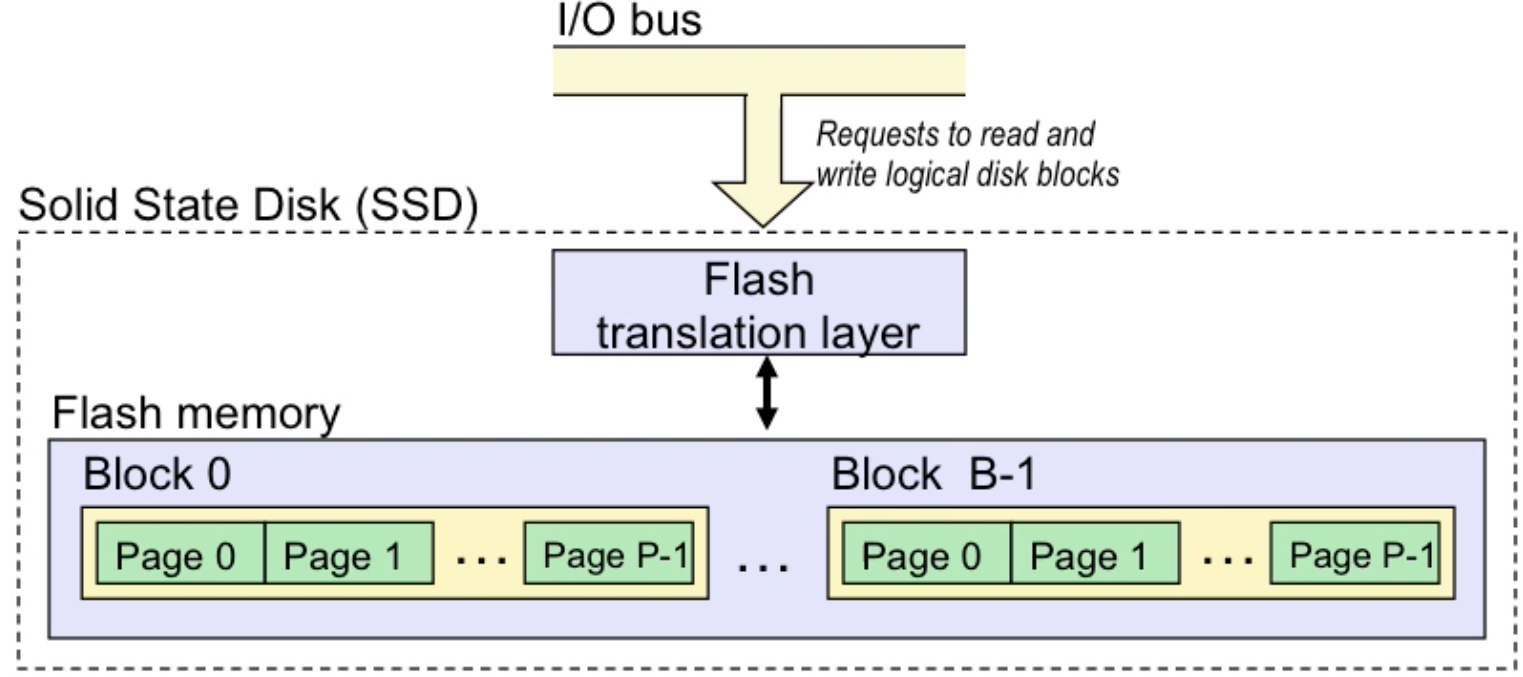
- cpu-memory-gap
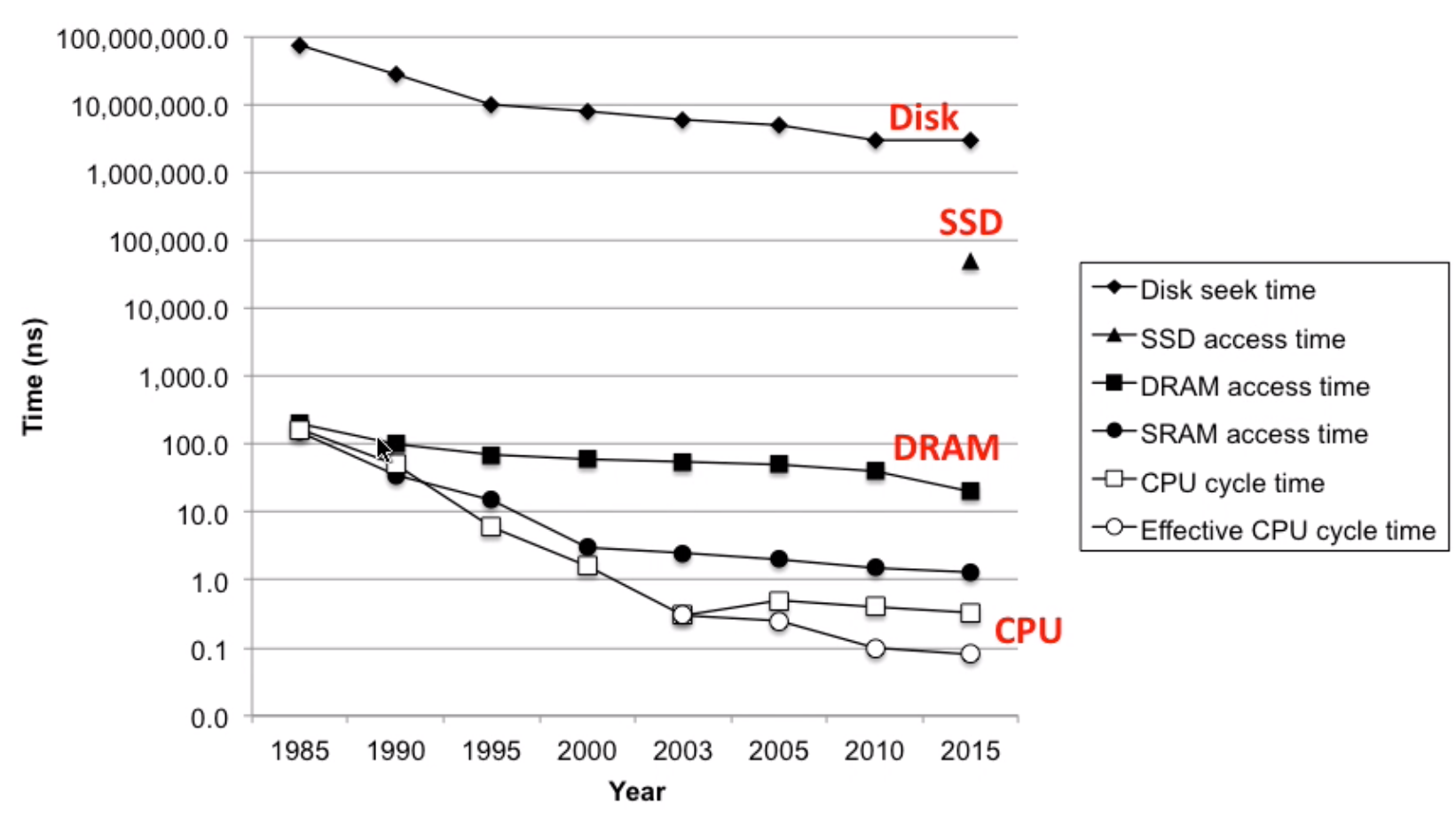
Locality of reference
- principle programs tend to use data and instructions with addresses near or equal to those they have used recently
Caching in memory hierarchy
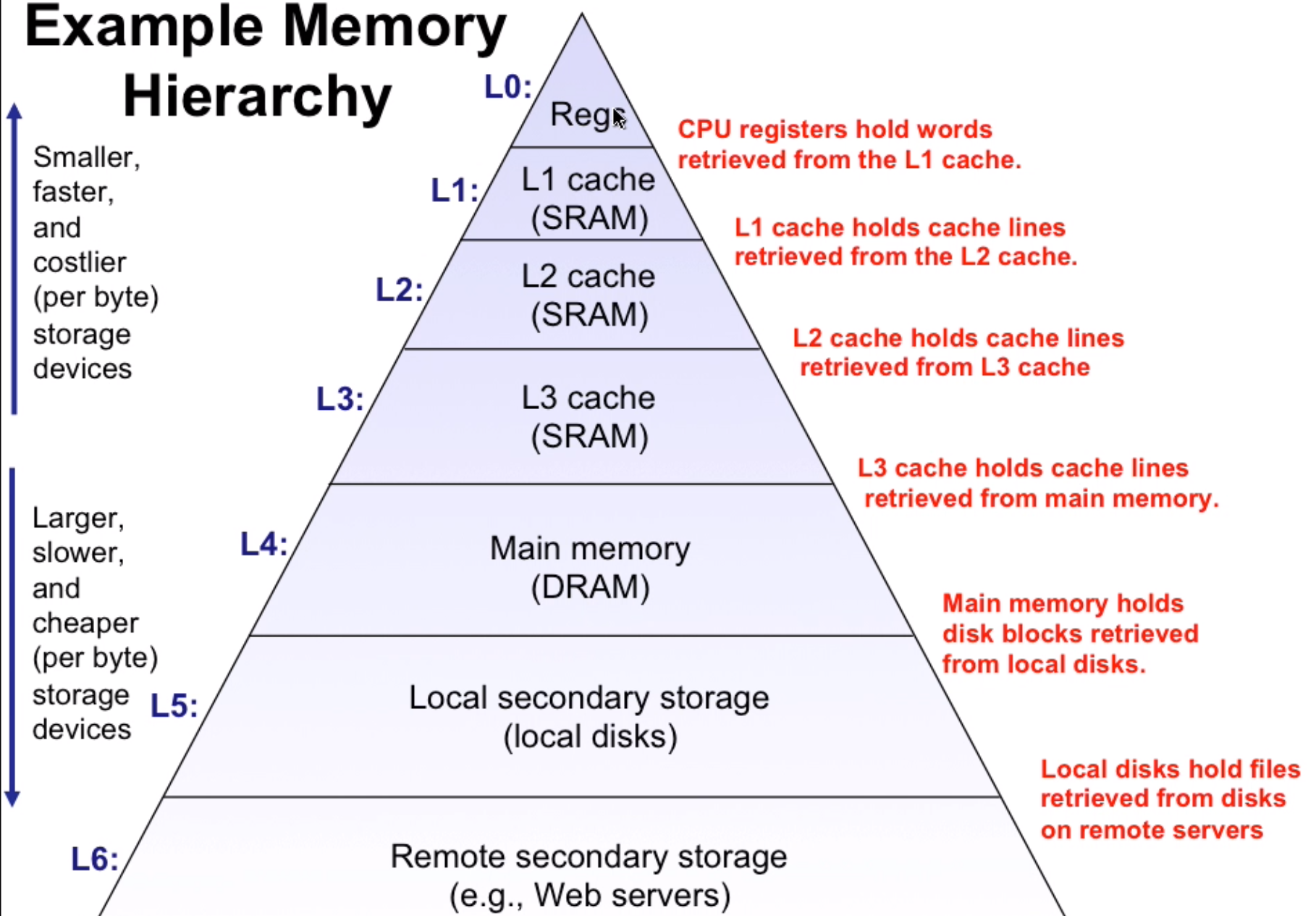
Cache memory organization and operation
- general cache organization
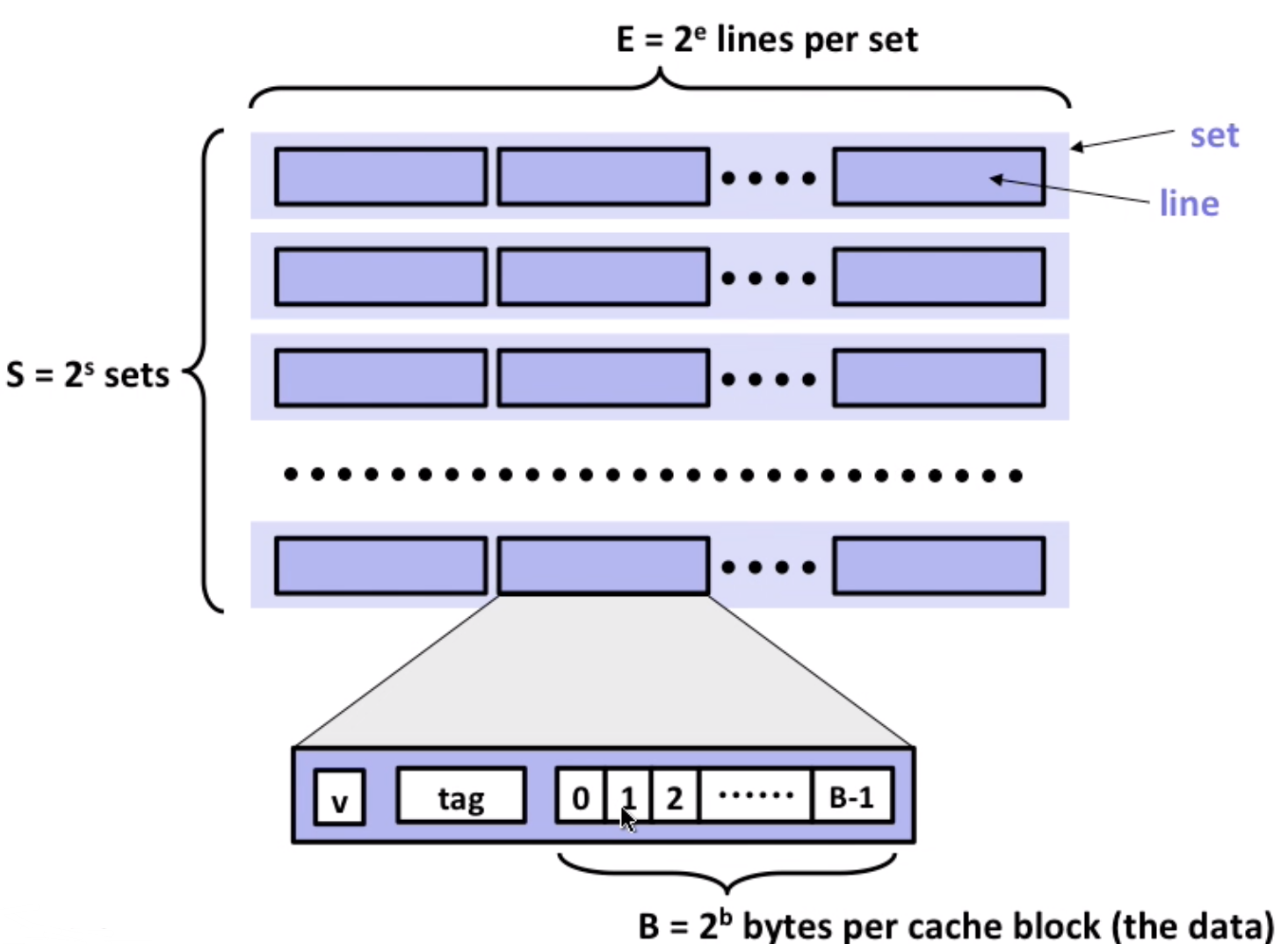
cache_size = S * E * B bytes
- cache read
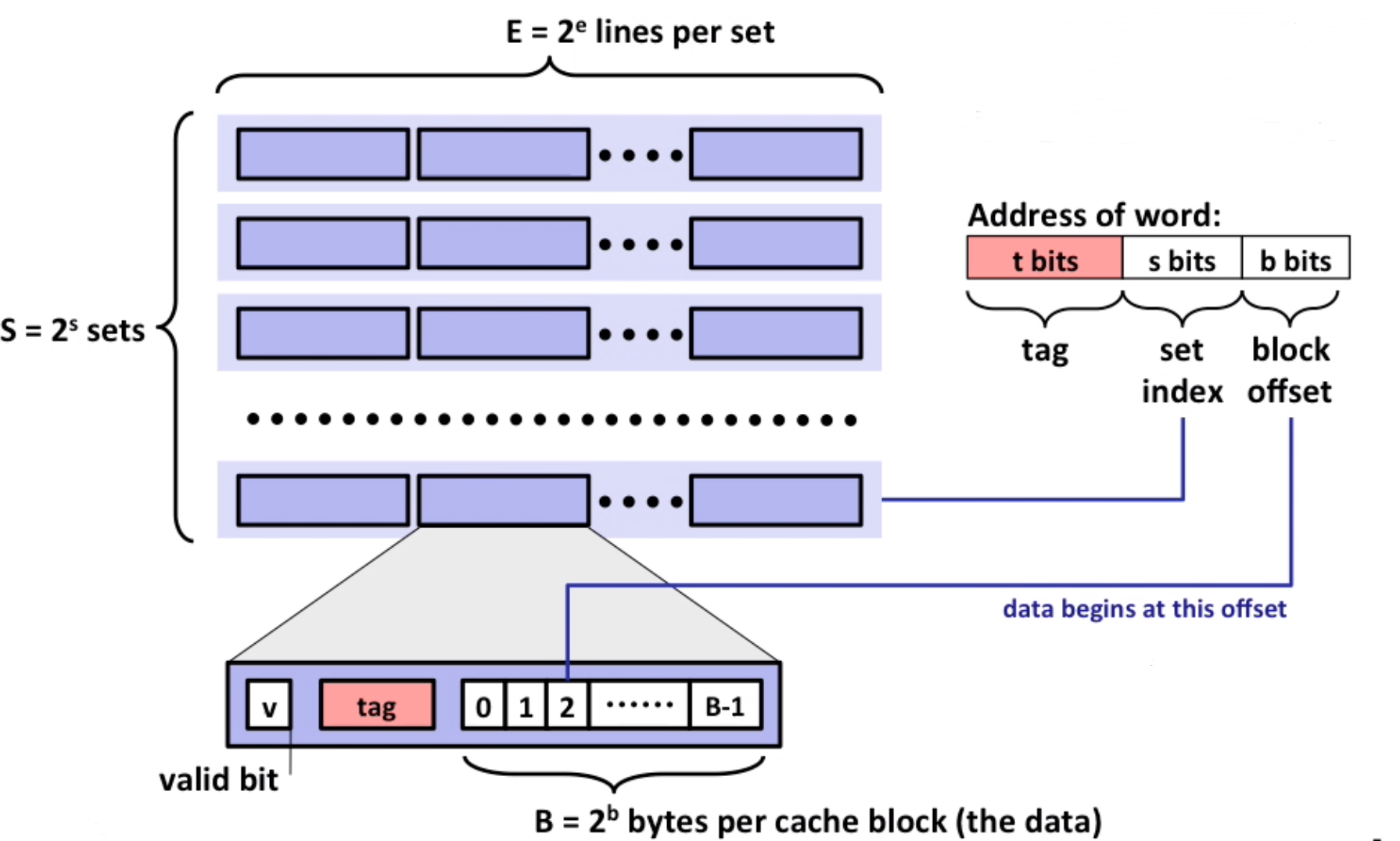
- locate set
- check all lines in set to match tag
- tag matches and valid is true: hit
- locate data by offset
Note: if not match, old line is evicted and replaced
- simple example
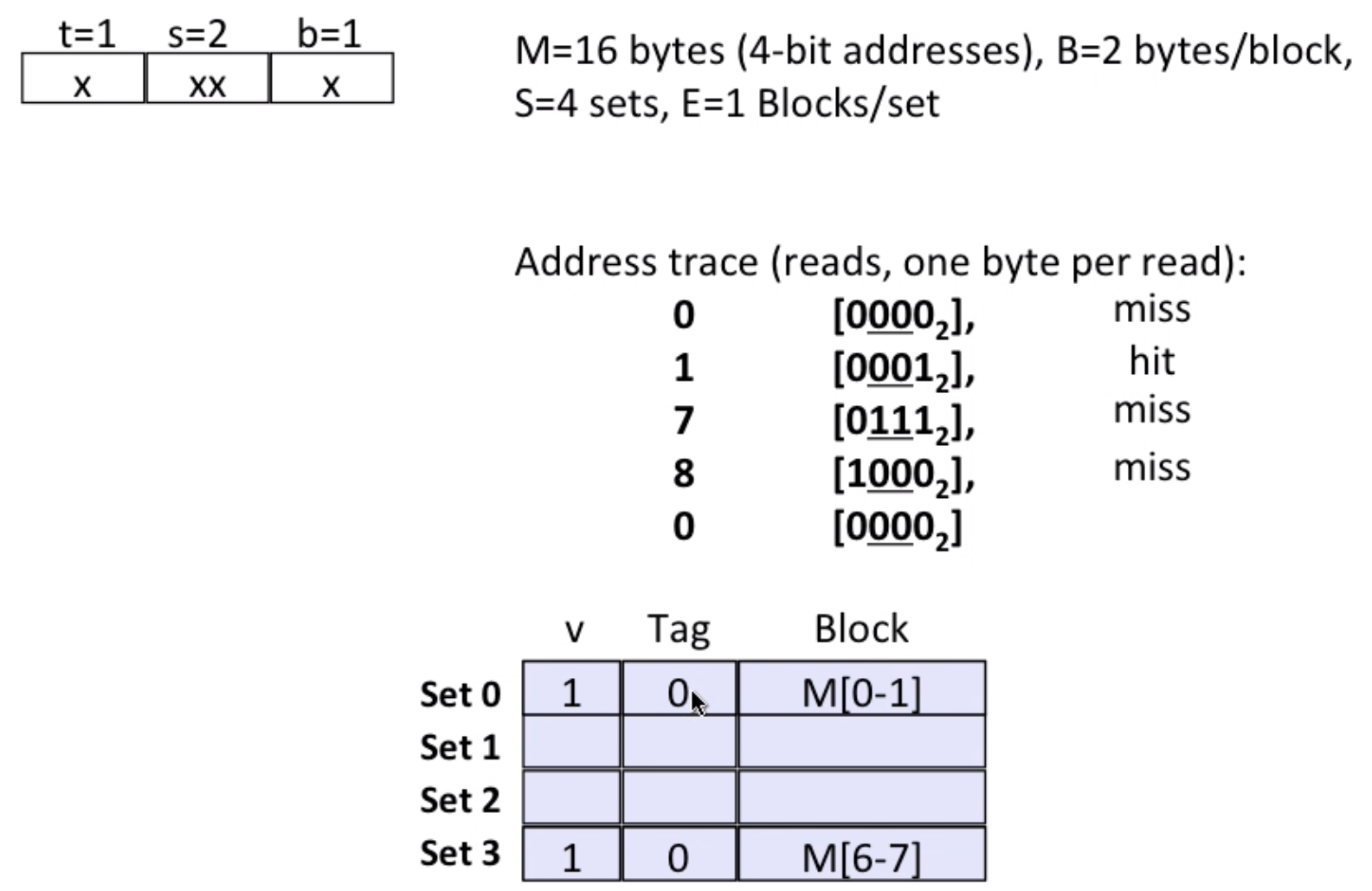
When there comes a 8 [1000], it will miss, and set 0 is evicted

And when there comes a 0 [0000], it will miss again
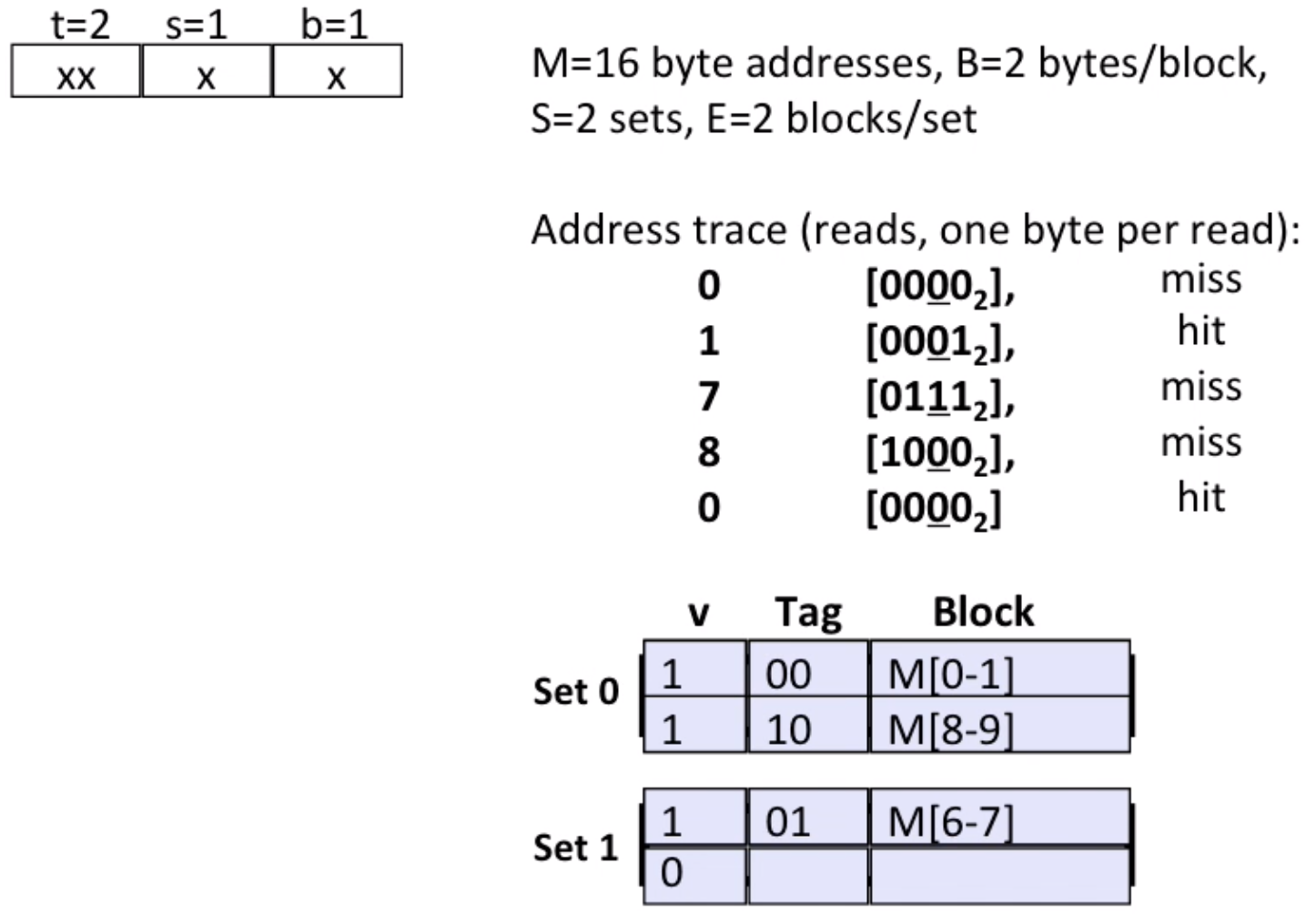
However, if we change the bits of lines(2-way associative), it will change.
block size: hyperparameter of memory system
- if too small: locality principle(easily use nearby bytes) is not used
- if too large: long time to evict memory
cache write
- write-hit
write-through: write data in cache immediately to memorywrite-back: defer write until replacement of line(need a dirty bit in cache)
- write-miss
write-allocate: load into cache first(good if more writes to the location follow. Note: a block in cache is large)no-write-allocate: write straight to memory
- a good model:
write-back+write-allocate
- write-hit
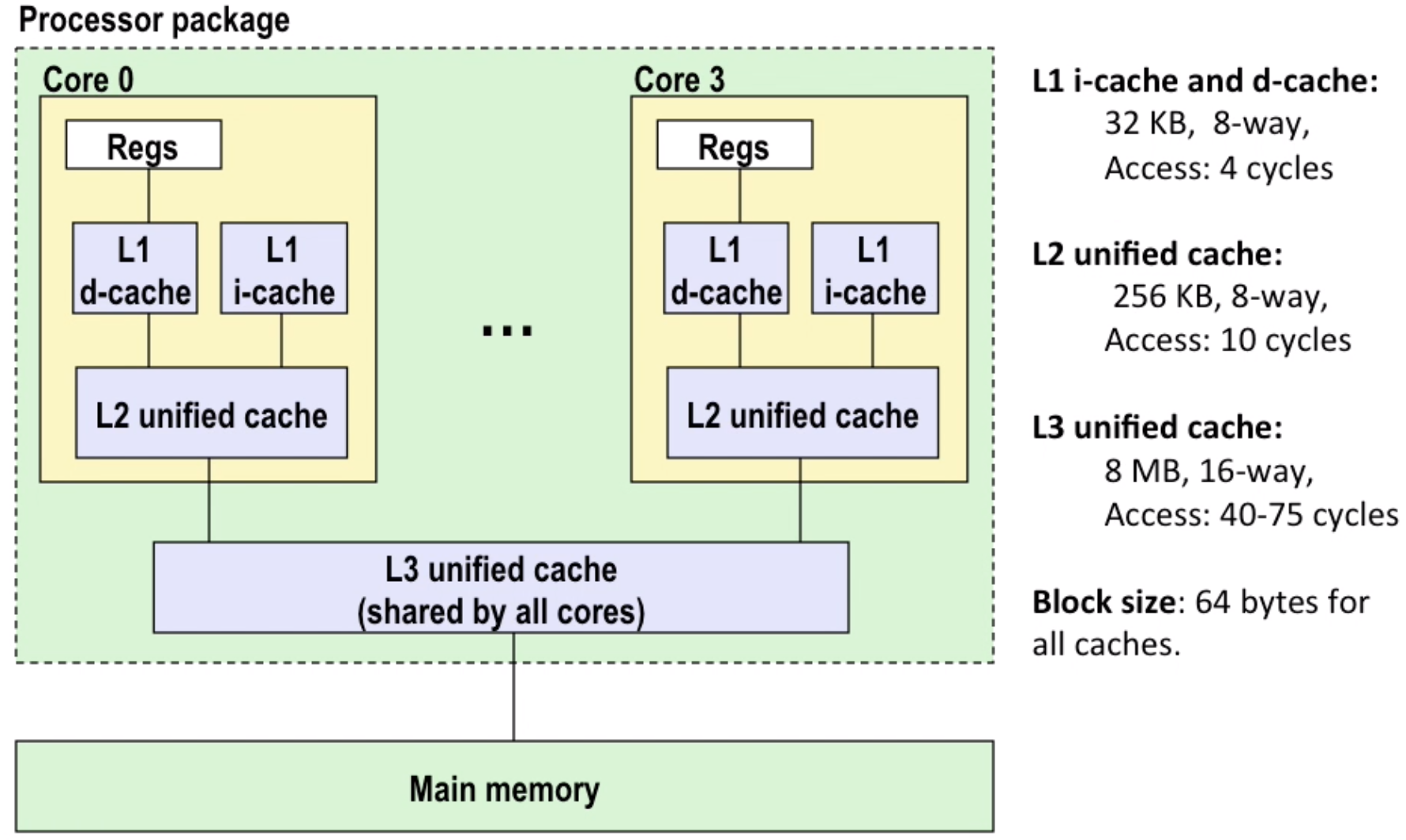
intel core i7 cache hierarchy:
Performance impact of caches
metrics
miss rate:misses / accesseshit time: how much time used when hit(eg: 4 clock cycles for L1)miss penalty: how much time used when miss(eg: 50~200 cycles to fetch from memory)
memory mountain:
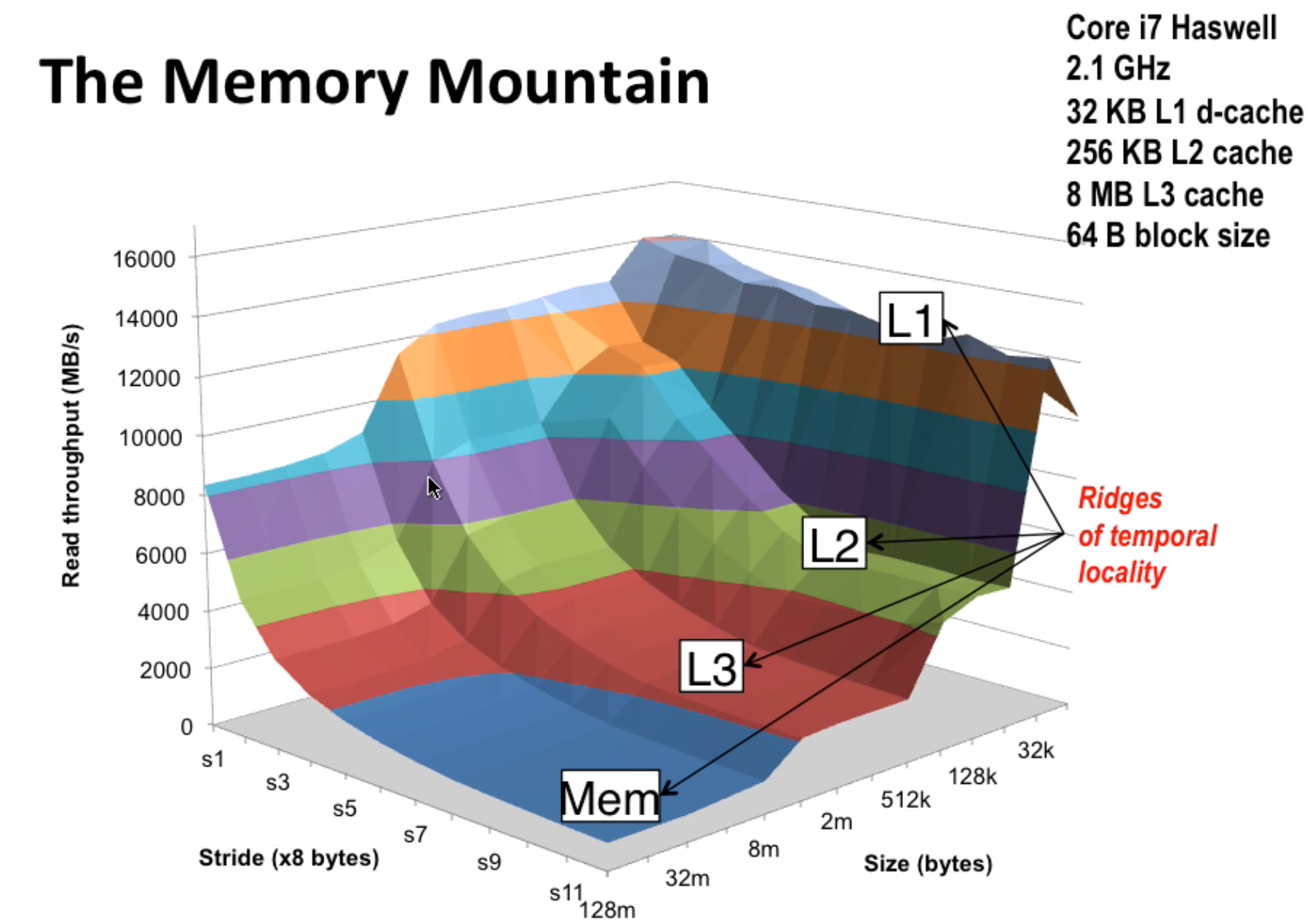
When stride increases(for (int i = 0; i < limit; i += stride)), spatial locality decreases (you are not accessing the data nearby).
When size increases (array to visit is too large), temporal locality decreases (cache can’t hold too much data).
- example: matrix multiplication(considering
block_size = 32Bytes, data type isdoubleso normally it will miss every four iter)
This is a normal pattern(2 loads, 0 stores):
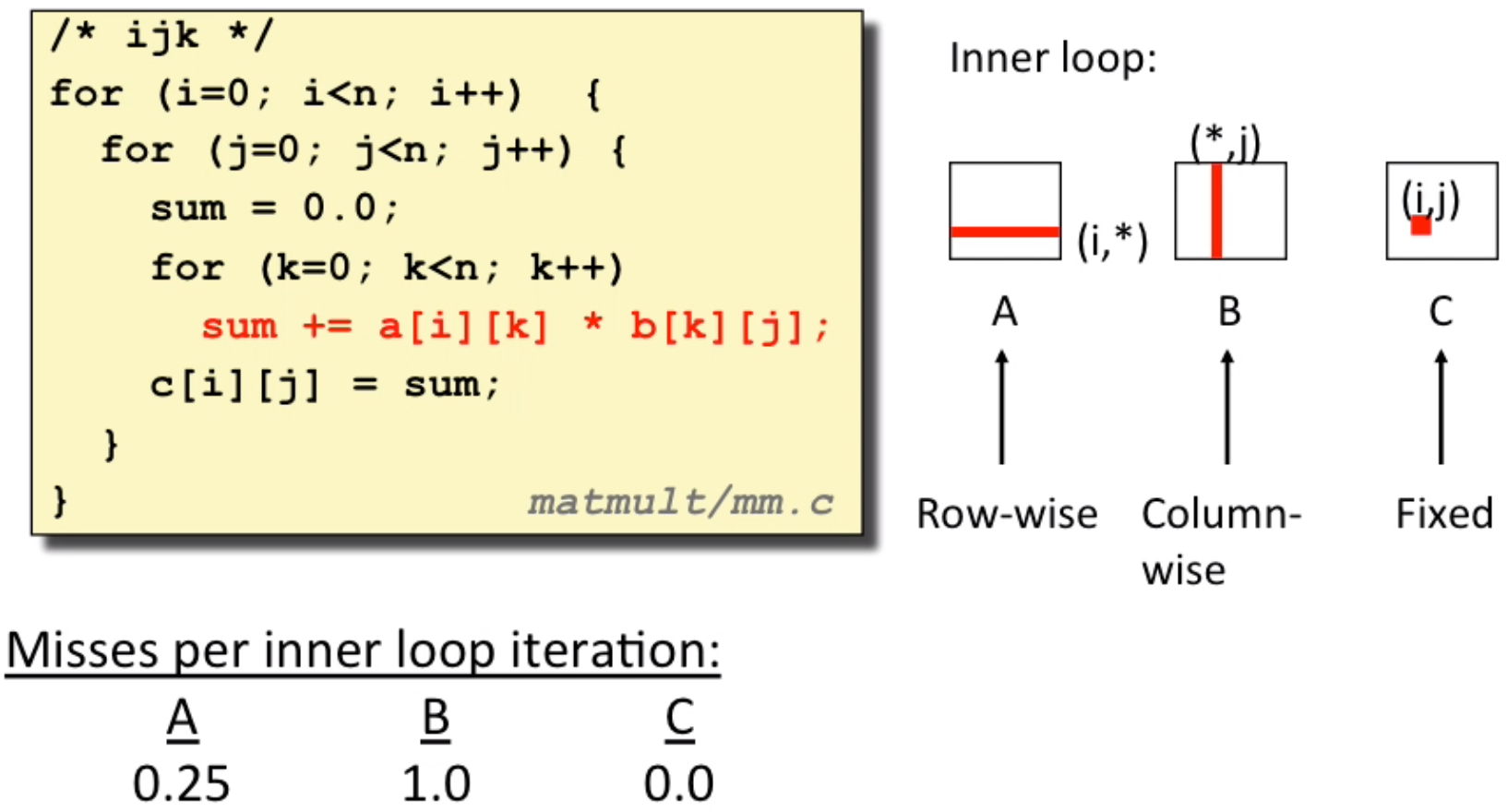
This is another pattern(2 loads, 1 stores):
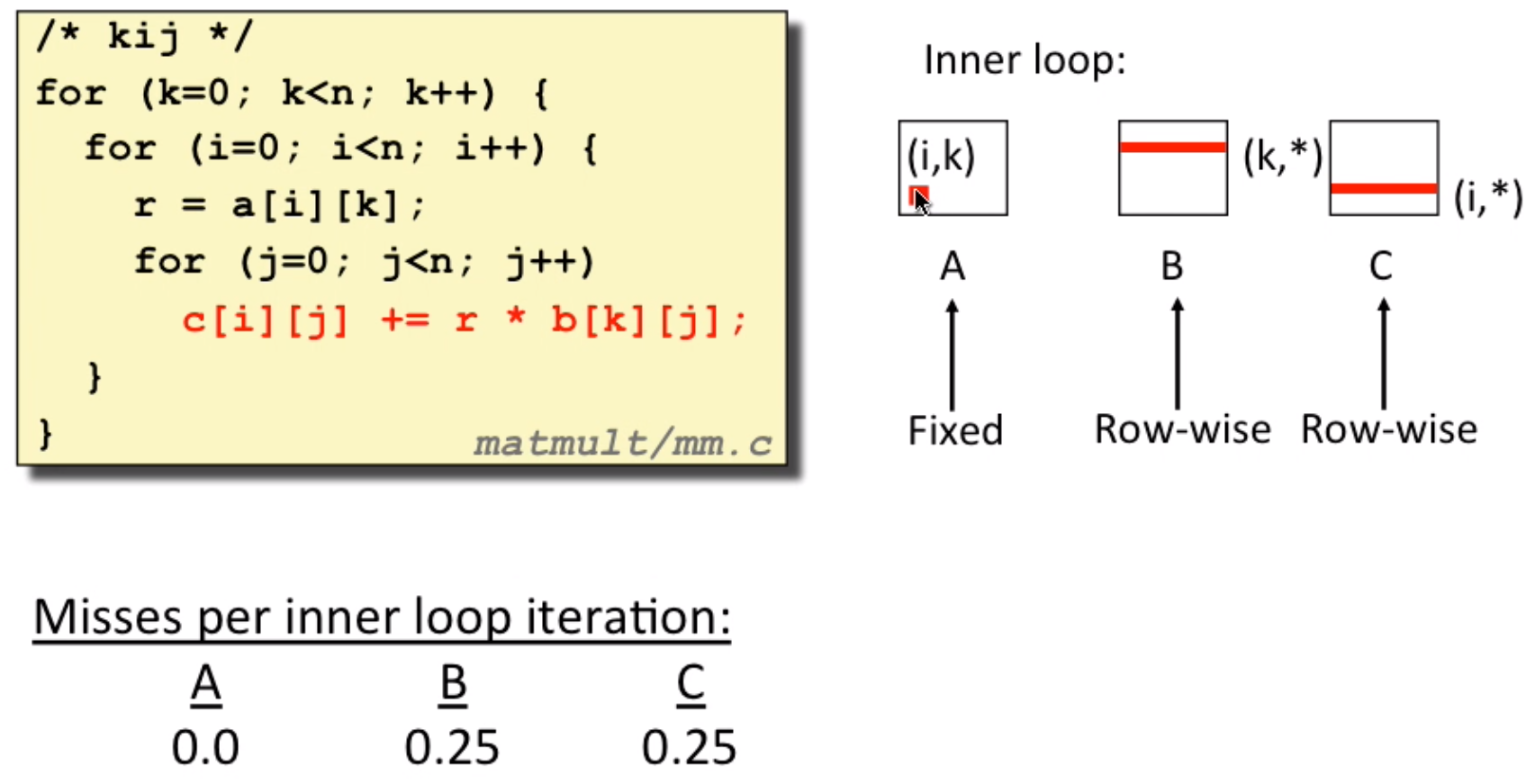
Although 1 stores in pattern 2, it doesn’t matter(because of write-back, it’s more flexible, you don’t have to wait)
- block matrix multiplication: use block to speed up
Warning: maybe useful in efficiency(a little bit), quite useless in real project(non-readable code for your teammates)

A specific example:

We should handle 5&6 next to make use of the cache (A[1][0] miss, A[1][1] hit, B[0][1] hit, B[1][1] hit)
7. Linking
static linking
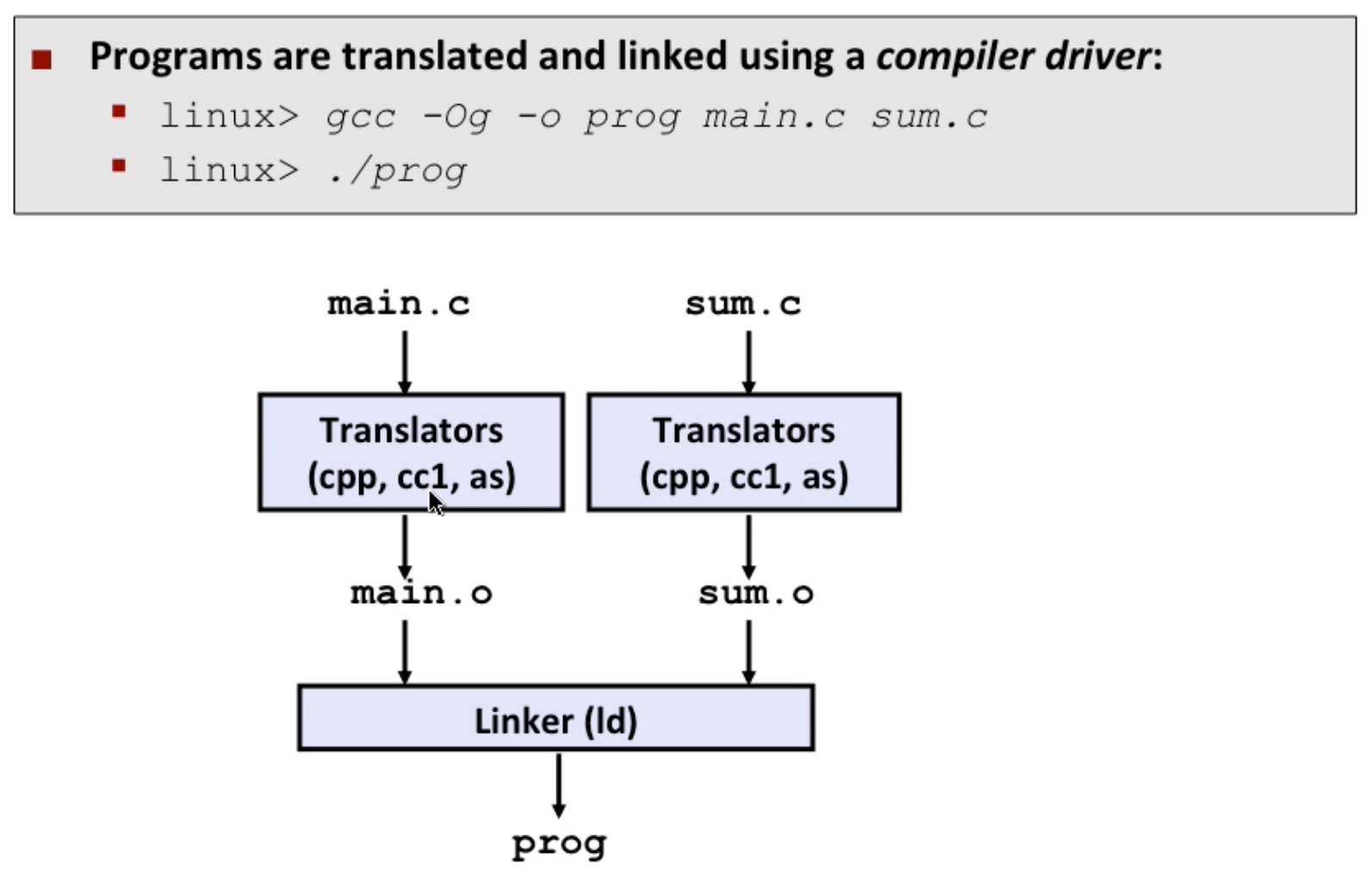
- cpp: c pre processor
- cc1: compiler
- as: assembler as
- Note: separate compile and then put it together
- Modularity: well organized
- Efficiency: just need to compile just some of the content
Three kinds of object files
- relocate object file(
.ofile)- each
.ois exactly from one.cfile
- each
- executable object file(
.outfile) - shared object file(
.sofile)- can be loaded into memory and linked dynamically, at either load time or run-time
- called Dynamic Link Libraries(DLL) by windows
ELF(Executable and Linkable Format)
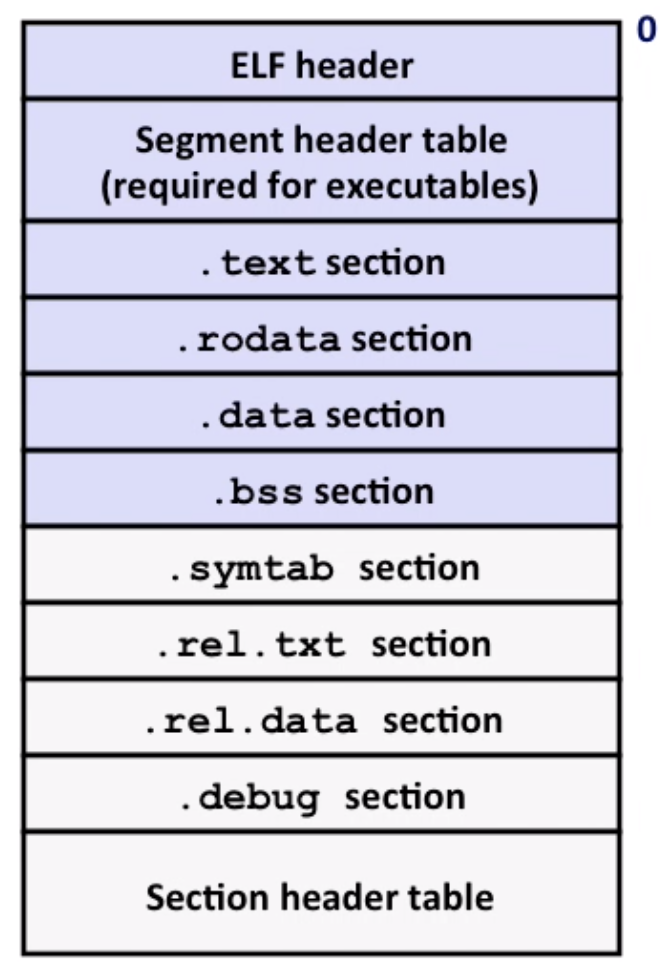
- elf header: word size, byte ordering, file type(
.o,.soetc) - segment header table: page size, virtual address, memory sections, segment sizes.
.text: the code.rodata: read only data(jump tables…).data: initialized global data.bss: uninitialized global data, “better saved space”, occupies no space.symtab: symbol table.rel .text: relocation info for.text, instructions for modifying.rel .data: relocation info for.data.debug: info for symbolic debugging(gcc -g)- Section header table: offsets and sizes of each section
Note: local static variable is stored in .bss or .data
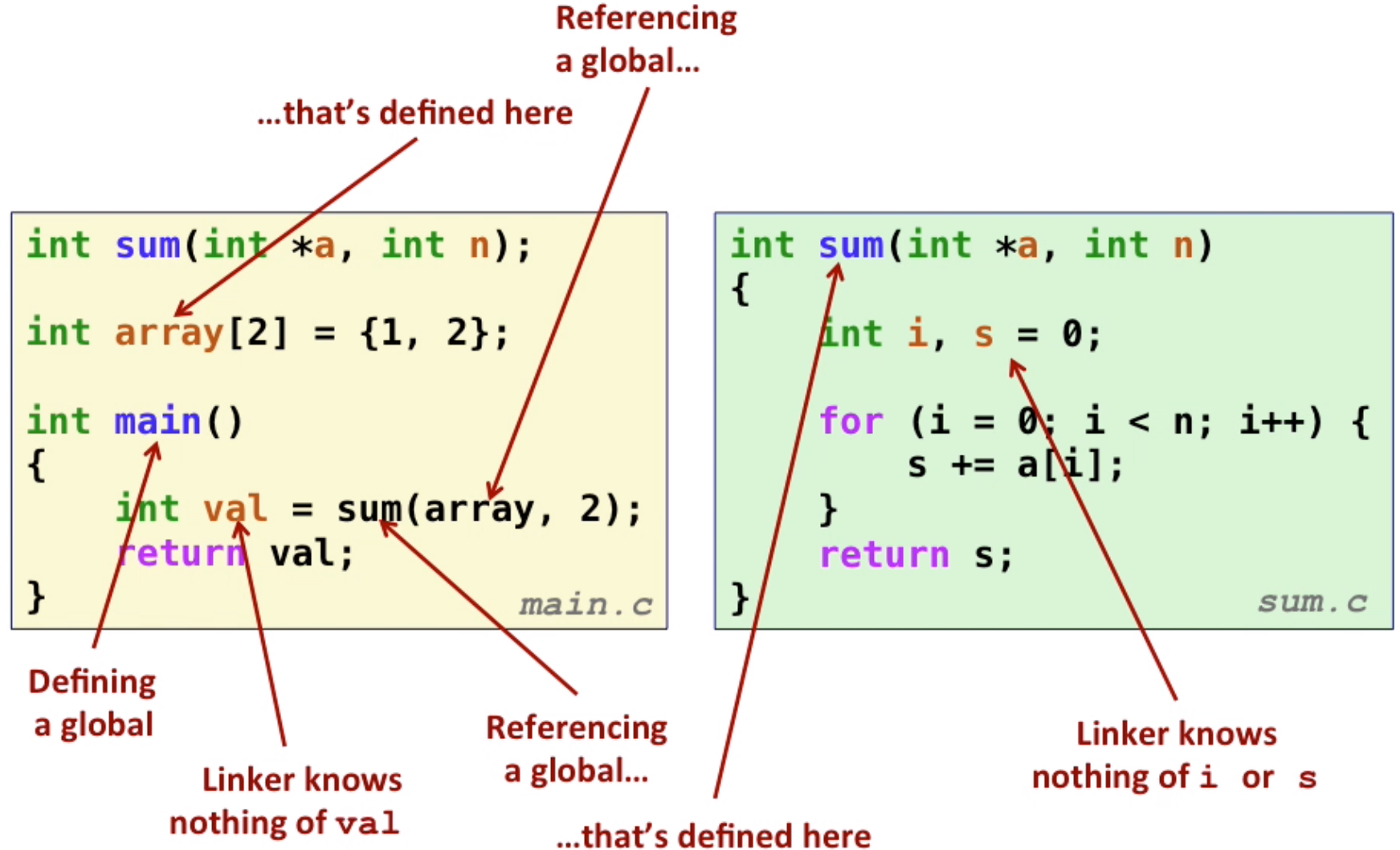
Linker Symbols
- global symbols
- can be referenced by other modules,
non-staticfunctions ornon-staticglobal variables
- can be referenced by other modules,
- external symbols
- global symbols that are referenced by a module but defined by some other modules
- local symbols
- defined and referenced by a module itself
- static C functions and static global variables
- not local program variables(on the stack)
What do linkers do?
step1: Symbol solution
- symbol definitions are stored in object file(by assembler) in
symbol table(array of struct, including name, size and its location) - linker make sure each symbol has exactly one definition
- symbol definitions are stored in object file(by assembler) in
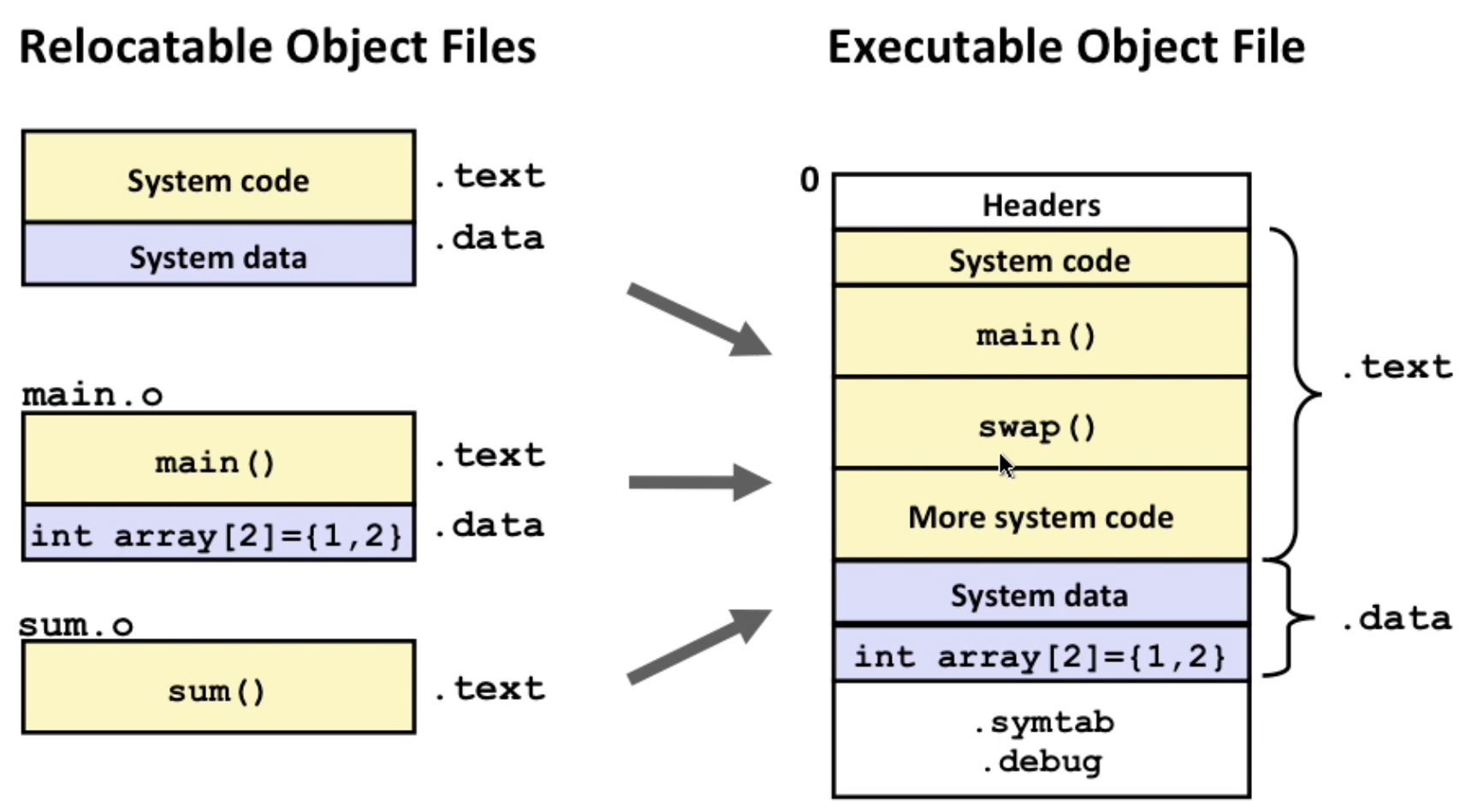
step2: Relocation
- merge separate code and data sections into single sections
- relocate symbols to absolute memory locations
- update references to these symbols
Example step1
- Example step2
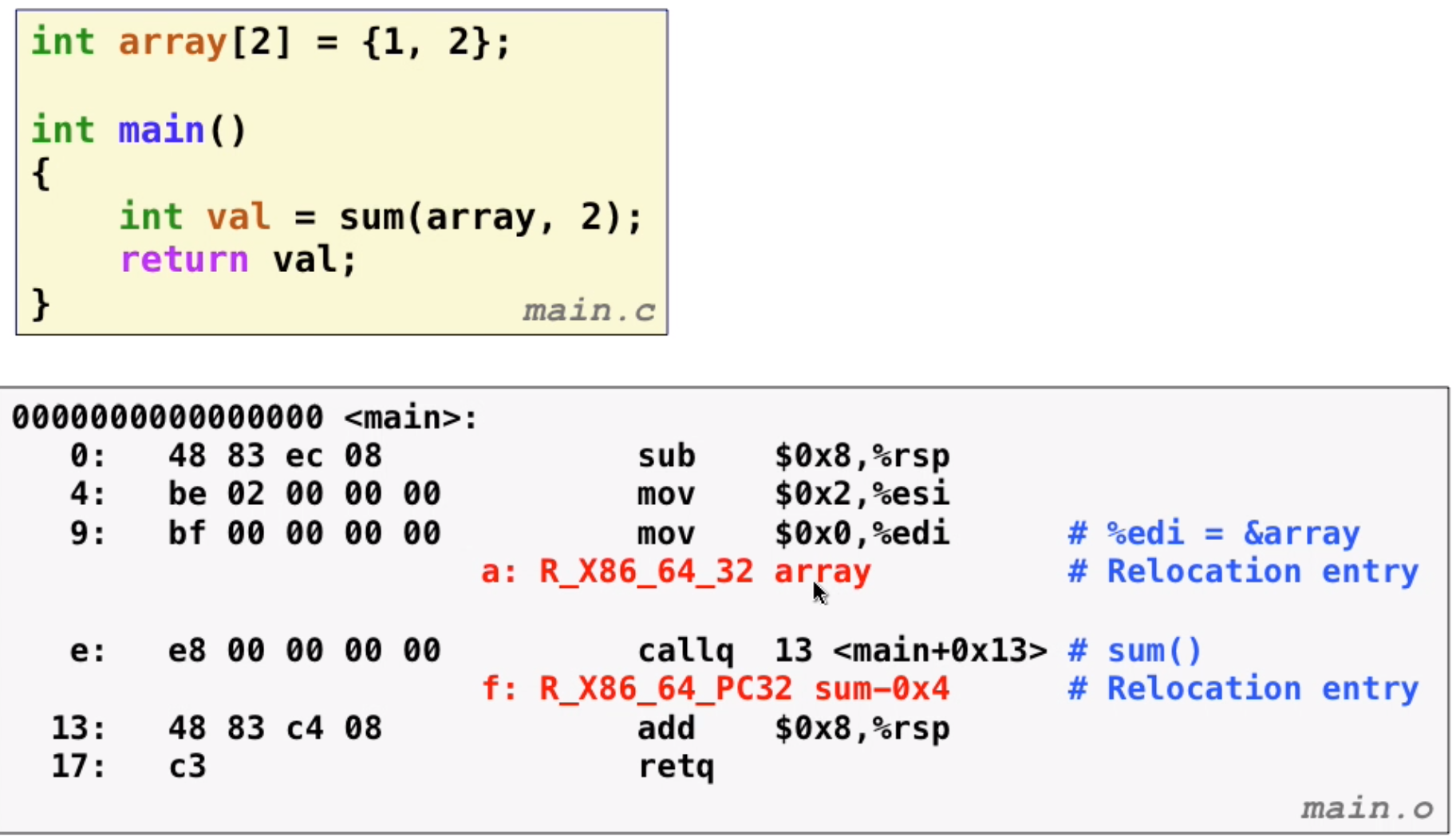
Relocation entries: compiler doesn’t know the location of global variable or functions, so it leaves an entry (offset actually) for linker to use
After relocation:
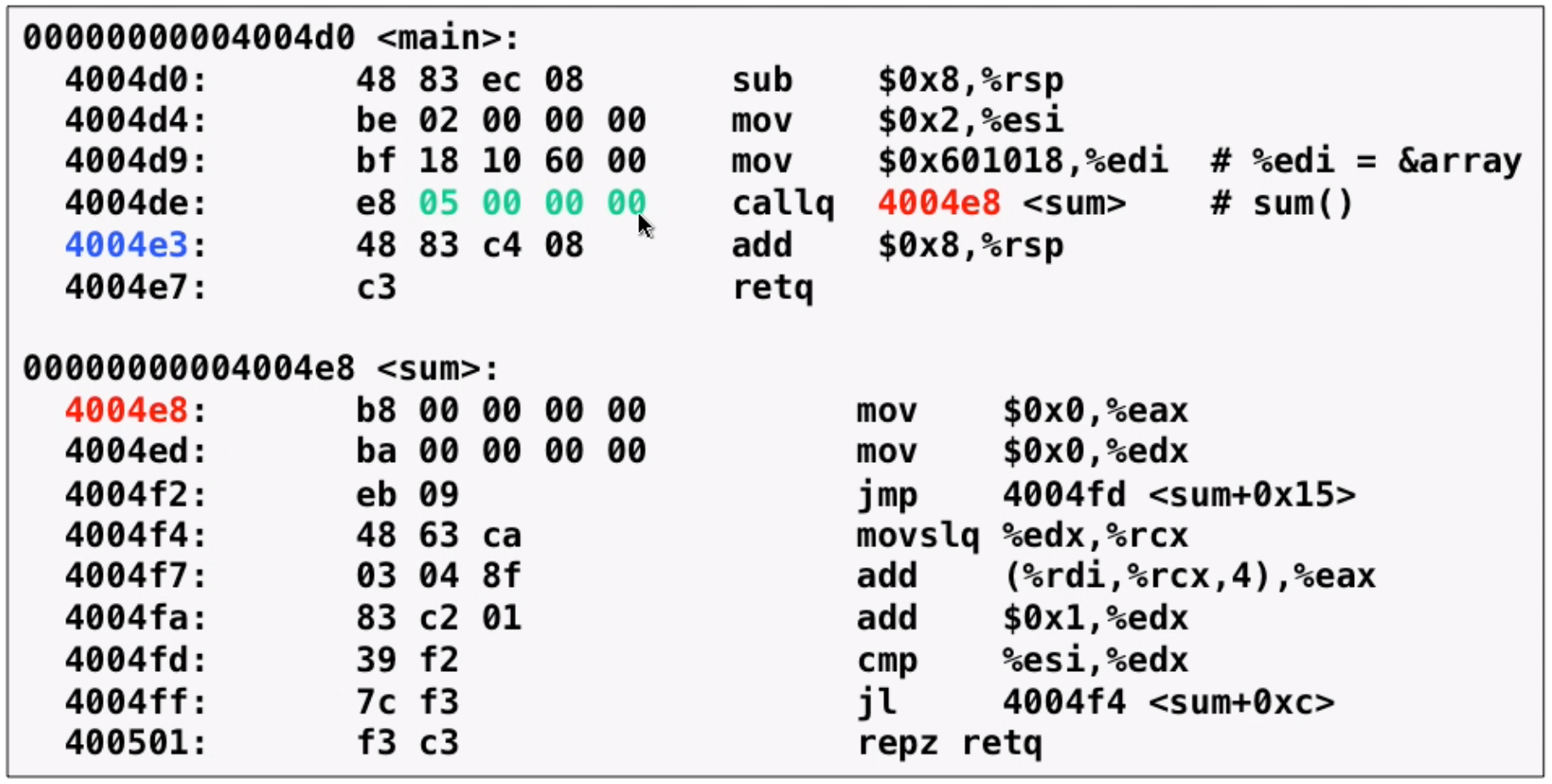
Notice that variable is placed by absolute address and function is placed by PC-relative addressing
Linking puzzle
strong and weak symbols to solve duplicate symbol
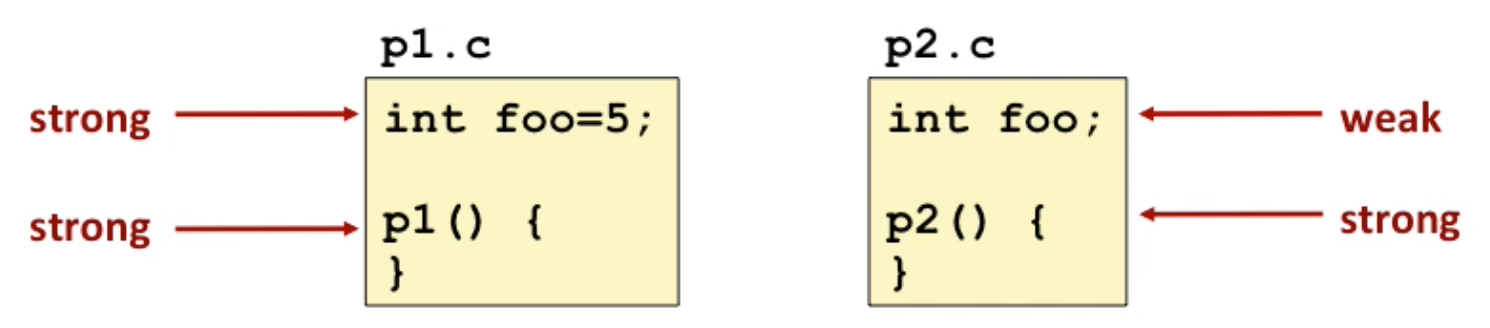
Three principles of compiler:
- Choose strong symbol
- multiple strong symbols are not allowed.
- If there are only multiple weak symbols, pick an arbitrary one. (
-fno-commonto solve arbitrary pick and avoid some errors)
Some linking puzzles:

Explanation of case 2 and 3: the compiler thinks it is double in separate compilation, but it may be int in memory location.
So we should avoid global variables if we can.
Otherwise:
- use
static(make it local symbol) - initialize the global variable
- use
externif you refer an external global variable
Linking in Memory
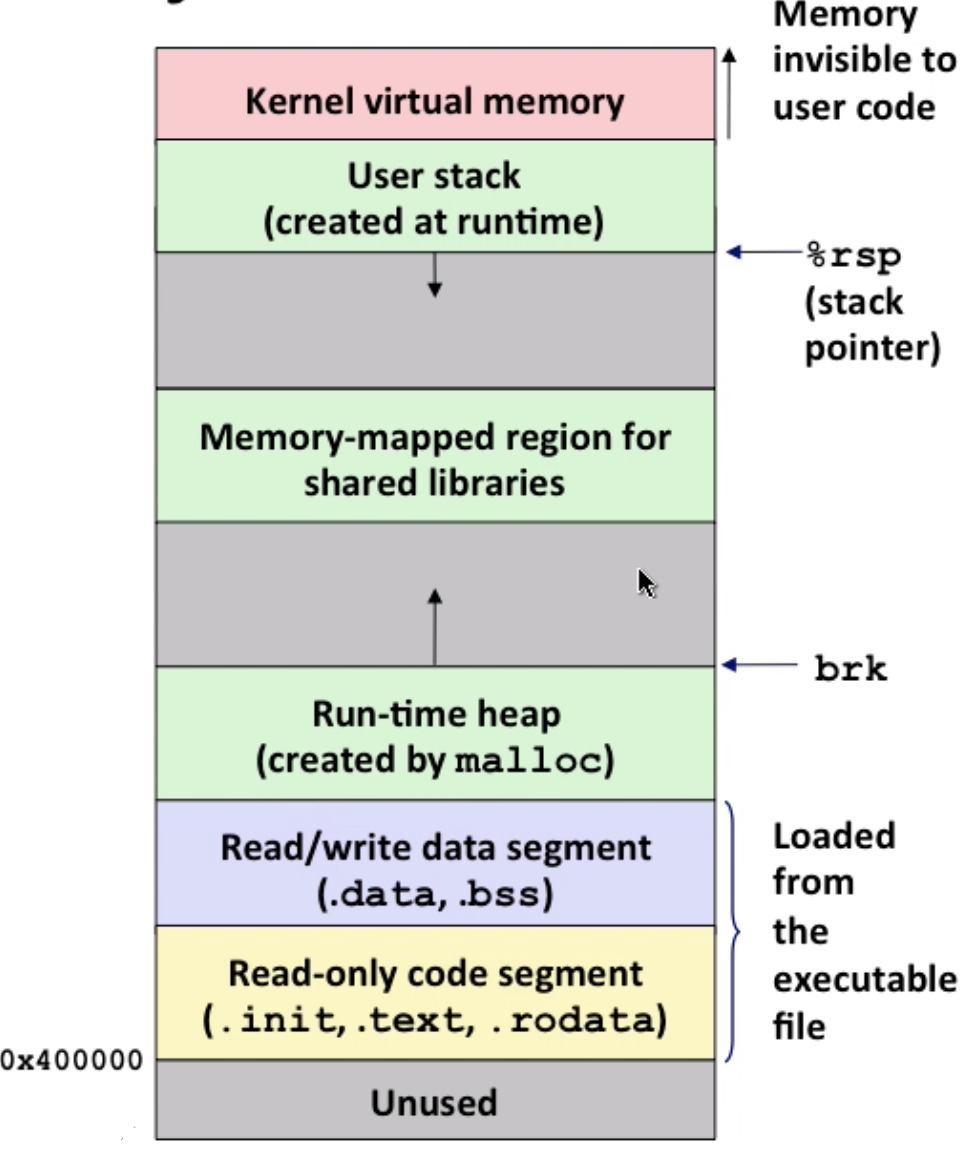
brk: shows the size of heap, when using malloc, you are adjusting brk
Packing commonly used functions (Library)
Static Library
static libraries(.a archive files) – old-fashioned solution
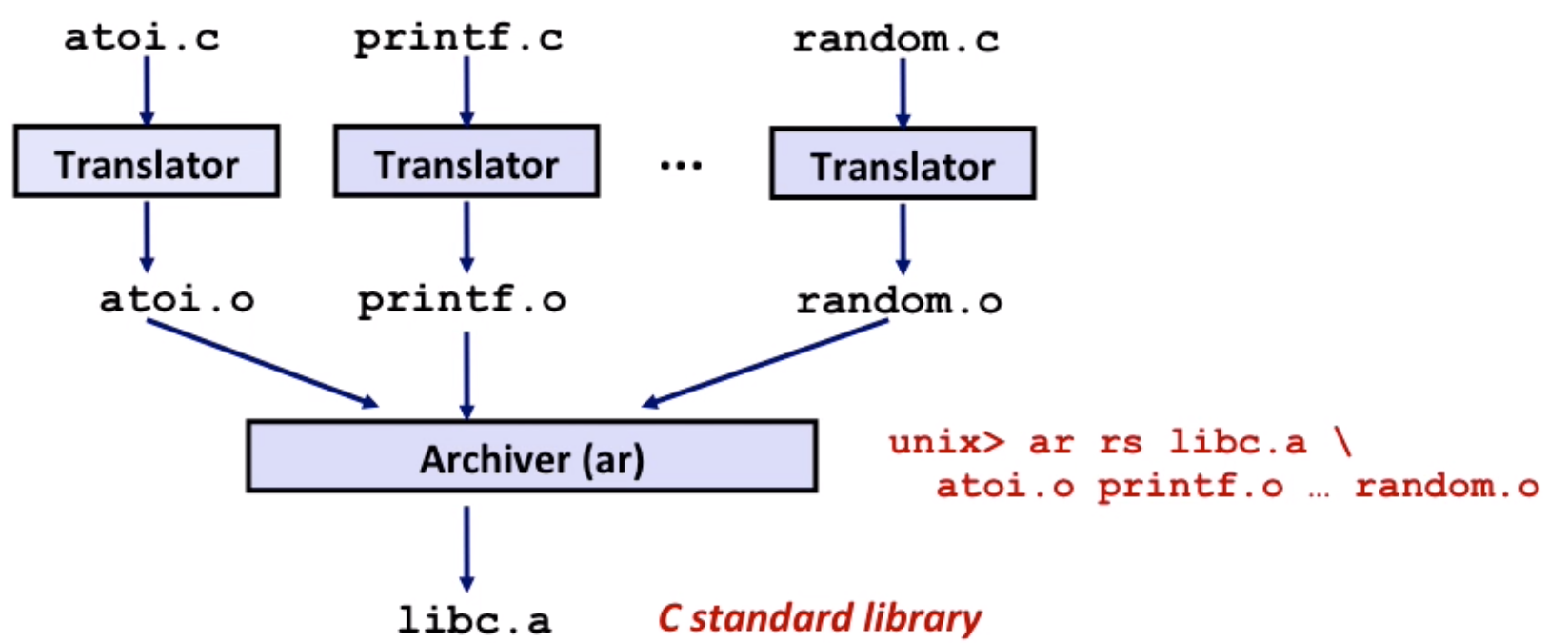
Concatenate related relocatable object files (.o files) into a single file(an
archive)Allows incremental updates
Example:
libc.a(C standard library) – 4.6MB archive of 1496 object filesWhen used, can just choose to pick one
.ofrom an archive, eg.:printf.ofromlibc.aLinker’s algorithm for scanning
- scan
.oand.afiles in the command line order, keeps aunresolved references list - as each new
.oor.afile is encountered, try to resolve each unresolved reference in theunresolved references list - error if any entries in the unresolved list at the end of scan.
- So, the command line order matters

Here libtest.o calls a function defined in -lmine, it’s ok in the first order, but it can’t find it in the reverse order.
Shared Library
shared libraries (.so file) – modern solution
- dynamic linking at load-time:
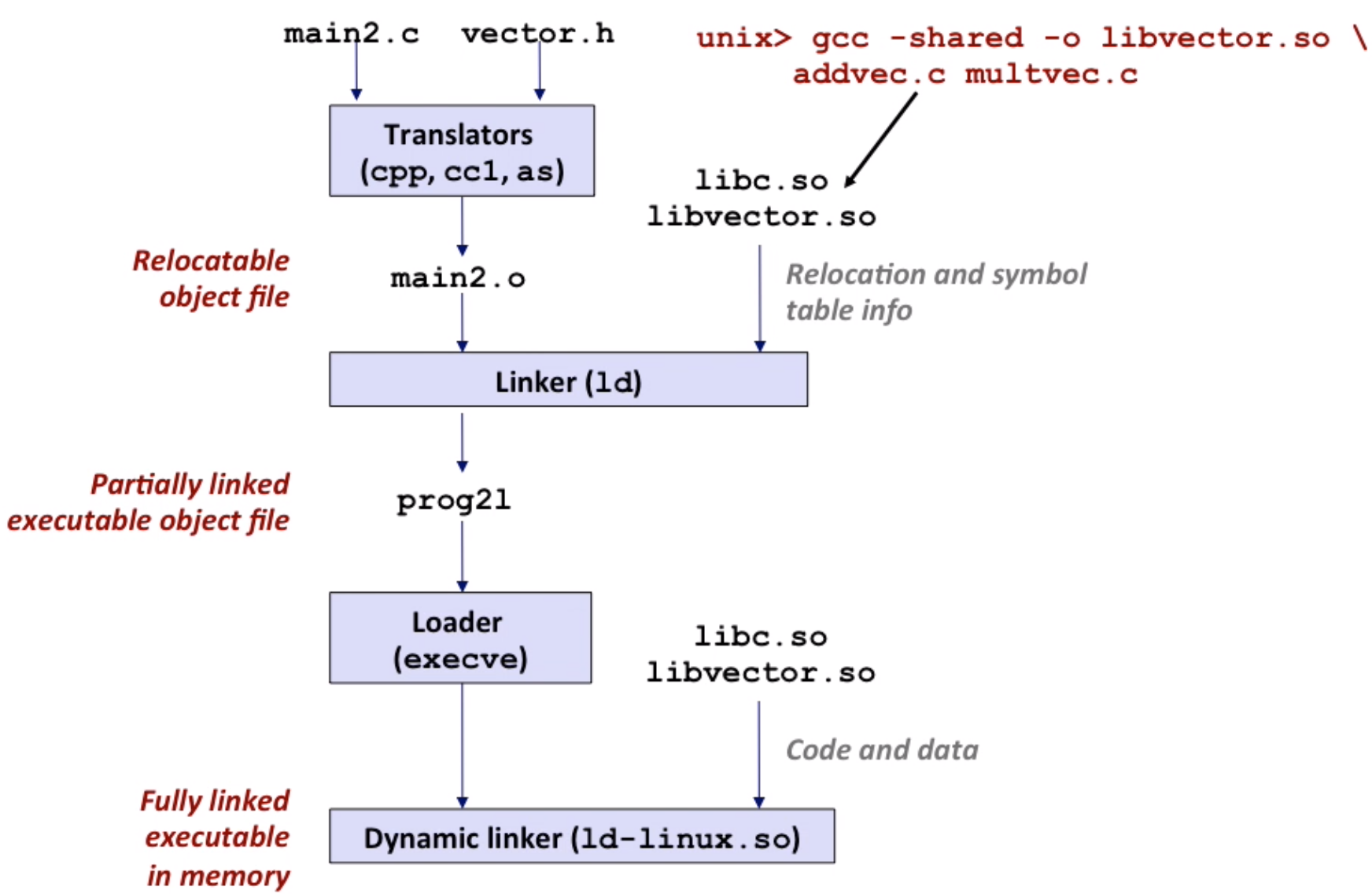
- dynamic linking at run-time by
dlopen,dlsymetc
Library interpositioning
Allow programmers to intercept calls to arbitrary functions, so we can print more information of func calls like malloc or do something extra.
- interpositioning in compile stage
void *mymalloc(size_t size)
{
void *ptr = malloc(size); // call the real malloc
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}
// our own malloc.h
#define malloc(size) mymalloc(size)
#define free(ptr) myfree(ptr)then gcc -I. -o myprog myprog.c mymalloc.c, -I. means find header file first in current work directory
- interpositioning in linking stage
void *__real_malloc(size_t size);
// wrap function
void *__wrap_malloc(size_t size)
{
void *ptr = *__real_malloc(size); // call for real malloc function
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}then gcc -Wl,--wrap,malloc -Wl,--wrap,free -o intl int.o mymalloc.o
-Wl,--wrap,malloc tells compiler that when programmer uses malloc, it calls for __wrap_malloc, and the __real_malloc calls for malloc provided by standard library.
- interpositioning in runtime
/* malloc wrapper function */
void *malloc(size_t size)
{
void *(*mallocp)(size_t size);
char *error;
mallocp = dlsym(RTLD_NEXT, "malloc"); /* Get address of libc malloc */
if ((error = dlerror()) != NULL) {
fputs(error, stderr);
exit(1);
}
char *ptr = mallocp(size); /* Call libc malloc */
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}when runs the program, use LD_PRELOAD="./mymalloc.so" ./intr
LD_PRELOAD environment variable tells the dynamic linker to resolve unresolved refs by looking in mymalloc.so first